 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Guided Diffusion: Visual Conditioning without External Memory
Aug 13, 2025Diffusion models have emerged as a leading framework for high-quality image generation, offering stable training and strong performance across diverse domains. However, they remain computationally intensive, particularly during the iterative denoising process. Latent-space models like Stable Diffusion alleviate some of this cost by operating in compressed representations, though at the expense of fine-grained detail. More recent approaches such as Retrieval-Augmented Diffusion Models (RDM) address efficiency by conditioning denoising on similar examples retrieved from large external memory banks. While effective, these methods introduce drawbacks: they require costly storage and retrieval infrastructure, depend on static vision-language models like CLIP for similarity, and lack adaptability during training. We propose the Prototype Diffusion Model (PDM), a method that integrates prototype learning directly into the diffusion process for efficient and adaptive visual conditioning - without external memory. Instead of retrieving reference samples, PDM constructs a dynamic set of compact visual prototypes from clean image features using contrastive learning. These prototypes guide the denoising steps by aligning noisy representations with semantically relevant visual patterns, enabling efficient generation with strong semantic grounding. Experiments show that PDM maintains high generation quality while reducing computational and storage overhead, offering a scalable alternative to retrieval-based conditioning in diffusion models.
Value-Free Policy Optimization via Reward Partitioning
Jun 16, 2025Single-trajectory reinforcement learning (RL) methods aim to optimize policies from datasets consisting of (prompt, response, reward) triplets, where scalar rewards are directly available. This supervision format is highly practical, as it mirrors real-world human feedback, such as thumbs-up/down signals, and avoids the need for structured preference annotations. In contrast, pairwise preference-based methods like Direct Preference Optimization (DPO) rely on datasets with both preferred and dispreferred responses, which are harder to construct and less natural to collect. Among single-trajectory approaches, Direct Reward Optimization (DRO) has shown strong empirical performance due to its simplicity and stability. However, DRO requires approximating a value function, which introduces several limitations: high off-policy variance, coupling between policy and value learning, and a lack of absolute supervision on the policy itself. We introduce Reward Partitioning Optimization (RPO), a new method that resolves these limitations by removing the need to model the value function. Instead, RPO normalizes observed rewards using a partitioning approach estimated directly from data. This leads to a straightforward supervised learning objective on the policy, with no auxiliary models and no joint optimization. RPO provides direct and stable supervision on the policy, making it robust and easy to implement in practice. We validate RPO on scalar-feedback language modeling tasks using Flan-T5 encoder-decoder models. Our results demonstrate that RPO outperforms existing single-trajectory baselines such as DRO and Kahneman-Tversky Optimization (KTO). These findings confirm that RPO is a simple, effective, and theoretically grounded method for single-trajectory policy optimization.
MB-ORES: A Multi-Branch Object Reasoner for Visual Grounding in Remote Sensing
Mar 31, 2025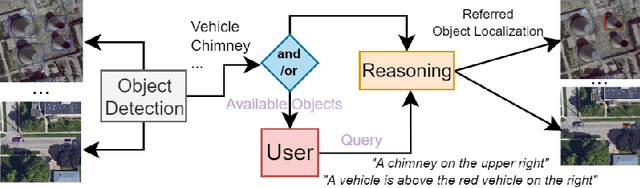
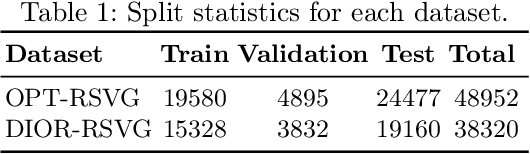
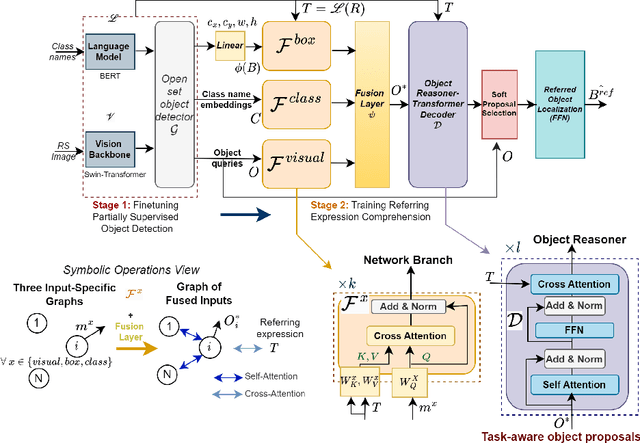

We propose a unified framework that integrates object detection (OD) and visual grounding (VG) for remote sensing (RS) imagery. To support conventional OD and establish an intuitive prior for VG task, we fine-tune an open-set object detector using referring expression data, framing it as a partially supervised OD task. In the first stage, we construct a graph representation of each image, comprising object queries, class embeddings, and proposal locations. Then, our task-aware architecture processes this graph to perform the VG task. The model consists of: (i) a multi-branch network that integrates spatial, visual, and categorical features to generate task-aware proposals, and (ii) an object reasoning network that assigns probabilities across proposals, followed by a soft selection mechanism for final referring object localization. Our model demonstrates superior performance on the OPT-RSVG and DIOR-RSVG datasets, achieving significant improvements over state-of-the-art methods while retaining classical OD capabilities. The code will be available in our repository: \url{https://github.com/rd20karim/MB-ORES}.
Game Theory Meets Statistical Mechanics in Deep Learning Design
Oct 16, 2024We present a novel deep graphical representation that seamlessly merges principles of game theory with laws of statistical mechanics. It performs feature extraction, dimensionality reduction, and pattern classification within a single learning framework. Our approach draws an analogy between neurons in a network and players in a game theory model. Furthermore, each neuron viewed as a classical particle (subject to statistical physics' laws) is mapped to a set of actions representing specific activation value, and neural network layers are conceptualized as games in a sequential cooperative game theory setting. The feed-forward process in deep learning is interpreted as a sequential game, where each game comprises a set of players. During training, neurons are iteratively evaluated and filtered based on their contributions to a payoff function, which is quantified using the Shapley value driven by an energy function. Each set of neurons that significantly contributes to the payoff function forms a strong coalition. These neurons are the only ones permitted to propagate the information forward to the next layers. We applied this methodology to the task of facial age estimation and gender classification. Experimental results demonstrate that our approach outperforms both multi-layer perceptron and convolutional neural network models in terms of efficiency and accuracy.
OneEncoder: A Lightweight Framework for Progressive Alignment of Modalities
Sep 18, 2024Cross-modal alignment Learning integrates information from different modalities like text, image, audio and video to create unified models. This approach develops shared representations and learns correlations between modalities, enabling applications such as visual question answering and audiovisual content analysis. Current techniques rely on large modality-specific encoders, necessitating fine-tuning or training from scratch on vast aligned datasets (e.g., text-image, text-audio, image-audio). This approach has limitations: (i) it is very expensive due to the need for training large encoders on extensive datasets, (ii) acquiring aligned large paired datasets is challenging, and (iii) adding new modalities requires retraining the entire framework to incorporate these modalities. To address these issues, we propose OneEncoder, a lightweight framework that progressively represents and aligns four modalities (image, text, audio, video). Initially, we train a lightweight Universal Projection module (UP) to align image and text modalities. Then, we freeze the pretrained UP and progressively align future modalities to those already aligned. OneEncoder operates efficiently and cost-effectively, even in scenarios where vast aligned datasets are unavailable, due to its lightweight design. Trained on small paired datasets, it shows strong performance in tasks like classification, querying, and visual question answering, surpassing methods that rely on large datasets and specialized encoders.
Unsupervised Adaptive Normalization
Sep 07, 2024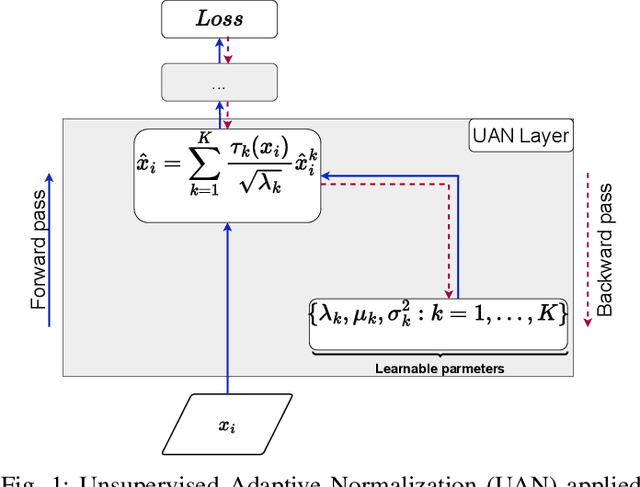
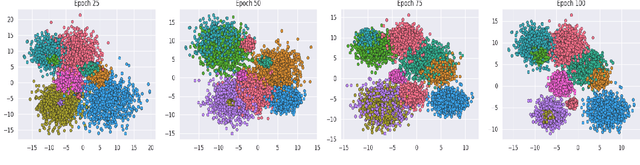
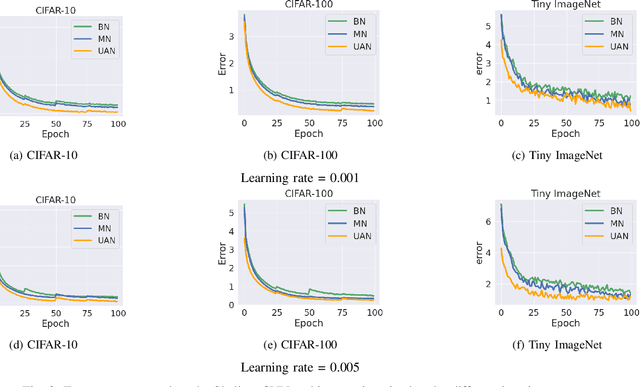
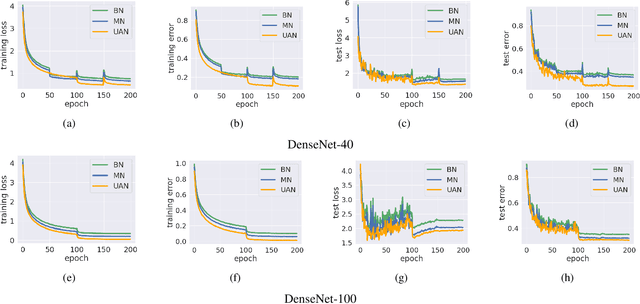
Deep neural networks have become a staple in solving intricate problems, proving their mettle in a wide array of applications. However, their training process is often hampered by shifting activation distributions during backpropagation, resulting in unstable gradients. Batch Normalization (BN) addresses this issue by normalizing activations, which allows for the use of higher learning rates. Despite its benefits, BN is not without drawbacks, including its dependence on mini-batch size and the presumption of a uniform distribution of samples. To overcome this, several alternatives have been proposed, such as Layer Normalization, Group Normalization, and Mixture Normalization. These methods may still struggle to adapt to the dynamic distributions of neuron activations during the learning process. To bridge this gap, we introduce Unsupervised Adaptive Normalization (UAN), an innovative algorithm that seamlessly integrates clustering for normalization with deep neural network learning in a singular process. UAN executes clustering using the Gaussian mixture model, determining parameters for each identified cluster, by normalizing neuron activations. These parameters are concurrently updated as weights in the deep neural network, aligning with the specific requirements of the target task during backpropagation. This unified approach of clustering and normalization, underpinned by neuron activation normalization, fosters an adaptive data representation that is specifically tailored to the target task. This adaptive feature of UAN enhances gradient stability, resulting in faster learning and augmented neural network performance. UAN outperforms the classical methods by adapting to the target task and is effective in classification, and domain adaptation.
* arXiv admin note: text overlap with arXiv:2403.16798
Adaptative Context Normalization: A Boost for Deep Learning in Image Processing
Sep 07, 2024Deep Neural network learning for image processing faces major challenges related to changes in distribution across layers, which disrupt model convergence and performance. Activation normalization methods, such as Batch Normalization (BN), have revolutionized this field, but they rely on the simplified assumption that data distribution can be modelled by a single Gaussian distribution. To overcome these limitations, Mixture Normalization (MN) introduced an approach based on a Gaussian Mixture Model (GMM), assuming multiple components to model the data. However, this method entails substantial computational requirements associated with the use of Expectation-Maximization algorithm to estimate parameters of each Gaussian components. To address this issue, we introduce Adaptative Context Normalization (ACN), a novel supervised approach that introduces the concept of "context", which groups together a set of data with similar characteristics. Data belonging to the same context are normalized using the same parameters, enabling local representation based on contexts. For each context, the normalized parameters, as the model weights are learned during the backpropagation phase. ACN not only ensures speed, convergence, and superior performance compared to BN and MN but also presents a fresh perspective that underscores its particular efficacy in the field of image processing.
* arXiv admin note: text overlap with arXiv:2403.16798
LightMDETR: A Lightweight Approach for Low-Cost Open-Vocabulary Object Detection Training
Aug 20, 2024



Object detection in computer vision traditionally involves identifying objects in images. By integrating textual descriptions, we enhance this process, providing better context and accuracy. The MDETR model significantly advances this by combining image and text data for more versatile object detection and classification. However, MDETR's complexity and high computational demands hinder its practical use. In this paper, we introduce Lightweight MDETR (LightMDETR), an optimized MDETR variant designed for improved computational efficiency while maintaining robust multimodal capabilities. Our approach involves freezing the MDETR backbone and training a sole component, the Deep Fusion Encoder (DFE), to represent image and text modalities. A learnable context vector enables the DFE to switch between these modalities. Evaluation on datasets like RefCOCO, RefCOCO+, and RefCOCOg demonstrates that LightMDETR achieves superior precision and accuracy.
Supervised Batch Normalization
May 27, 2024



Batch Normalization (BN), a widely-used technique in neural networks, enhances generalization and expedites training by normalizing each mini-batch to the same mean and variance. However, its effectiveness diminishes when confronted with diverse data distributions. To address this challenge, we propose Supervised Batch Normalization (SBN), a pioneering approach. We expand normalization beyond traditional single mean and variance parameters, enabling the identification of data modes prior to training. This ensures effective normalization for samples sharing common features. We define contexts as modes, categorizing data with similar characteristics. These contexts are explicitly defined, such as domains in domain adaptation or modalities in multimodal systems, or implicitly defined through clustering algorithms based on data similarity. We illustrate the superiority of our approach over BN and other commonly employed normalization techniques through various experiments on both single and multi-task datasets. Integrating SBN with Vision Transformer results in a remarkable \textit{15.13}\% accuracy enhancement on CIFAR-100. Additionally, in domain adaptation scenarios, employing AdaMatch demonstrates an impressive \textit{22.25}\% accuracy improvement on MNIST and SVHN compared to BN.
Cluster-Based Normalization Layer for Neural Networks
Mar 25, 2024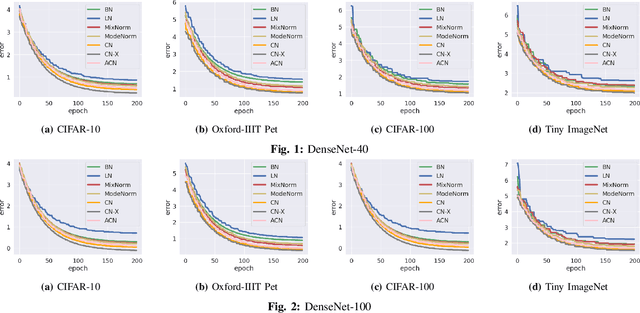
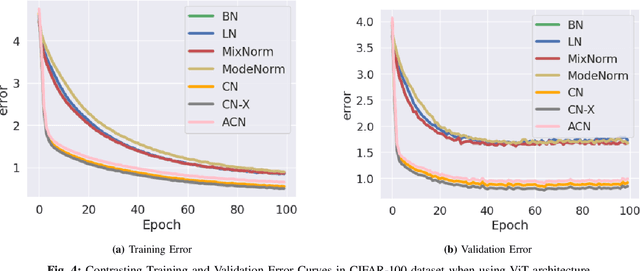
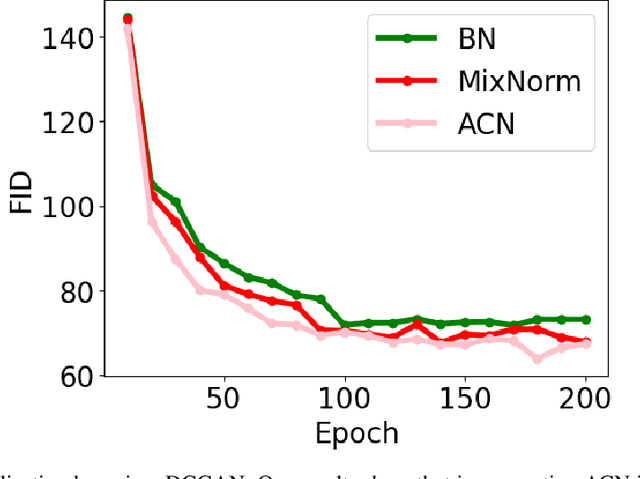

Deep learning faces significant challenges during the training of neural networks, including internal covariate shift, label shift, vanishing/exploding gradients, overfitting, and computational complexity. While conventional normalization methods, such as Batch Normalization, aim to tackle some of these issues, they often depend on assumptions that constrain their adaptability. Mixture Normalization faces computational hurdles in its pursuit of handling multiple Gaussian distributions. This paper introduces Cluster-Based Normalization (CB-Norm) in two variants - Supervised Cluster-Based Normalization (SCB-Norm) and Unsupervised Cluster-Based Normalization (UCB-Norm) - proposing a groundbreaking one-step normalization approach. CB-Norm leverages a Gaussian mixture model to specifically address challenges related to gradient stability and learning acceleration. For SCB-Norm, a supervised variant, the novel mechanism involves introducing predefined data partitioning, termed clusters, to normalize activations based on the assigned cluster. This cluster-driven approach creates a space that conforms to a Gaussian mixture model. On the other hand, UCB-Norm, an unsupervised counterpart, dynamically clusters neuron activations during training, adapting to task-specific challenges without relying on predefined data partitions (clusters). This dual approach ensures flexibility in addressing diverse learning scenarios. CB-Norm innovatively uses a one-step normalization approach, where parameters of each mixture component (cluster in activation space) serve as weights for deep neural networks. This adaptive clustering process tackles both clustering and resolution of deep neural network tasks concurrently during training, signifying a notable advancement in the field.