 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Based Normalization Layer for Neural Networks
Paper and Code
Mar 25, 2024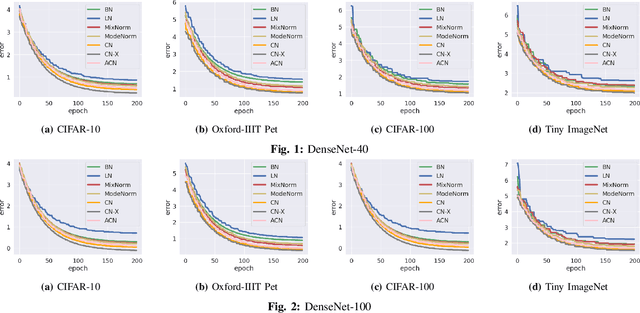
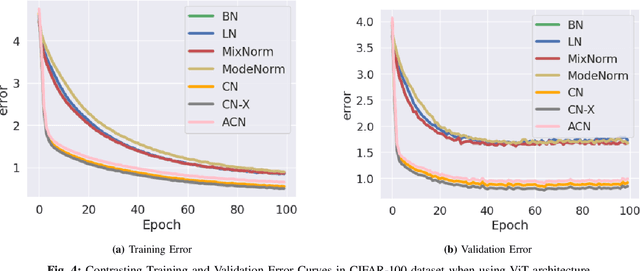
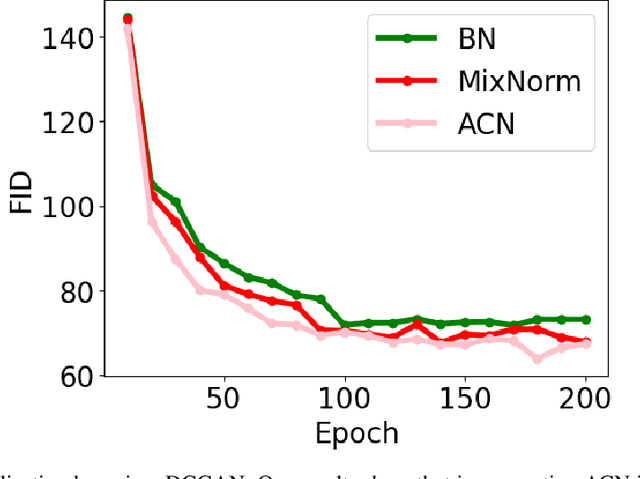

Deep learning faces significant challenges during the training of neural networks, including internal covariate shift, label shift, vanishing/exploding gradients, overfitting, and computational complexity. While conventional normalization methods, such as Batch Normalization, aim to tackle some of these issues, they often depend on assumptions that constrain their adaptability. Mixture Normalization faces computational hurdles in its pursuit of handling multiple Gaussian distributions. This paper introduces Cluster-Based Normalization (CB-Norm) in two variants - Supervised Cluster-Based Normalization (SCB-Norm) and Unsupervised Cluster-Based Normalization (UCB-Norm) - proposing a groundbreaking one-step normalization approach. CB-Norm leverages a Gaussian mixture model to specifically address challenges related to gradient stability and learning acceleration. For SCB-Norm, a supervised variant, the novel mechanism involves introducing predefined data partitioning, termed clusters, to normalize activations based on the assigned cluster. This cluster-driven approach creates a space that conforms to a Gaussian mixture model. On the other hand, UCB-Norm, an unsupervised counterpart, dynamically clusters neuron activations during training, adapting to task-specific challenges without relying on predefined data partitions (clusters). This dual approach ensures flexibility in addressing diverse learning scenarios. CB-Norm innovatively uses a one-step normalization approach, where parameters of each mixture component (cluster in activation space) serve as weights for deep neural networks. This adaptive clustering process tackles both clustering and resolution of deep neural network tasks concurrently during training, signifying a notable advancement in the field.