 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMB-ORES: A Multi-Branch Object Reasoner for Visual Grounding in Remote Sensing
Mar 31, 2025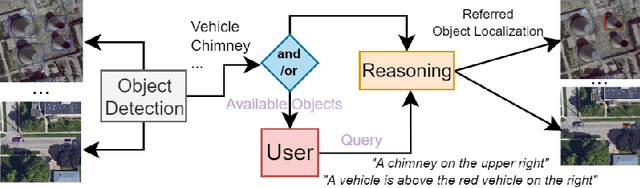
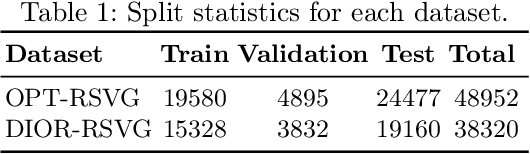
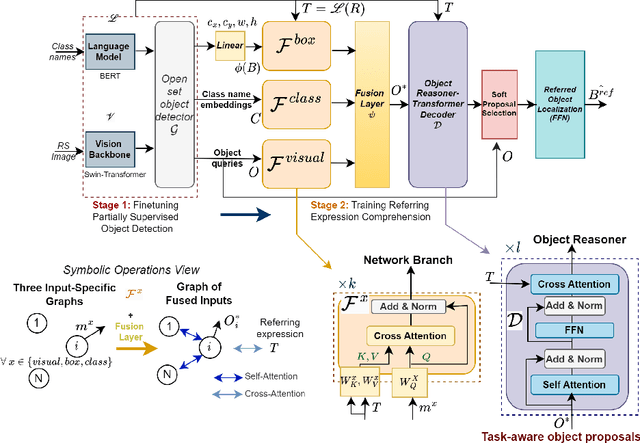

We propose a unified framework that integrates object detection (OD) and visual grounding (VG) for remote sensing (RS) imagery. To support conventional OD and establish an intuitive prior for VG task, we fine-tune an open-set object detector using referring expression data, framing it as a partially supervised OD task. In the first stage, we construct a graph representation of each image, comprising object queries, class embeddings, and proposal locations. Then, our task-aware architecture processes this graph to perform the VG task. The model consists of: (i) a multi-branch network that integrates spatial, visual, and categorical features to generate task-aware proposals, and (ii) an object reasoning network that assigns probabilities across proposals, followed by a soft selection mechanism for final referring object localization. Our model demonstrates superior performance on the OPT-RSVG and DIOR-RSVG datasets, achieving significant improvements over state-of-the-art methods while retaining classical OD capabilities. The code will be available in our repository: \url{https://github.com/rd20karim/MB-ORES}.
Transformer with Controlled Attention for Synchronous Motion Captioning
Sep 13, 2024In this paper, we address a challenging task, synchronous motion captioning, that aim to generate a language description synchronized with human motion sequences. This task pertains to numerous applications, such as aligned sign language transcription, unsupervised action segmentation and temporal grounding. Our method introduces mechanisms to control self- and cross-attention distributions of the Transformer, allowing interpretability and time-aligned text generation. We achieve this through masking strategies and structuring losses that push the model to maximize attention only on the most important frames contributing to the generation of a motion word. These constraints aim to prevent undesired mixing of information in attention maps and to provide a monotonic attention distribution across tokens. Thus, the cross attentions of tokens are used for progressive text generation in synchronization with human motion sequences. We demonstrate the superior performance of our approach through evaluation on the two available benchmark datasets, KIT-ML and HumanML3D. As visual evaluation is essential for this task, we provide a comprehensive set of animated visual illustrations in the code repository: https://github.com/rd20karim/Synch-Transformer.
Motion2Language, Unsupervised learning of synchronized semantic motion segmentation
Oct 16, 2023In this paper, we investigate building a sequence to sequence architecture for motion to language translation and synchronization. The aim is to translate motion capture inputs into English natural-language descriptions, such that the descriptions are generated synchronously with the actions performed, enabling semantic segmentation as a byproduct, but without requiring synchronized training data. We propose a new recurrent formulation of local attention that is suited for synchronous/live text generation, as well as an improved motion encoder architecture better suited to smaller data and for synchronous generation. We evaluate both contributions in individual experiments, using the standard BLEU4 metric, as well as a simple semantic equivalence measure, on the KIT motion language dataset. In a follow-up experiment, we assess the quality of the synchronization of generated text in our proposed approaches through multiple evaluation metrics. We find that both contributions to the attention mechanism and the encoder architecture additively improve the quality of generated text (BLEU and semantic equivalence), but also of synchronization. Our code will be made available at \url{https://github.com/rd20karim/M2T-Segmentation/tree/main}
Guided Attention for Interpretable Motion Captioning
Oct 11, 2023



While much effort has been invested in generating human motion from text, relatively few studies have been dedicated to the reverse direction, that is, generating text from motion. Much of the research focuses on maximizing generation quality without any regard for the interpretability of the architectures, particularly regarding the influence of particular body parts in the generation and the temporal synchronization of words with specific movements and actions. This study explores the combination of movement encoders with spatio-temporal attention models and proposes strategies to guide the attention during training to highlight perceptually pertinent areas of the skeleton in time. We show that adding guided attention with adaptive gate leads to interpretable captioning while improving performance compared to higher parameter-count non-interpretable SOTA systems. On the KIT MLD dataset, we obtain a BLEU@4 of 24.4% (SOTA+6%), a ROUGE-L of 58.30% (SOTA +14.1%), a CIDEr of 112.10 (SOTA +32.6) and a Bertscore of 41.20% (SOTA +18.20%). On HumanML3D, we obtain a BLEU@4 of 25.00 (SOTA +2.7%), a ROUGE-L score of 55.4% (SOTA +6.1%), a CIDEr of 61.6 (SOTA -10.9%), a Bertscore of 40.3% (SOTA +2.5%). Our code implementation and reproduction details will be soon available at https://github.com/rd20karim/M2T-Interpretable/tree/main.