 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer with Controlled Attention for Synchronous Motion Captioning
Sep 13, 2024In this paper, we address a challenging task, synchronous motion captioning, that aim to generate a language description synchronized with human motion sequences. This task pertains to numerous applications, such as aligned sign language transcription, unsupervised action segmentation and temporal grounding. Our method introduces mechanisms to control self- and cross-attention distributions of the Transformer, allowing interpretability and time-aligned text generation. We achieve this through masking strategies and structuring losses that push the model to maximize attention only on the most important frames contributing to the generation of a motion word. These constraints aim to prevent undesired mixing of information in attention maps and to provide a monotonic attention distribution across tokens. Thus, the cross attentions of tokens are used for progressive text generation in synchronization with human motion sequences. We demonstrate the superior performance of our approach through evaluation on the two available benchmark datasets, KIT-ML and HumanML3D. As visual evaluation is essential for this task, we provide a comprehensive set of animated visual illustrations in the code repository: https://github.com/rd20karim/Synch-Transformer.
Motion2Language, Unsupervised learning of synchronized semantic motion segmentation
Oct 16, 2023In this paper, we investigate building a sequence to sequence architecture for motion to language translation and synchronization. The aim is to translate motion capture inputs into English natural-language descriptions, such that the descriptions are generated synchronously with the actions performed, enabling semantic segmentation as a byproduct, but without requiring synchronized training data. We propose a new recurrent formulation of local attention that is suited for synchronous/live text generation, as well as an improved motion encoder architecture better suited to smaller data and for synchronous generation. We evaluate both contributions in individual experiments, using the standard BLEU4 metric, as well as a simple semantic equivalence measure, on the KIT motion language dataset. In a follow-up experiment, we assess the quality of the synchronization of generated text in our proposed approaches through multiple evaluation metrics. We find that both contributions to the attention mechanism and the encoder architecture additively improve the quality of generated text (BLEU and semantic equivalence), but also of synchronization. Our code will be made available at \url{https://github.com/rd20karim/M2T-Segmentation/tree/main}
Guided Attention for Interpretable Motion Captioning
Oct 11, 2023



While much effort has been invested in generating human motion from text, relatively few studies have been dedicated to the reverse direction, that is, generating text from motion. Much of the research focuses on maximizing generation quality without any regard for the interpretability of the architectures, particularly regarding the influence of particular body parts in the generation and the temporal synchronization of words with specific movements and actions. This study explores the combination of movement encoders with spatio-temporal attention models and proposes strategies to guide the attention during training to highlight perceptually pertinent areas of the skeleton in time. We show that adding guided attention with adaptive gate leads to interpretable captioning while improving performance compared to higher parameter-count non-interpretable SOTA systems. On the KIT MLD dataset, we obtain a BLEU@4 of 24.4% (SOTA+6%), a ROUGE-L of 58.30% (SOTA +14.1%), a CIDEr of 112.10 (SOTA +32.6) and a Bertscore of 41.20% (SOTA +18.20%). On HumanML3D, we obtain a BLEU@4 of 25.00 (SOTA +2.7%), a ROUGE-L score of 55.4% (SOTA +6.1%), a CIDEr of 61.6 (SOTA -10.9%), a Bertscore of 40.3% (SOTA +2.5%). Our code implementation and reproduction details will be soon available at https://github.com/rd20karim/M2T-Interpretable/tree/main.
Improving Patent Mining and Relevance Classification using Transformers
May 09, 2021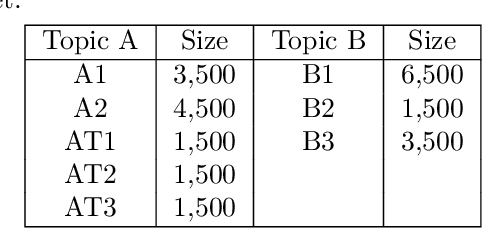

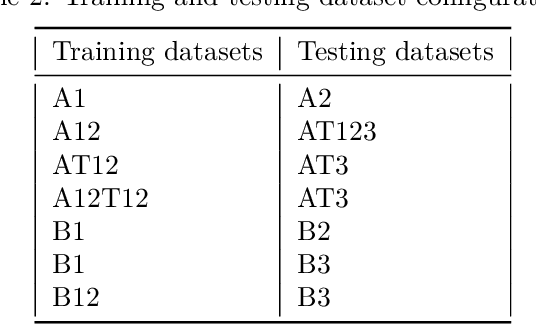
Patent analysis and mining are time-consuming and costly processes for companies, but nevertheless essential if they are willing to remain competitive. To face the overload induced by numerous patents, the idea is to automatically filter them, bringing only few to read to experts. This paper reports a successful application of fine-tuning and retraining on pre-trained deep Natural Language Processing models on patent classification. The solution that we propose combines several state-of-the-art treatments to achieve our goal - decrease the workload while preserving recall and precision metrics.
A Benchmarking on Cloud based Speech-To-Text Services for French Speech and Background Noise Effect
May 07, 2021
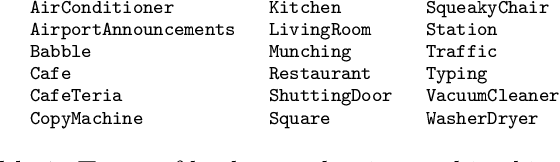
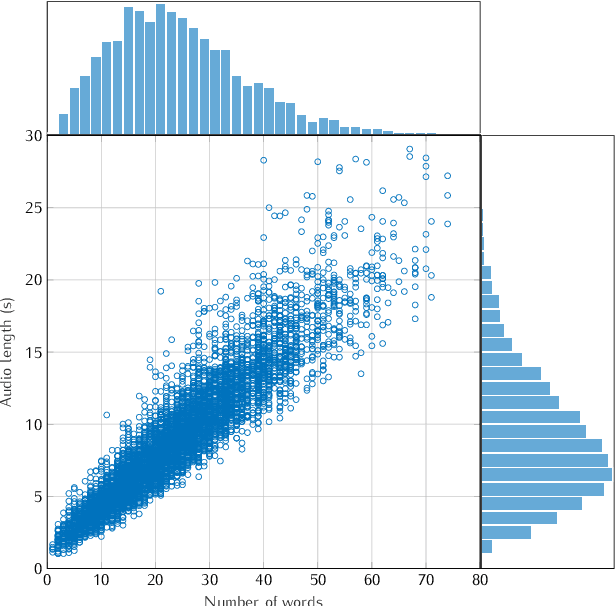
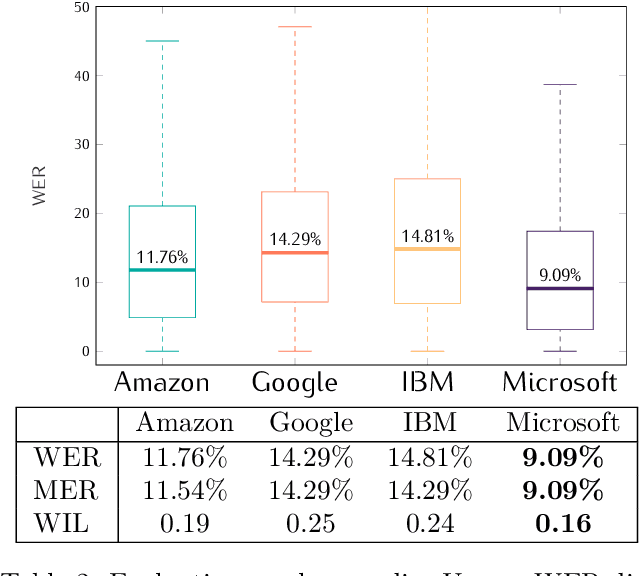
This study presents a large scale benchmarking on cloud based Speech-To-Text systems: {Google Cloud Speech-To-Text}, {Microsoft Azure Cognitive Services}, {Amazon Transcribe}, {IBM Watson Speech to Text}. For each systems, 40158 clean and noisy speech files about 101 hours are tested. Effect of background noise on STT quality is also evaluated with 5 different Signal-to-noise ratios from 40dB to 0dB. Results showed that {Microsoft Azure} provided lowest transcription error rate $9.09\%$ on clean speech, with high robustness to noisy environment. {Google Cloud} and {Amazon Transcribe} gave similar performance, but the latter is very limited for time-constraint usage. Though {IBM Watson} could work correctly in quiet conditions, it is highly sensible to noisy speech which could strongly limit its application in real life situations.
Semantic Similarity from Natural Language and Ontology Analysis
Apr 18, 2017
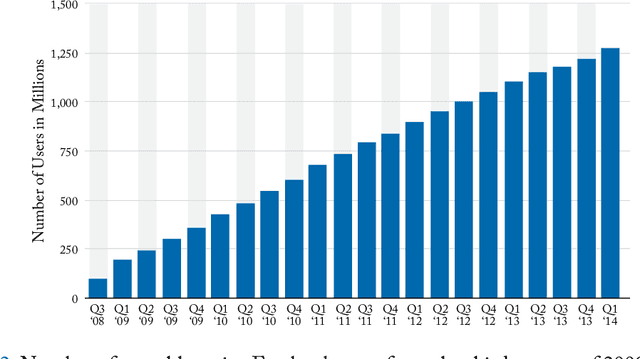
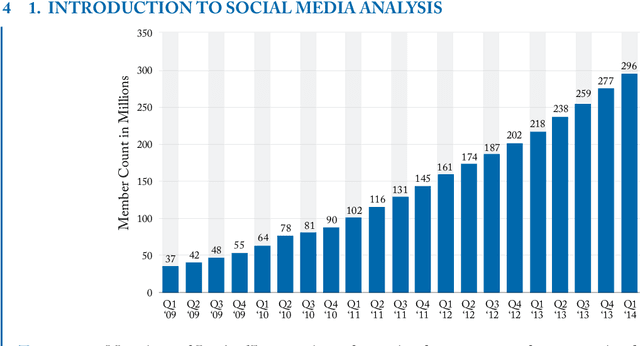
Artificial Intelligence federates numerous scientific fields in the aim of developing machines able to assist human operators performing complex treatments -- most of which demand high cognitive skills (e.g. learning or decision processes). Central to this quest is to give machines the ability to estimate the likeness or similarity between things in the way human beings estimate the similarity between stimuli. In this context, this book focuses on semantic measures: approaches designed for comparing semantic entities such as units of language, e.g. words, sentences, or concepts and instances defined into knowledge bases. The aim of these measures is to assess the similarity or relatedness of such semantic entities by taking into account their semantics, i.e. their meaning -- intuitively, the words tea and coffee, which both refer to stimulating beverage, will be estimated to be more semantically similar than the words toffee (confection) and coffee, despite that the last pair has a higher syntactic similarity. The two state-of-the-art approaches for estimating and quantifying semantic similarities/relatedness of semantic entities are presented in detail: the first one relies on corpora analysis and is based on Natural Language Processing techniques and semantic models while the second is based on more or less formal, computer-readable and workable forms of knowledge such as semantic networks, thesaurus or ontologies. (...) Beyond a simple inventory and categorization of existing measures, the aim of this monograph is to convey novices as well as researchers of these domains towards a better understanding of semantic similarity estimation and more generally semantic measures.
Semantic Measures for the Comparison of Units of Language, Concepts or Instances from Text and Knowledge Base Analysis
Oct 24, 2016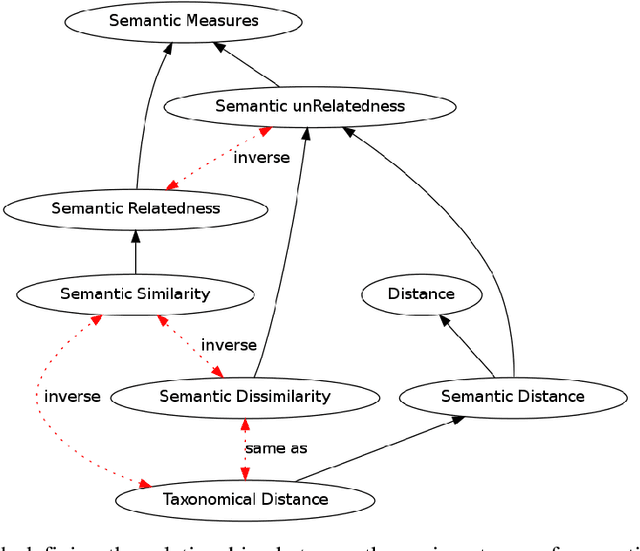
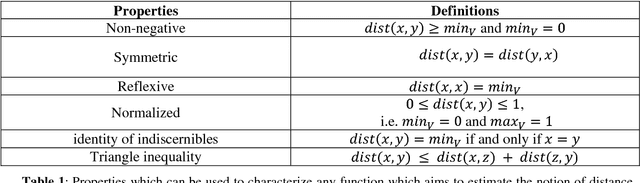

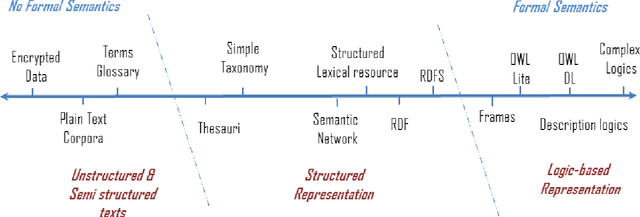
Semantic measures are widely used today to estimate the strength of the semantic relationship between elements of various types: units of language (e.g., words, sentences, documents), concepts or even instances semantically characterized (e.g., diseases, genes, geographical locations). Semantic measures play an important role to compare such elements according to semantic proxies: texts and knowledge representations, which support their meaning or describe their nature. Semantic measures are therefore essential for designing intelligent agents which will for example take advantage of semantic analysis to mimic human ability to compare abstract or concrete objects. This paper proposes a comprehensive survey of the broad notion of semantic measure for the comparison of units of language, concepts or instances based on semantic proxy analyses. Semantic measures generalize the well-known notions of semantic similarity, semantic relatedness and semantic distance, which have been extensively studied by various communities over the last decades (e.g., Cognitive Sciences, Linguistics, and Artificial Intelligence to mention a few).