 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Shallow Neural Networks with Functional Connectivity from EEG signals for Early Diagnosis of Alzheimer's and Frontotemporal Dementia
Nov 06, 2023
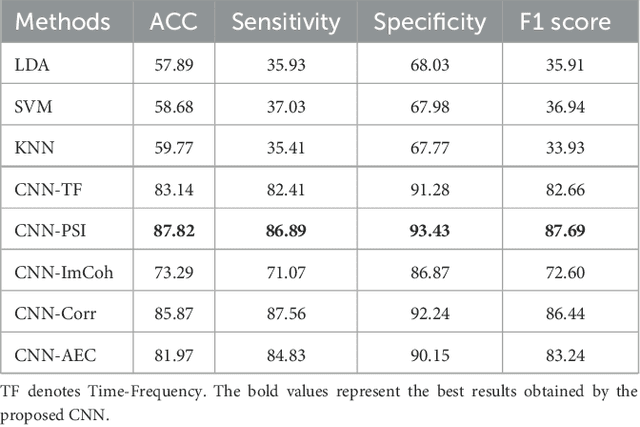

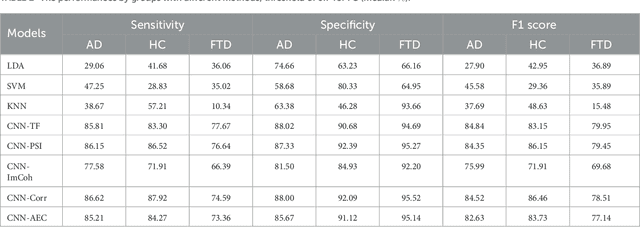
{Introduction: } Dementia is a neurological disorder associated with aging that can cause a loss of cognitive functions, impacting daily life. Alzheimer's disease (AD) is the most common cause of dementia, accounting for 50--70\% of cases, while frontotemporal dementia (FTD) affects social skills and personality. Electroencephalography (EEG) provides an effective tool to study the effects of AD on the brain. {Methods: } In this study, we propose to use shallow neural networks applied to two sets of features: spectral-temporal and functional connectivity using four methods. We compare three supervised machine learning techniques to the CNN models to classify EEG signals of AD / FTD and control cases. We also evaluate different measures of functional connectivity from common EEG frequency bands considering multiple thresholds. {Results and Discussion: } Results showed that the shallow CNN-based models achieved the highest accuracy of 94.54\% with AEC in test dataset when considering all connections, outperforming conventional methods and providing potentially an additional early dementia diagnosis tool. \url{https://doi.org/10.3389%2Ffneur.2023.1270405}
Mental arithmetic task classification with convolutional neural network based on spectral-temporal features from EEG
Sep 26, 2022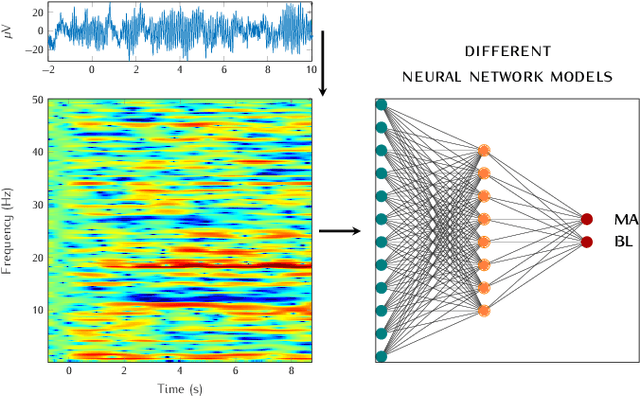
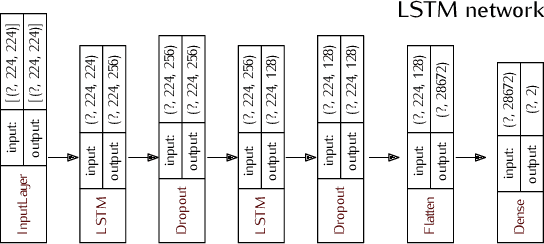
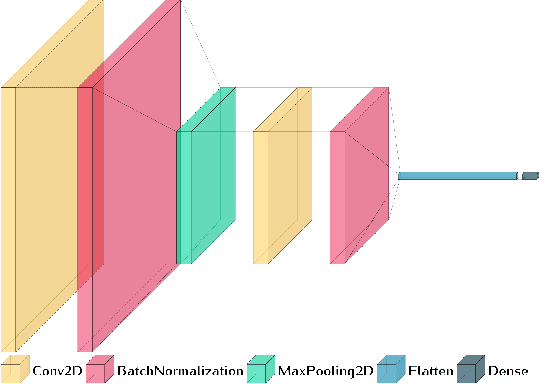
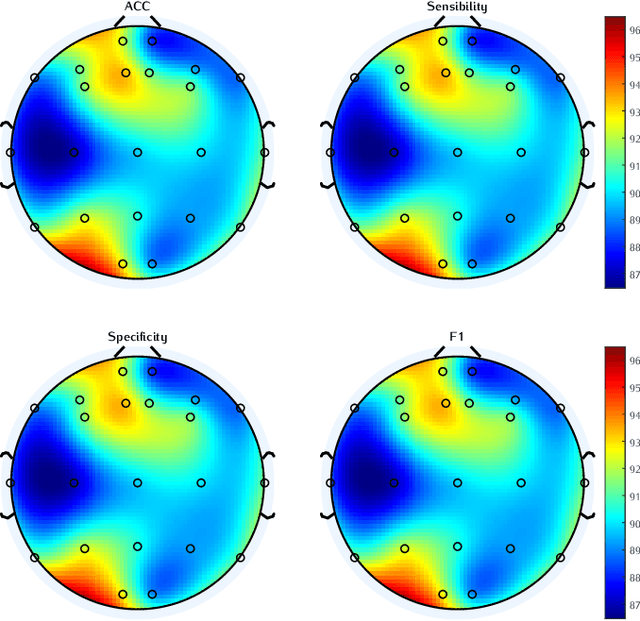
In recent years, neuroscientists have been interested to the development of brain-computer interface (BCI) devices. Patients with motor disorders may benefit from BCIs as a means of communication and for the restoration of motor functions. Electroencephalography (EEG) is one of most used for evaluating the neuronal activity. In many computer vision applications, deep neural networks (DNN) show significant advantages. Towards to ultimate usage of DNN, we present here a shallow neural network that uses mainly two convolutional neural network (CNN) layers, with relatively few parameters and fast to learn spectral-temporal features from EEG. We compared this models to three other neural network models with different depths applied to a mental arithmetic task using eye-closed state adapted for patients suffering from motor disorders and a decline in visual functions. Experimental results showed that the shallow CNN model outperformed all the other models and achieved the highest classification accuracy of 90.68%. It's also more robust to deal with cross-subject classification issues: only 3% standard deviation of accuracy instead of 15.6% from conventional method.
Semantic Similarity from Natural Language and Ontology Analysis
Apr 18, 2017
Artificial Intelligence federates numerous scientific fields in the aim of developing machines able to assist human operators performing complex treatments -- most of which demand high cognitive skills (e.g. learning or decision processes). Central to this quest is to give machines the ability to estimate the likeness or similarity between things in the way human beings estimate the similarity between stimuli. In this context, this book focuses on semantic measures: approaches designed for comparing semantic entities such as units of language, e.g. words, sentences, or concepts and instances defined into knowledge bases. The aim of these measures is to assess the similarity or relatedness of such semantic entities by taking into account their semantics, i.e. their meaning -- intuitively, the words tea and coffee, which both refer to stimulating beverage, will be estimated to be more semantically similar than the words toffee (confection) and coffee, despite that the last pair has a higher syntactic similarity. The two state-of-the-art approaches for estimating and quantifying semantic similarities/relatedness of semantic entities are presented in detail: the first one relies on corpora analysis and is based on Natural Language Processing techniques and semantic models while the second is based on more or less formal, computer-readable and workable forms of knowledge such as semantic networks, thesaurus or ontologies. (...) Beyond a simple inventory and categorization of existing measures, the aim of this monograph is to convey novices as well as researchers of these domains towards a better understanding of semantic similarity estimation and more generally semantic measures.
Semantic Measures for the Comparison of Units of Language, Concepts or Instances from Text and Knowledge Base Analysis
Oct 24, 2016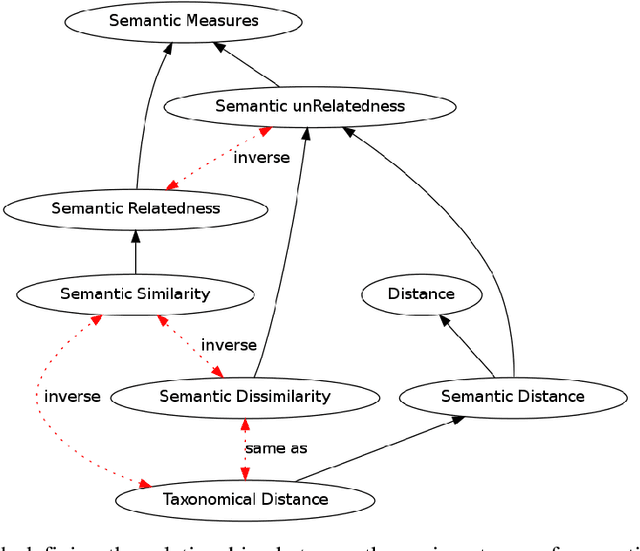
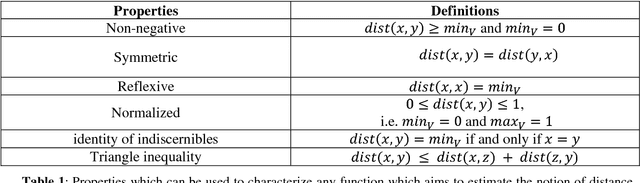

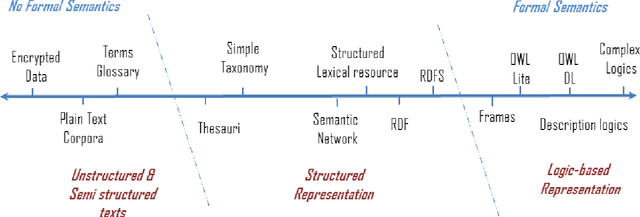
Semantic measures are widely used today to estimate the strength of the semantic relationship between elements of various types: units of language (e.g., words, sentences, documents), concepts or even instances semantically characterized (e.g., diseases, genes, geographical locations). Semantic measures play an important role to compare such elements according to semantic proxies: texts and knowledge representations, which support their meaning or describe their nature. Semantic measures are therefore essential for designing intelligent agents which will for example take advantage of semantic analysis to mimic human ability to compare abstract or concrete objects. This paper proposes a comprehensive survey of the broad notion of semantic measure for the comparison of units of language, concepts or instances based on semantic proxy analyses. Semantic measures generalize the well-known notions of semantic similarity, semantic relatedness and semantic distance, which have been extensively studied by various communities over the last decades (e.g., Cognitive Sciences, Linguistics, and Artificial Intelligence to mention a few).