 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-to-Speech: Prosody Feature Engineering and Transformer-Based Reconstruction
Apr 07, 2026This chapter presents a novel approach to brain-to-speech (BTS) synthesis from intracranial electroencephalography (iEEG) data, emphasizing prosody-aware feature engineering and advanced transformer-based models for high-fidelity speech reconstruction. Driven by the increasing interest in decoding speech directly from brain activity, this work integrates neuroscience, artificial intelligence, and signal processing to generate accurate and natural speech. We introduce a novel pipeline for extracting key prosodic features directly from complex brain iEEG signals, including intonation, pitch, and rhythm. To effectively utilize these crucial features for natural-sounding speech, we employ advanced deep learning models. Furthermore, this chapter introduces a novel transformer encoder architecture specifically designed for brain-to-speech tasks. Unlike conventional models, our architecture integrates the extracted prosodic features to significantly enhance speech reconstruction, resulting in generated speech with improved intelligibility and expressiveness. A detailed evaluation demonstrates superior performance over established baseline methods, such as traditional Griffin-Lim and CNN-based reconstruction, across both quantitative and perceptual metrics. By demonstrating these advancements in feature extraction and transformer-based learning, this chapter contributes to the growing field of AI-driven neuroprosthetics, paving the way for assistive technologies that restore communication for individuals with speech impairments. Finally, we discuss promising future research directions, including the integration of diffusion models and real-time inference systems.
UniScale: Unified Scale-Aware 3D Reconstruction for Multi-View Understanding via Prior Injection for Robotic Perception
Feb 26, 2026We present UniScale, a unified, scale-aware multi-view 3D reconstruction framework for robotic applications that flexibly integrates geometric priors through a modular, semantically informed design. In vision-based robotic navigation, the accurate extraction of environmental structure from raw image sequences is critical for downstream tasks. UniScale addresses this challenge with a single feed-forward network that jointly estimates camera intrinsics and extrinsics, scale-invariant depth and point maps, and the metric scale of a scene from multi-view images, while optionally incorporating auxiliary geometric priors when available. By combining global contextual reasoning with camera-aware feature representations, UniScale is able to recover the metric-scale of the scene. In robotic settings where camera intrinsics are known, they can be easily incorporated to improve performance, with additional gains obtained when camera poses are also available. This co-design enables robust, metric-aware 3D reconstruction within a single unified model. Importantly, UniScale does not require training from scratch, and leverages world priors exhibited in pre-existing models without geometric encoding strategies, making it particularly suitable for resource-constrained robotic teams. We evaluate UniScale on multiple benchmarks, demonstrating strong generalization and consistent performance across diverse environments. We will release our implementation upon acceptance.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
Toward General Object-level Mapping from Sparse Views with 3D Diffusion Priors
Oct 07, 2024Object-level mapping builds a 3D map of objects in a scene with detailed shapes and poses from multi-view sensor observations. Conventional methods struggle to build complete shapes and estimate accurate poses due to partial occlusions and sensor noise. They require dense observations to cover all objects, which is challenging to achieve in robotics trajectories. Recent work introduces generative shape priors for object-level mapping from sparse views, but is limited to single-category objects. In this work, we propose a General Object-level Mapping system, GOM, which leverages a 3D diffusion model as shape prior with multi-category support and outputs Neural Radiance Fields (NeRFs) for both texture and geometry for all objects in a scene. GOM includes an effective formulation to guide a pre-trained diffusion model with extra nonlinear constraints from sensor measurements without finetuning. We also develop a probabilistic optimization formulation to fuse multi-view sensor observations and diffusion priors for joint 3D object pose and shape estimation. Our GOM system demonstrates superior multi-category mapping performance from sparse views, and achieves more accurate mapping results compared to state-of-the-art methods on the real-world benchmarks. We will release our code: https://github.com/TRAILab/GeneralObjectMapping.
MOSE: Monocular Semantic Reconstruction Using NeRF-Lifted Noisy Priors
Sep 21, 2024



Accurately reconstructing dense and semantically annotated 3D meshes from monocular images remains a challenging task due to the lack of geometry guidance and imperfect view-dependent 2D priors. Though we have witnessed recent advancements in implicit neural scene representations enabling precise 2D rendering simply from multi-view images, there have been few works addressing 3D scene understanding with monocular priors alone. In this paper, we propose MOSE, a neural field semantic reconstruction approach to lift inferred image-level noisy priors to 3D, producing accurate semantics and geometry in both 3D and 2D space. The key motivation for our method is to leverage generic class-agnostic segment masks as guidance to promote local consistency of rendered semantics during training. With the help of semantics, we further apply a smoothness regularization to texture-less regions for better geometric quality, thus achieving mutual benefits of geometry and semantics. Experiments on the ScanNet dataset show that our MOSE outperforms relevant baselines across all metrics on tasks of 3D semantic segmentation, 2D semantic segmentation and 3D surface reconstruction.
MakeWay: Object-Aware Costmaps for Proactive Indoor Navigation Using LiDAR
Aug 30, 2024



In this paper, we introduce a LiDAR-based robot navigation system, based on novel object-aware affordance-based costmaps. Utilizing a 3D object detection network, our system identifies objects of interest in LiDAR keyframes, refines their 3D poses with the Iterative Closest Point (ICP) algorithm, and tracks them via Kalman filters and the Hungarian algorithm for data association. It then updates existing object poses with new associated detections and creates new object maps for unmatched detections. Using the maintained object-level mapping system, our system creates affordance-driven object costmaps for proactive collision avoidance in path planning. Additionally, we address the scarcity of indoor semantic LiDAR data by introducing an automated labeling technique. This method utilizes a CAD model database for accurate ground-truth annotations, encompassing bounding boxes, positions, orientations, and point-wise semantics of each object in LiDAR sequences. Our extensive evaluations, conducted in both simulated and real-world robot platforms, highlights the effectiveness of proactive object avoidance by using object affordance costmaps, enhancing robotic navigation safety and efficiency. The system can operate in real-time onboard and we intend to release our code and data for public use.
Getting Inspiration for Feature Elicitation: App Store- vs. LLM-based Approach
Aug 30, 2024Over the past decade, app store (AppStore)-inspired requirements elicitation has proven to be highly beneficial. Developers often explore competitors' apps to gather inspiration for new features. With the advance of Generative AI, recent studies have demonstrated the potential of large language model (LLM)-inspired requirements elicitation. LLMs can assist in this process by providing inspiration for new feature ideas. While both approaches are gaining popularity in practice, there is a lack of insight into their differences. We report on a comparative study between AppStore- and LLM-based approaches for refining features into sub-features. By manually analyzing 1,200 sub-features recommended from both approaches, we identified their benefits, challenges, and key differences. While both approaches recommend highly relevant sub-features with clear descriptions, LLMs seem more powerful particularly concerning novel unseen app scopes. Moreover, some recommended features are imaginary with unclear feasibility, which suggests the importance of a human-analyst in the elicitation loop.
Adversarial 3D Virtual Patches using Integrated Gradients
Jun 01, 2024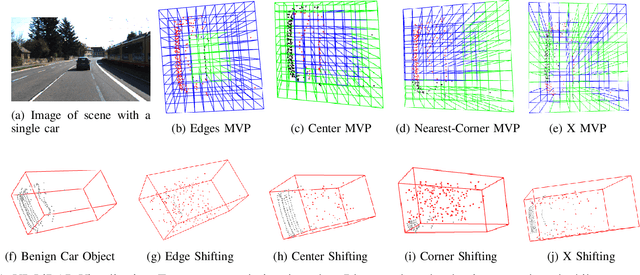
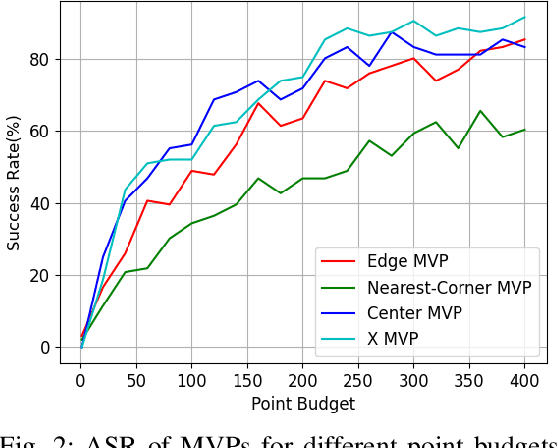
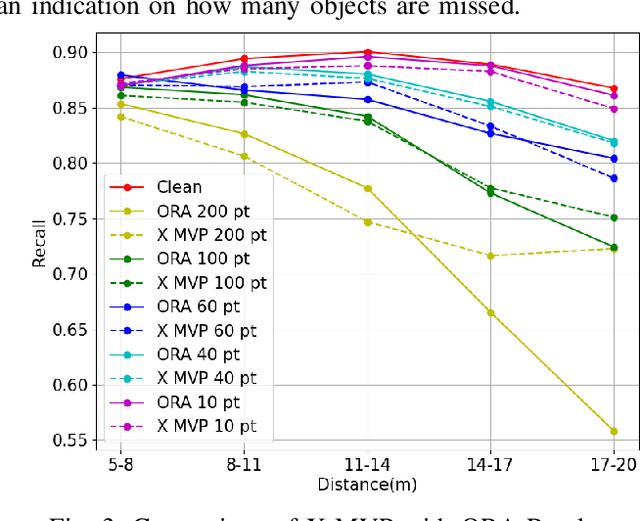
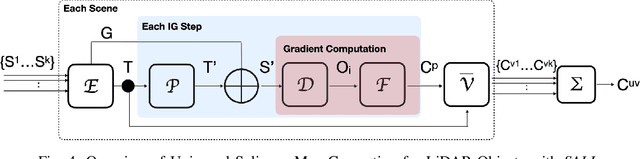
LiDAR sensors are widely used in autonomous vehicles to better perceive the environment. However, prior works have shown that LiDAR signals can be spoofed to hide real objects from 3D object detectors. This study explores the feasibility of reducing the required spoofing area through a novel object-hiding strategy based on virtual patches (VPs). We first manually design VPs (MVPs) and show that VP-focused attacks can achieve similar success rates with prior work but with a fraction of the required spoofing area. Then we design a framework Saliency-LiDAR (SALL), which can identify critical regions for LiDAR objects using Integrated Gradients. VPs crafted on critical regions (CVPs) reduce object detection recall by at least 15% compared to our baseline with an approximate 50% reduction in the spoofing area for vehicles of average size.
GUing: A Mobile GUI Search Engine using a Vision-Language Model
Apr 30, 2024



App developers use the Graphical User Interface (GUI) of other apps as an important source of inspiration to design and improve their own apps. In recent years, research suggested various approaches to retrieve GUI designs that fit a certain text query from screenshot datasets acquired through automated GUI exploration. However, such text-to-GUI retrieval approaches only leverage the textual information of the GUI elements in the screenshots, neglecting visual information such as icons or background images. In addition, the retrieved screenshots are not steered by app developers and often lack important app features, e.g. whose UI pages require user authentication. To overcome these limitations, this paper proposes GUing, a GUI search engine based on a vision-language model called UIClip, which we trained specifically for the app GUI domain. For this, we first collected app introduction images from Google Play, which usually display the most representative screenshots selected and often captioned (i.e. labeled) by app vendors. Then, we developed an automated pipeline to classify, crop, and extract the captions from these images. This finally results in a large dataset which we share with this paper: including 303k app screenshots, out of which 135k have captions. We used this dataset to train a novel vision-language model, which is, to the best of our knowledge, the first of its kind in GUI retrieval. We evaluated our approach on various datasets from related work and in manual experiment. The results demonstrate that our model outperforms previous approaches in text-to-GUI retrieval achieving a Recall@10 of up to 0.69 and a HIT@10 of 0.91. We also explored the performance of UIClip for other GUI tasks including GUI classification and Sketch-to-GUI retrieval with encouraging results.
Identifying Optimal Launch Sites of High-Altitude Latex-Balloons using Bayesian Optimisation for the Task of Station-Keeping
Mar 16, 2024



Station-keeping tasks for high-altitude balloons show promise in areas such as ecological surveys, atmospheric analysis, and communication relays. However, identifying the optimal time and position to launch a latex high-altitude balloon is still a challenging and multifaceted problem. For example, tasks such as forest fire tracking place geometric constraints on the launch location of the balloon. Furthermore, identifying the most optimal location also heavily depends on atmospheric conditions. We first illustrate how reinforcement learning-based controllers, frequently used for station-keeping tasks, can exploit the environment. This exploitation can degrade performance on unseen weather patterns and affect station-keeping performance when identifying an optimal launch configuration. Valuing all states equally in the region, the agent exploits the region's geometry by flying near the edge, leading to risky behaviours. We propose a modification which compensates for this exploitation and finds this leads to, on average, higher steps within the target region on unseen data. Then, we illustrate how Bayesian Optimisation (BO) can identify the optimal launch location to perform station-keeping tasks, maximising the expected undiscounted return from a given rollout. We show BO can find this launch location in fewer steps compared to other optimisation methods. Results indicate that, surprisingly, the most optimal location to launch from is not commonly within the target region. Please find further information about our project at https://sites.google.com/view/bo-lauch-balloon/.