 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian-Voxel Duet: A Dual-Scaffolding Hybrid Representation for Fast and Accurate Monocular Surface Reconstruction
May 26, 2026While 3D Gaussian Splatting has achieved remarkable success in photorealistic novel view synthesis, its pursuit of fast and high-fidelity 3D reconstruction has long been constrained by a trade-off between geometric accuracy and optimization efficiency. Methods specialized in image rendering converge quickly at the cost of imperfect geometry caused by superfluous primitives overfitting training views, while methods integrating neural signed-distance field (SDF) for better geometry incur prohibitive training costs. In this paper, we attempt to strike a better trade-off by tethering scaffold-anchored Gaussians to a jointly optimized sparse voxel scaffold. This hybrid Gaussian-Voxel representation explicitly confines anchored Gaussians to a narrow band around surfaces defined by voxelized SDFs, which effectively improves representation efficiency and condenses floating Gaussians without sacrificing geometry quality. An implicit surface tethering loss further pulls individual Gaussian primitives closer to SDF-induced surfaces in a mutually regularized manner for improved reconstruction accuracy. Extensive experiments on diverse real-world indoor scenes from ScanNet++, ScanNetv2, and DeepBlending datasets demonstrate that our method achieves state-of-the-art surface reconstruction quality as well as superior novel view synthesis against leading baselines, while maintaining fast training convergence and real-time rendering. Code will be available at https://github.com/duzh11/VoxelGS.
RemixFusion: Residual-based Mixed Representation for Large-scale Online RGB-D Reconstruction
Jul 23, 2025The introduction of the neural implicit representation has notably propelled the advancement of online dense reconstruction techniques. Compared to traditional explicit representations, such as TSDF, it improves the mapping completeness and memory efficiency. However, the lack of reconstruction details and the time-consuming learning of neural representations hinder the widespread application of neural-based methods to large-scale online reconstruction. We introduce RemixFusion, a novel residual-based mixed representation for scene reconstruction and camera pose estimation dedicated to high-quality and large-scale online RGB-D reconstruction. In particular, we propose a residual-based map representation comprised of an explicit coarse TSDF grid and an implicit neural module that produces residuals representing fine-grained details to be added to the coarse grid. Such mixed representation allows for detail-rich reconstruction with bounded time and memory budget, contrasting with the overly-smoothed results by the purely implicit representations, thus paving the way for high-quality camera tracking. Furthermore, we extend the residual-based representation to handle multi-frame joint pose optimization via bundle adjustment (BA). In contrast to the existing methods, which optimize poses directly, we opt to optimize pose changes. Combined with a novel technique for adaptive gradient amplification, our method attains better optimization convergence and global optimality. Furthermore, we adopt a local moving volume to factorize the mixed scene representation with a divide-and-conquer design to facilitate efficient online learning in our residual-based framework. Extensive experiments demonstrate that our method surpasses all state-of-the-art ones, including those based either on explicit or implicit representations, in terms of the accuracy of both mapping and tracking on large-scale scenes.
A Reverse Causal Framework to Mitigate Spurious Correlations for Debiasing Scene Graph Generation
May 29, 2025Existing two-stage Scene Graph Generation (SGG) frameworks typically incorporate a detector to extract relationship features and a classifier to categorize these relationships; therefore, the training paradigm follows a causal chain structure, where the detector's inputs determine the classifier's inputs, which in turn influence the final predictions. However, such a causal chain structure can yield spurious correlations between the detector's inputs and the final predictions, i.e., the prediction of a certain relationship may be influenced by other relationships. This influence can induce at least two observable biases: tail relationships are predicted as head ones, and foreground relationships are predicted as background ones; notably, the latter bias is seldom discussed in the literature. To address this issue, we propose reconstructing the causal chain structure into a reverse causal structure, wherein the classifier's inputs are treated as the confounder, and both the detector's inputs and the final predictions are viewed as causal variables. Specifically, we term the reconstructed causal paradigm as the Reverse causal Framework for SGG (RcSGG). RcSGG initially employs the proposed Active Reverse Estimation (ARE) to intervene on the confounder to estimate the reverse causality, \ie the causality from final predictions to the classifier's inputs. Then, the Maximum Information Sampling (MIS) is suggested to enhance the reverse causality estimation further by considering the relationship information. Theoretically, RcSGG can mitigate the spurious correlations inherent in the SGG framework, subsequently eliminating the induced biases. Comprehensive experiments on popular benchmarks and diverse SGG frameworks show the state-of-the-art mean recall rate.
Step-wise Distribution Alignment Guided Style Prompt Tuning for Source-free Cross-domain Few-shot Learning
Nov 15, 2024



Existing cross-domain few-shot learning (CDFSL) methods, which develop source-domain training strategies to enhance model transferability, face challenges with large-scale pre-trained models (LMs) due to inaccessible source data and training strategies. Moreover, fine-tuning LMs for CDFSL demands substantial computational resources, limiting practicality. This paper addresses the source-free CDFSL (SF-CDFSL) problem, tackling few-shot learning (FSL) in the target domain using only pre-trained models and a few target samples without source data or strategies. To overcome the challenge of inaccessible source data, this paper introduces Step-wise Distribution Alignment Guided Style Prompt Tuning (StepSPT), which implicitly narrows domain gaps through prediction distribution optimization. StepSPT proposes a style prompt to align target samples with the desired distribution and adopts a dual-phase optimization process. In the external process, a step-wise distribution alignment strategy factorizes prediction distribution optimization into a multi-step alignment problem to tune the style prompt. In the internal process, the classifier is updated using standard cross-entropy loss. Evaluations on five datasets demonstrate that StepSPT outperforms existing prompt tuning-based methods and SOTAs. Ablation studies further verify its effectiveness. Code will be made publicly available at \url{https://github.com/xuhuali-mxj/StepSPT}.
MOSE: Monocular Semantic Reconstruction Using NeRF-Lifted Noisy Priors
Sep 21, 2024



Accurately reconstructing dense and semantically annotated 3D meshes from monocular images remains a challenging task due to the lack of geometry guidance and imperfect view-dependent 2D priors. Though we have witnessed recent advancements in implicit neural scene representations enabling precise 2D rendering simply from multi-view images, there have been few works addressing 3D scene understanding with monocular priors alone. In this paper, we propose MOSE, a neural field semantic reconstruction approach to lift inferred image-level noisy priors to 3D, producing accurate semantics and geometry in both 3D and 2D space. The key motivation for our method is to leverage generic class-agnostic segment masks as guidance to promote local consistency of rendered semantics during training. With the help of semantics, we further apply a smoothness regularization to texture-less regions for better geometric quality, thus achieving mutual benefits of geometry and semantics. Experiments on the ScanNet dataset show that our MOSE outperforms relevant baselines across all metrics on tasks of 3D semantic segmentation, 2D semantic segmentation and 3D surface reconstruction.
Enhancing Information Maximization with Distance-Aware Contrastive Learning for Source-Free Cross-Domain Few-Shot Learning
Mar 04, 2024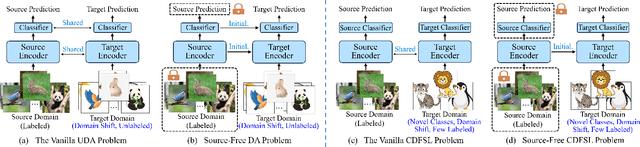
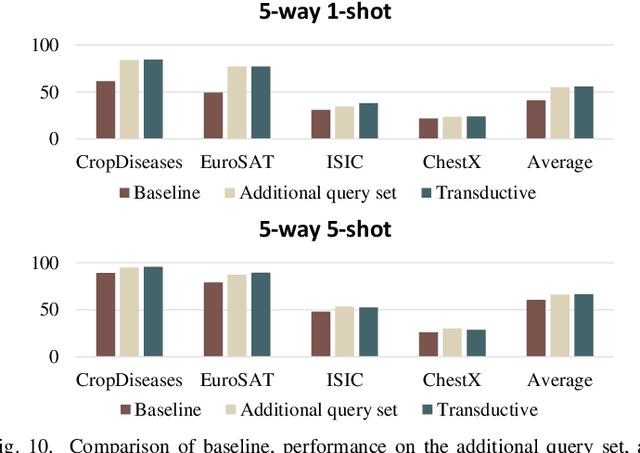
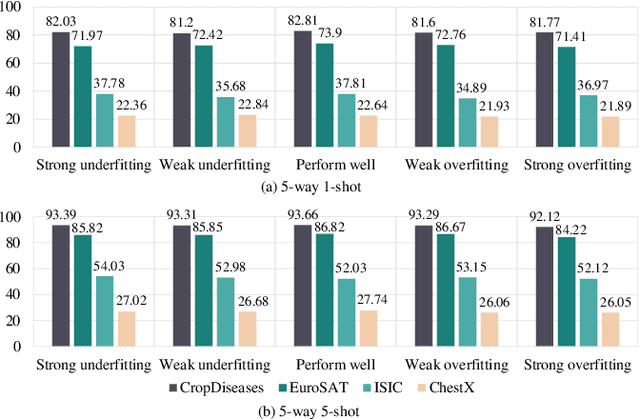
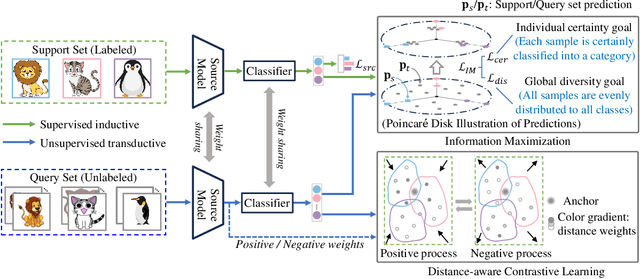
Existing Cross-Domain Few-Shot Learning (CDFSL) methods require access to source domain data to train a model in the pre-training phase. However, due to increasing concerns about data privacy and the desire to reduce data transmission and training costs, it is necessary to develop a CDFSL solution without accessing source data. For this reason, this paper explores a Source-Free CDFSL (SF-CDFSL) problem, in which CDFSL is addressed through the use of existing pretrained models instead of training a model with source data, avoiding accessing source data. This paper proposes an Enhanced Information Maximization with Distance-Aware Contrastive Learning (IM-DCL) method to address these challenges. Firstly, we introduce the transductive mechanism for learning the query set. Secondly, information maximization (IM) is explored to map target samples into both individual certainty and global diversity predictions, helping the source model better fit the target data distribution. However, IM fails to learn the decision boundary of the target task. This motivates us to introduce a novel approach called Distance-Aware Contrastive Learning (DCL), in which we consider the entire feature set as both positive and negative sets, akin to Schrodinger's concept of a dual state. Instead of a rigid separation between positive and negative sets, we employ a weighted distance calculation among features to establish a soft classification of the positive and negative sets for the entire feature set. Furthermore, we address issues related to IM by incorporating contrastive constraints between object features and their corresponding positive and negative sets. Evaluations of the 4 datasets in the BSCD-FSL benchmark indicate that the proposed IM-DCL, without accessing the source domain, demonstrates superiority over existing methods, especially in the distant domain task.
PlaneRecTR: Unified Query Learning for 3D Plane Recovery from a Single View
Aug 17, 2023



3D plane recovery from a single image can usually be divided into several subtasks of plane detection, segmentation, parameter estimation and possibly depth estimation. Previous works tend to solve this task by either extending the RCNN-based segmentation network or the dense pixel embedding-based clustering framework. However, none of them tried to integrate above related subtasks into a unified framework but treat them separately and sequentially, which we suspect is potentially a main source of performance limitation for existing approaches. Motivated by this finding and the success of query-based learning in enriching reasoning among semantic entities, in this paper, we propose PlaneRecTR, a Transformer-based architecture, which for the first time unifies all subtasks related to single-view plane recovery with a single compact model. Extensive quantitative and qualitative experiments demonstrate that our proposed unified learning achieves mutual benefits across subtasks, obtaining a new state-of-the-art performance on public ScanNet and NYUv2-Plane datasets. Codes are available at https://github.com/SJingjia/PlaneRecTR.
ROFusion: Efficient Object Detection using Hybrid Point-wise Radar-Optical Fusion
Jul 17, 2023



Radars, due to their robustness to adverse weather conditions and ability to measure object motions, have served in autonomous driving and intelligent agents for years. However, Radar-based perception suffers from its unintuitive sensing data, which lack of semantic and structural information of scenes. To tackle this problem, camera and Radar sensor fusion has been investigated as a trending strategy with low cost, high reliability and strong maintenance. While most recent works explore how to explore Radar point clouds and images, rich contextual information within Radar observation are discarded. In this paper, we propose a hybrid point-wise Radar-Optical fusion approach for object detection in autonomous driving scenarios. The framework benefits from dense contextual information from both the range-doppler spectrum and images which are integrated to learn a multi-modal feature representation. Furthermore, we propose a novel local coordinate formulation, tackling the object detection task in an object-centric coordinate. Extensive results show that with the information gained from optical images, we could achieve leading performance in object detection (97.69\% recall) compared to recent state-of-the-art methods FFT-RadNet (82.86\% recall). Ablation studies verify the key design choices and practicability of our approach given machine generated imperfect detections. The code will be available at https://github.com/LiuLiu-55/ROFusion.
Unbiased Scene Graph Generation via Two-stage Causal Modeling
Jul 11, 2023Despite the impressive performance of recent unbiased Scene Graph Generation (SGG) methods, the current debiasing literature mainly focuses on the long-tailed distribution problem, whereas it overlooks another source of bias, i.e., semantic confusion, which makes the SGG model prone to yield false predictions for similar relationships. In this paper, we explore a debiasing procedure for the SGG task leveraging causal inference. Our central insight is that the Sparse Mechanism Shift (SMS) in causality allows independent intervention on multiple biases, thereby potentially preserving head category performance while pursuing the prediction of high-informative tail relationships. However, the noisy datasets lead to unobserved confounders for the SGG task, and thus the constructed causal models are always causal-insufficient to benefit from SMS. To remedy this, we propose Two-stage Causal Modeling (TsCM) for the SGG task, which takes the long-tailed distribution and semantic confusion as confounders to the Structural Causal Model (SCM) and then decouples the causal intervention into two stages. The first stage is causal representation learning, where we use a novel Population Loss (P-Loss) to intervene in the semantic confusion confounder. The second stage introduces the Adaptive Logit Adjustment (AL-Adjustment) to eliminate the long-tailed distribution confounder to complete causal calibration learning. These two stages are model agnostic and thus can be used in any SGG model that seeks unbiased predictions. Comprehensive experiments conducted on the popular SGG backbones and benchmarks show that our TsCM can achieve state-of-the-art performance in terms of mean recall rate. Furthermore, TsCM can maintain a higher recall rate than other debiasing methods, which indicates that our method can achieve a better tradeoff between head and tail relationships.
Deep Learning for Cross-Domain Few-Shot Visual Recognition: A Survey
Mar 15, 2023


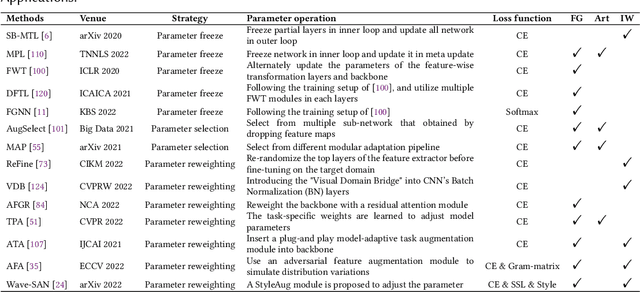
Deep learning has been highly successful in computer vision with large amounts of labeled data, but struggles with limited labeled training data. To address this, Few-shot learning (FSL) is proposed, but it assumes that all samples (including source and target task data, where target tasks are performed with prior knowledge from source ones) are from the same domain, which is a stringent assumption in the real world. To alleviate this limitation, Cross-domain few-shot learning (CDFSL) has gained attention as it allows source and target data from different domains and label spaces. This paper provides a comprehensive review of CDFSL at the first time, which has received far less attention than FSL due to its unique setup and difficulties. We expect this paper to serve as both a position paper and a tutorial for those doing research in CDFSL. This review first introduces the definition of CDFSL and the issues involved, followed by the core scientific question and challenge. A comprehensive review of validated CDFSL approaches from the existing literature is then presented, along with their detailed descriptions based on a rigorous taxonomy. Furthermore, this paper outlines and discusses several promising directions of CDFSL that deserve further scientific investigation, covering aspects of problem setups, applications and theories.