 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMIF: Deep Monotonic Implicit Fields for Large-Scale LiDAR 3D Mapping
Mar 26, 2024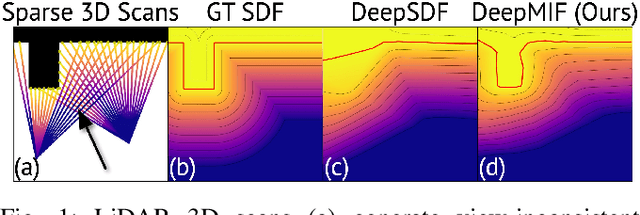
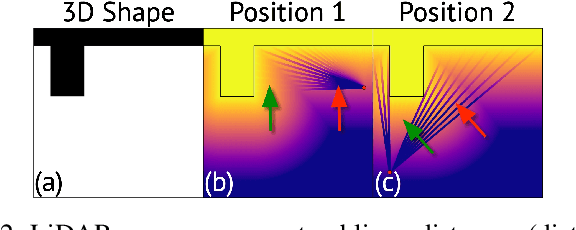
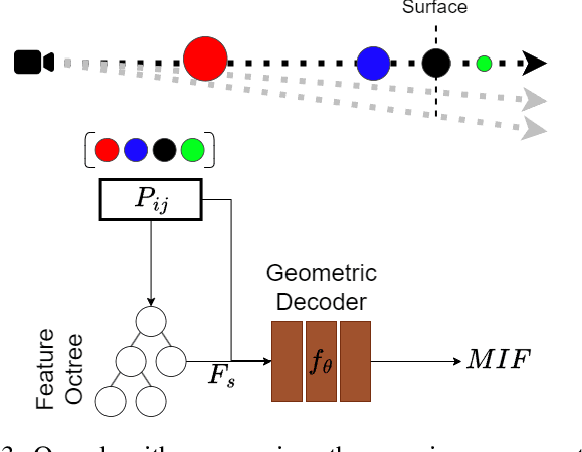

Recently, significant progress has been achieved in sensing real large-scale outdoor 3D environments, particularly by using modern acquisition equipment such as LiDAR sensors. Unfortunately, they are fundamentally limited in their ability to produce dense, complete 3D scenes. To address this issue, recent learning-based methods integrate neural implicit representations and optimizable feature grids to approximate surfaces of 3D scenes. However, naively fitting samples along raw LiDAR rays leads to noisy 3D mapping results due to the nature of sparse, conflicting LiDAR measurements. Instead, in this work we depart from fitting LiDAR data exactly, instead letting the network optimize a non-metric monotonic implicit field defined in 3D space. To fit our field, we design a learning system integrating a monotonicity loss that enables optimizing neural monotonic fields and leverages recent progress in large-scale 3D mapping. Our algorithm achieves high-quality dense 3D mapping performance as captured by multiple quantitative and perceptual measures and visual results obtained for Mai City, Newer College, and KITTI benchmarks. The code of our approach will be made publicly available.
AutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Mar 24, 2024



Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
PRS: Sharp Feature Priors for Resolution-Free Surface Remeshing
Nov 30, 2023Surface reconstruction with preservation of geometric features is a challenging computer vision task. Despite significant progress in implicit shape reconstruction, state-of-the-art mesh extraction methods often produce aliased, perceptually distorted surfaces and lack scalability to high-resolution 3D shapes. We present a data-driven approach for automatic feature detection and remeshing that requires only a coarse, aliased mesh as input and scales to arbitrary resolution reconstructions. We define and learn a collection of surface-based fields to (1) capture sharp geometric features in the shape with an implicit vertexwise model and (2) approximate improvements in normals alignment obtained by applying edge-flips with an edgewise model. To support scaling to arbitrary complexity shapes, we learn our fields using local triangulated patches, fusing estimates on complete surface meshes. Our feature remeshing algorithm integrates the learned fields as sharp feature priors and optimizes vertex placement and mesh connectivity for maximum expected surface improvement. On a challenging collection of high-resolution shape reconstructions in the ABC dataset, our algorithm improves over state-of-the-art by 26% normals F-score and 42% perceptual $\text{RMSE}_{\text{v}}$.
MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers
Nov 27, 2023



We introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing methods from neural fields. Inspired by recent advances in powerful large language models, we adopt a sequence-based approach to autoregressively generate triangle meshes as sequences of triangles. We first learn a vocabulary of latent quantized embeddings, using graph convolutions, which inform these embeddings of the local mesh geometry and topology. These embeddings are sequenced and decoded into triangles by a decoder, ensuring that they can effectively reconstruct the mesh. A transformer is then trained on this learned vocabulary to predict the index of the next embedding given previous embeddings. Once trained, our model can be autoregressively sampled to generate new triangle meshes, directly generating compact meshes with sharp edges, more closely imitating the efficient triangulation patterns of human-crafted meshes. MeshGPT demonstrates a notable improvement over state of the art mesh generation methods, with a 9% increase in shape coverage and a 30-point enhancement in FID scores across various categories.
S4R: Self-Supervised Semantic Scene Reconstruction from RGB-D Scans
Feb 21, 2023



Most deep learning approaches to comprehensive semantic modeling of 3D indoor spaces require costly dense annotations in the 3D domain. In this work, we explore a central 3D scene modeling task, namely, semantic scene reconstruction, using a fully self-supervised approach. To this end, we design a trainable model that employs both incomplete 3D reconstructions and their corresponding source RGB-D images, fusing cross-domain features into volumetric embeddings to predict complete 3D geometry, color, and semantics. Our key technical innovation is to leverage differentiable rendering of color and semantics, using the observed RGB images and a generic semantic segmentation model as color and semantics supervision, respectively. We additionally develop a method to synthesize an augmented set of virtual training views complementing the original real captures, enabling more efficient self-supervision for semantics. In this work we propose an end-to-end trainable solution jointly addressing geometry completion, colorization, and semantic mapping from a few RGB-D images, without 3D or 2D ground-truth. Our method is the first, to our knowledge, fully self-supervised method addressing completion and semantic segmentation of real-world 3D scans. It performs comparably well with the 3D supervised baselines, surpasses baselines with 2D supervision on real datasets, and generalizes well to unseen scenes.
Scan2Part: Fine-grained and Hierarchical Part-level Understanding of Real-World 3D Scans
Jun 06, 2022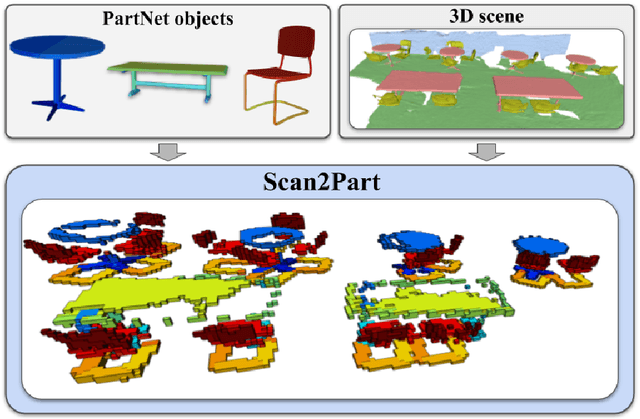
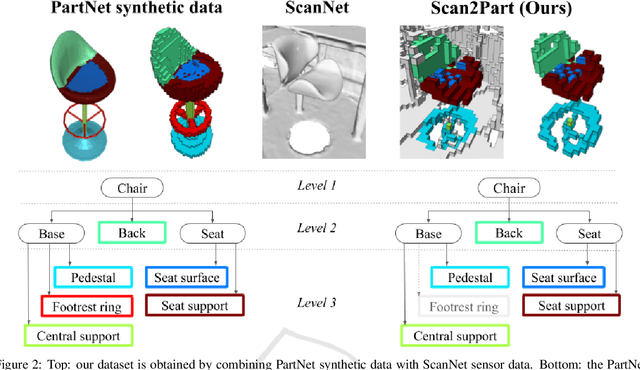
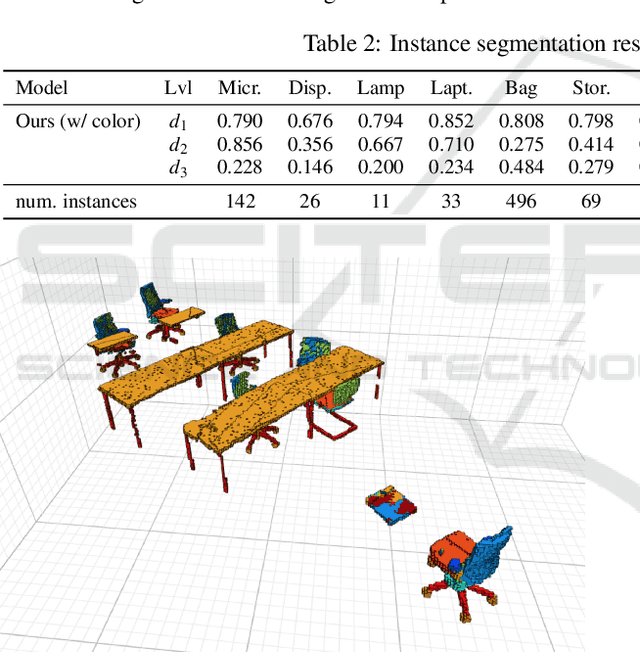
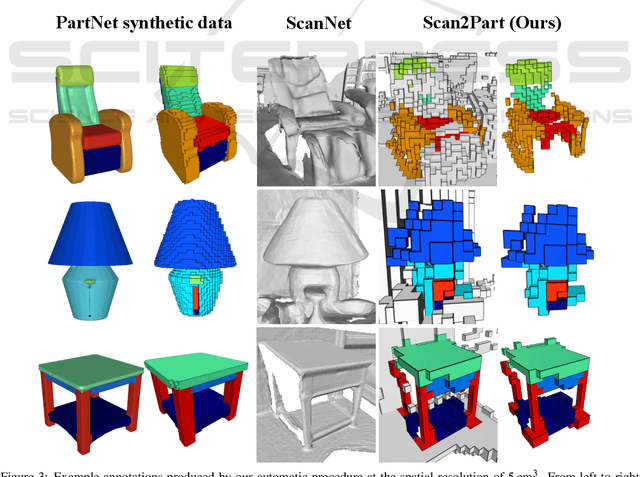
We propose Scan2Part, a method to segment individual parts of objects in real-world, noisy indoor RGB-D scans. To this end, we vary the part hierarchies of objects in indoor scenes and explore their effect on scene understanding models. Specifically, we use a sparse U-Net-based architecture that captures the fine-scale detail of the underlying 3D scan geometry by leveraging a multi-scale feature hierarchy. In order to train our method, we introduce the Scan2Part dataset, which is the first large-scale collection providing detailed semantic labels at the part level in the real-world setting. In total, we provide 242,081 correspondences between 53,618 PartNet parts of 2,477 ShapeNet objects and 1,506 ScanNet scenes, at two spatial resolutions of 2 cm$^3$ and 5 cm$^3$. As output, we are able to predict fine-grained per-object part labels, even when the geometry is coarse or partially missing.
Multi-sensor large-scale dataset for multi-view 3D reconstruction
Mar 11, 2022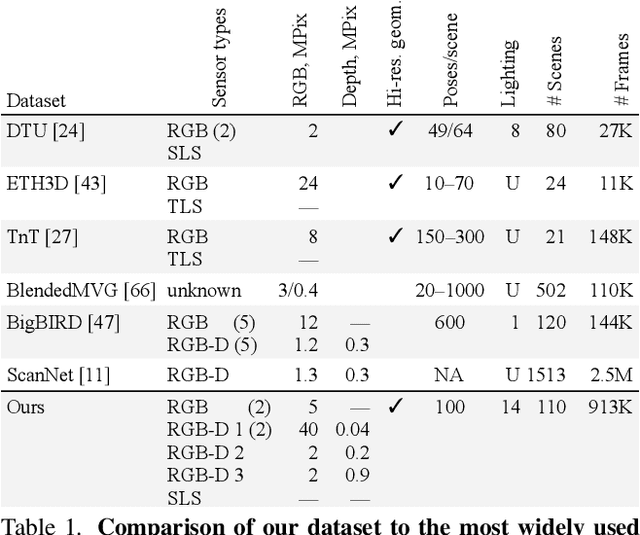
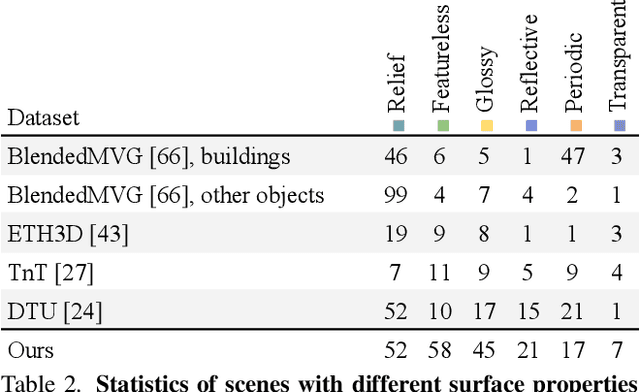

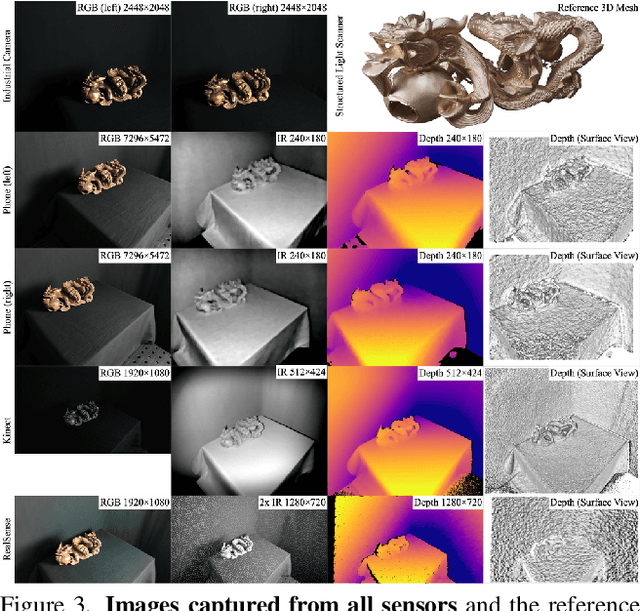
We present a new multi-sensor dataset for 3D surface reconstruction. It includes registered RGB and depth data from sensors of different resolutions and modalities: smartphones, Intel RealSense, Microsoft Kinect, industrial cameras, and structured-light scanner. The data for each scene is obtained under a large number of lighting conditions, and the scenes are selected to emphasize a diverse set of material properties challenging for existing algorithms. In the acquisition process, we aimed to maximize high-resolution depth data quality for challenging cases, to provide reliable ground truth for learning algorithms. Overall, we provide over 1.4 million images of 110 different scenes acquired at 14 lighting conditions from 100 viewing directions. We expect our dataset will be useful for evaluation and training of 3D reconstruction algorithms of different types and for other related tasks. Our dataset and accompanying software will be available online.
Can We Use Neural Regularization to Solve Depth Super-Resolution?
Dec 21, 2021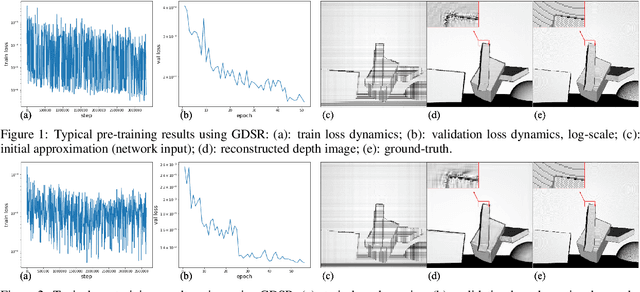

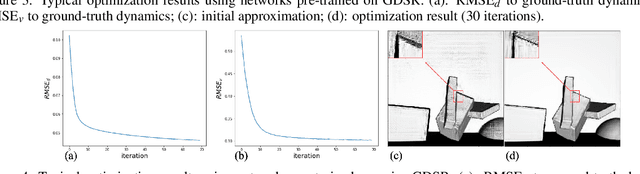
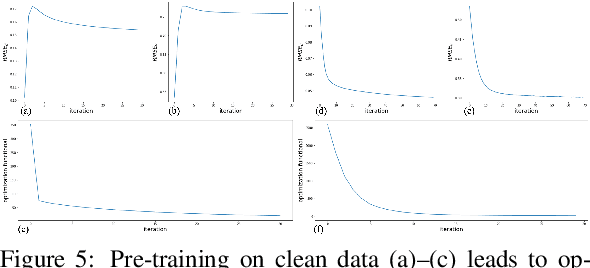
Depth maps captured with commodity sensors often require super-resolution to be used in applications. In this work we study a super-resolution approach based on a variational problem statement with Tikhonov regularization where the regularizer is parametrized with a deep neural network. This approach was previously applied successfully in photoacoustic tomography. We experimentally show that its application to depth map super-resolution is difficult, and provide suggestions about the reasons for that.
3D Parametric Wireframe Extraction Based on Distance Fields
Jul 13, 2021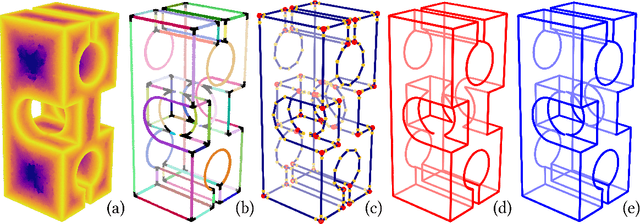

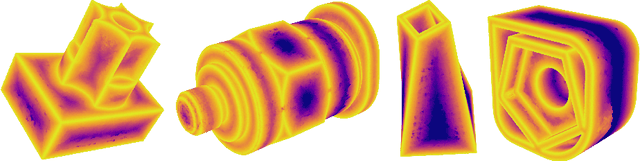
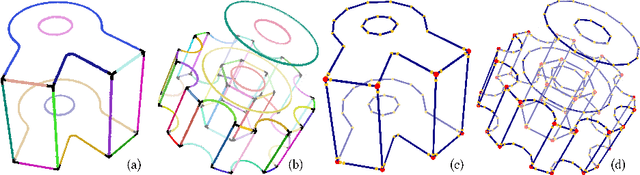
We present a pipeline for parametric wireframe extraction from densely sampled point clouds. Our approach processes a scalar distance field that represents proximity to the nearest sharp feature curve. In intermediate stages, it detects corners, constructs curve segmentation, and builds a topological graph fitted to the wireframe. As an output, we produce parametric spline curves that can be edited and sampled arbitrarily. We evaluate our method on 50 complex 3D shapes and compare it to the novel deep learning-based technique, demonstrating superior quality.
Towards Unpaired Depth Enhancement and Super-Resolution in the Wild
May 25, 2021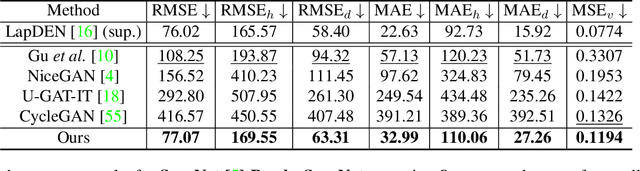
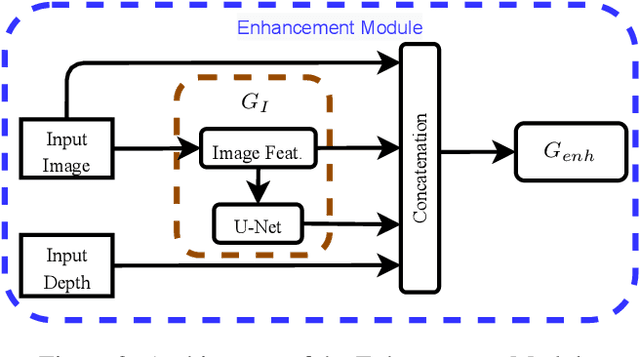
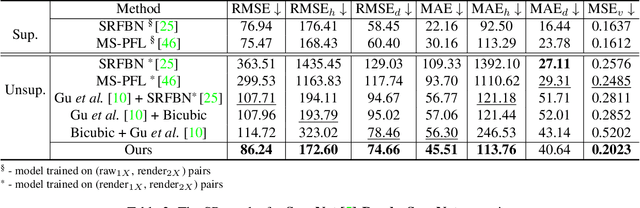
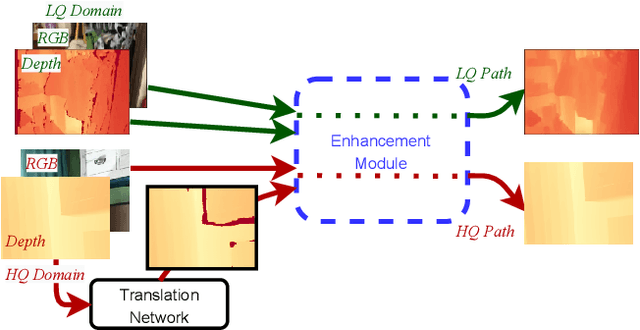
Depth maps captured with commodity sensors are often of low quality and resolution; these maps need to be enhanced to be used in many applications. State-of-the-art data-driven methods of depth map super-resolution rely on registered pairs of low- and high-resolution depth maps of the same scenes. Acquisition of real-world paired data requires specialized setups. Another alternative, generating low-resolution maps from high-resolution maps by subsampling, adding noise and other artificial degradation methods, does not fully capture the characteristics of real-world low-resolution images. As a consequence, supervised learning methods trained on such artificial paired data may not perform well on real-world low-resolution inputs. We consider an approach to depth map enhancement based on learning from unpaired data. While many techniques for unpaired image-to-image translation have been proposed, most are not directly applicable to depth maps. We propose an unpaired learning method for simultaneous depth enhancement and super-resolution, which is based on a learnable degradation model and surface normal estimates as features to produce more accurate depth maps. We demonstrate that our method outperforms existing unpaired methods and performs on par with paired methods on a new benchmark for unpaired learning that we developed.