 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScan2Part: Fine-grained and Hierarchical Part-level Understanding of Real-World 3D Scans
Jun 06, 2022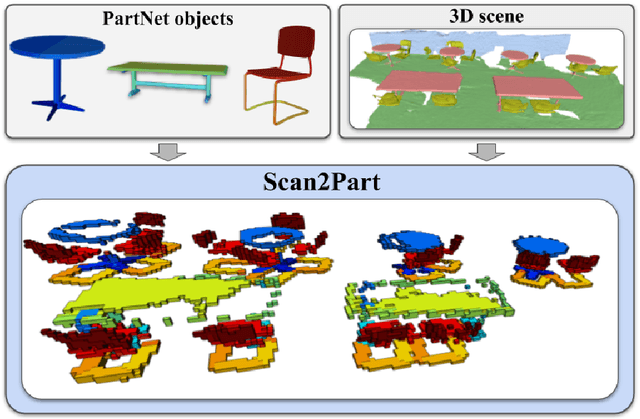
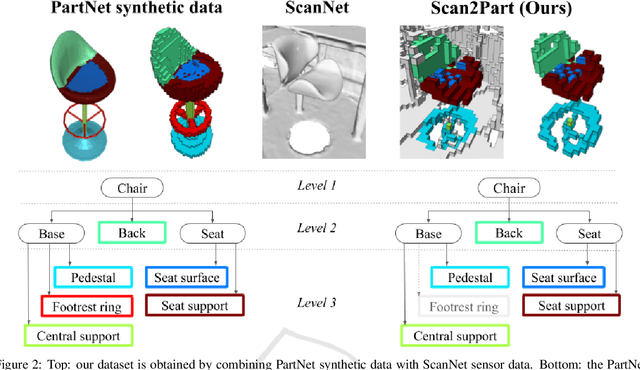
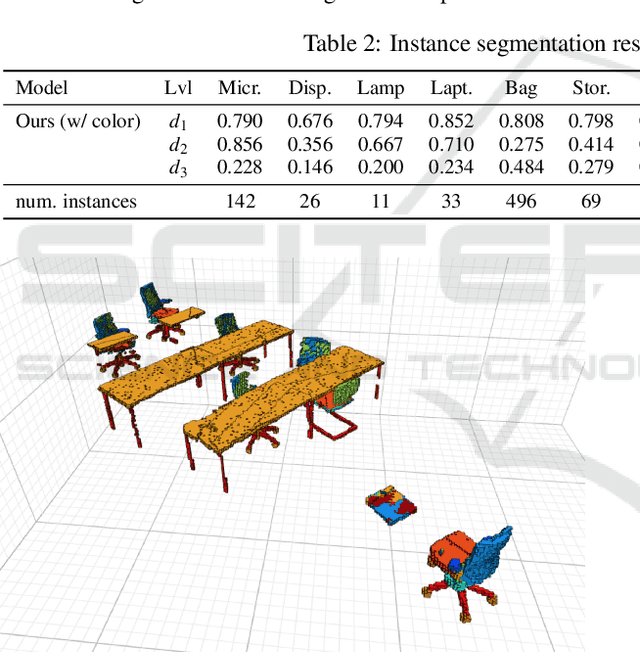
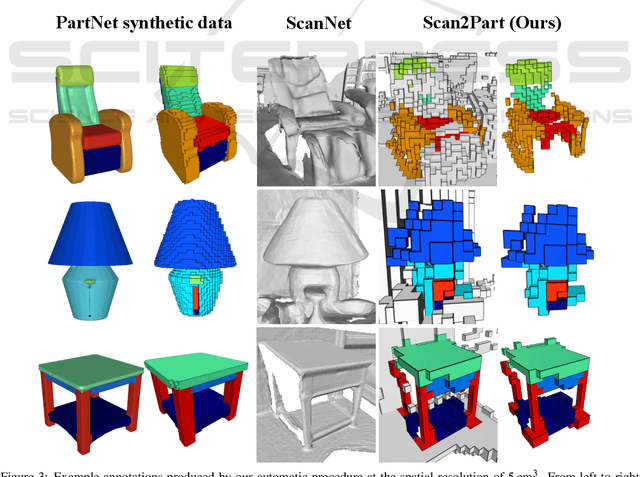
We propose Scan2Part, a method to segment individual parts of objects in real-world, noisy indoor RGB-D scans. To this end, we vary the part hierarchies of objects in indoor scenes and explore their effect on scene understanding models. Specifically, we use a sparse U-Net-based architecture that captures the fine-scale detail of the underlying 3D scan geometry by leveraging a multi-scale feature hierarchy. In order to train our method, we introduce the Scan2Part dataset, which is the first large-scale collection providing detailed semantic labels at the part level in the real-world setting. In total, we provide 242,081 correspondences between 53,618 PartNet parts of 2,477 ShapeNet objects and 1,506 ScanNet scenes, at two spatial resolutions of 2 cm$^3$ and 5 cm$^3$. As output, we are able to predict fine-grained per-object part labels, even when the geometry is coarse or partially missing.
Towards Part-Based Understanding of RGB-D Scans
Dec 03, 2020
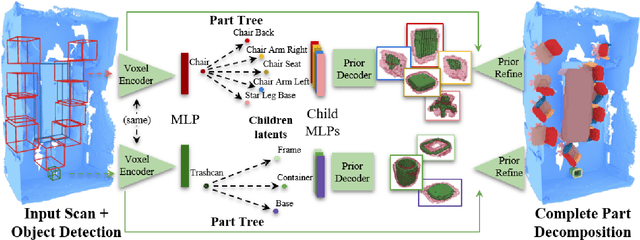

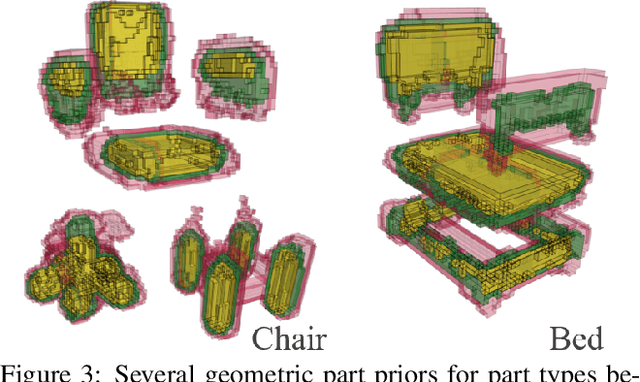
Recent advances in 3D semantic scene understanding have shown impressive progress in 3D instance segmentation, enabling object-level reasoning about 3D scenes; however, a finer-grained understanding is required to enable interactions with objects and their functional understanding. Thus, we propose the task of part-based scene understanding of real-world 3D environments: from an RGB-D scan of a scene, we detect objects, and for each object predict its decomposition into geometric part masks, which composed together form the complete geometry of the observed object. We leverage an intermediary part graph representation to enable robust completion as well as building of part priors, which we use to construct the final part mask predictions. Our experiments demonstrate that guiding part understanding through part graph to part prior-based predictions significantly outperforms alternative approaches to the task of semantic part completion.
Making DensePose fast and light
Jul 09, 2020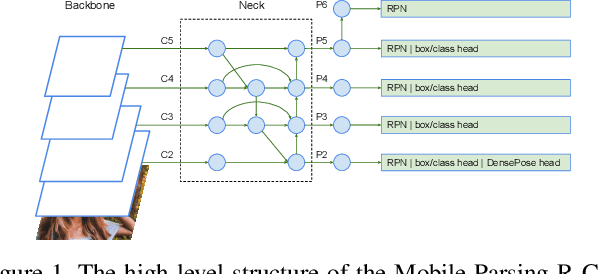
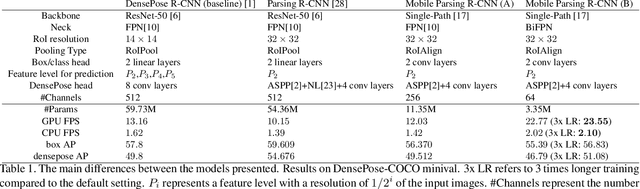
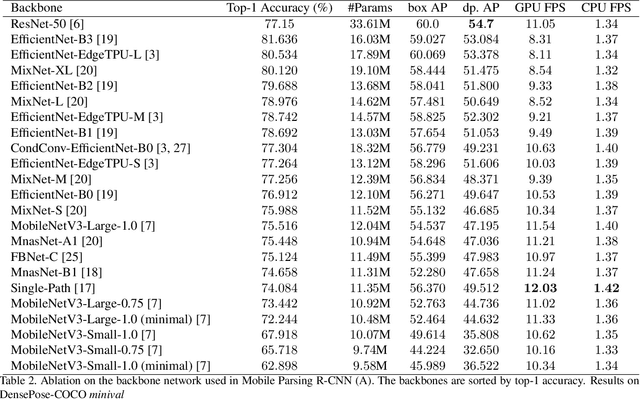
DensePose estimation task is a significant step forward for enhancing user experience computer vision applications ranging from augmented reality to cloth fitting. Existing neural network models capable of solving this task are heavily parameterized and a long way from being transferred to an embedded or mobile device. To enable Dense Pose inference on the end device with current models, one needs to support an expensive server-side infrastructure and have a stable internet connection. To make things worse, mobile and embedded devices do not always have a powerful GPU inside. In this work, we target the problem of redesigning the DensePose R-CNN model's architecture so that the final network retains most of its accuracy but becomes more light-weight and fast. To achieve that, we tested and incorporated many deep learning innovations from recent years, specifically performing an ablation study on 23 efficient backbone architectures, multiple two-stage detection pipeline modifications, and custom model quantization methods. As a result, we achieved $17\times$ model size reduction and $2\times$ latency improvement compared to the baseline model.