 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge or Search? A Study of LLM Agents in Hardware-Aware Code Optimization
May 19, 2026LLM discovery and optimization systems are increasingly applied across domains, implementing a common propose-evaluate-revise loop. Such optimization or discovery progresses via context conditioning on received feedback from an environment. However, as modern LLM agents are increasingly complex in their structure, it is difficult to evaluate which components contribute the most, and when and how this exploration may fail. We answer these questions through three controlled experiments. Our findings: (1) In pure black-box optimization, LLMs act as greedy optimizers. (2) In zero-shot kernel generation, providing explicit input-size information has no measurable effect, models converge to the same kernel parameters regardless of size or temperature, as though the size instruction were invisible. Moreover, when tasked to perform kernel optimization for uncommon kernel sizes, performance sharply degrades regardless of the language used. (3) In feedback-loop kernel optimization, CUDA improves monotonically under iterative feedback, while TVM IR actively degrades, which demonstrates that kernel optimization degrades when models operate with low-density language. Our results conclude that LLMs in code optimization tasks highly depend on pretrained priors rather than provided feedback or agentic structure.
PersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
May 13, 2026We introduce PersonalAI 2.0 (PAI-2), a novel framework, designed to enhance large language model (LLM) based systems through integration of external knowledge graphs (KG). The proposed approach addresses key limitations of existing Graph Retrieval-Augmented Generation (GraphRAG) methods by incorporating a dynamic, multistage query processing pipeline. The central point of PAI-2 design is its ability to perform adaptive, iterative information search, guided by extracted entities, matched graph vertices and generated clue-queries. Conducted evaluation over six benchmarks (Natural Questions, TriviaQA, HotpotQA, 2WikiMultihopQA, MuSiQue and DiaASQ) demonstrates improvement in factual correctness of generating answers compared to analogues methods (LightRAG, RAPTOR, and HippoRAG 2). PAI-2 achieves 4% average gain by LLM-as-a-Judge across four benchmarks, reflecting its effectiveness in reducing hallucination rates and increasing precision. We show that use of graph traversal algorithms (e.g. BeamSearch, WaterCircles) gain superior results compared to standard flatten retriever on average 6%, while enabled search plan enhancement mechanism gain 18% boost compared to disabled one by LLM-as-a-Judge across six datasets. In addition, ablation study reveals that PAI-2 achieves the SOTA result on MINE-1 benchmark, achieving 89% information-retention score, using LLMs from 7-14B tiers. Collectively, these findings underscore the potential of PAI-2 to serve as a foundational model for next-generation personalized AI applications, requiring scalable, context-aware knowledge representation and reasoning capabilities.
CADFS: A Big CAD Program Dataset and Framework for Computer-Aided Design with Large Language Models
May 03, 2026We introduce CADFS, a data-centric framework that enables large vision-language models to generate complex CAD design histories. Existing generative CAD systems are restricted to sketch-extrude operations due to simplified representations and limited datasets. We address this by introducing a FeatureScript-based representation and constructing a dataset of 450k real-world CAD models spanning 15 modeling operations. We obtain the dataset via a new pipeline that reconstructs clean, executable FeatureScript programs and provides multimodal annotations. Fine-tuning a VLM on this representation yields state-of-the-art results in text-conditioned CAD generation and image-based reconstruction, producing more accurate, diverse, and feature-rich designs than prior frameworks. Ablations show that each individual component of our framework, i.e., the FeatureScript representation, the extended operation set, and representation-aligned textual descriptions, significantly improves performance. Our framework substantially broadens the complexity and realism achievable in generative CAD. The CADFS framework and the new dataset are available at https://voyleg.github.io/cadfs/.
Variational Entropic Optimal Transport
Feb 02, 2026Entropic optimal transport (EOT) in continuous spaces with quadratic cost is a classical tool for solving the domain translation problem. In practice, recent approaches optimize a weak dual EOT objective depending on a single potential, but doing so is computationally not efficient due to the intractable log-partition term. Existing methods typically resolve this obstacle in one of two ways: by significantly restricting the transport family to obtain closed-form normalization (via Gaussian-mixture parameterizations), or by using general neural parameterizations that require simulation-based training procedures. We propose Variational Entropic Optimal Transport (VarEOT), based on an exact variational reformulation of the log-partition $\log \mathbb{E}[\exp(\cdot)]$ as a tractable minimization over an auxiliary positive normalizer. This yields a differentiable learning objective optimized with stochastic gradients and avoids the necessity of MCMC simulations during the training. We provide theoretical guarantees, including finite-sample generalization bounds and approximation results under universal function approximation. Experiments on synthetic data and unpaired image-to-image translation demonstrate competitive or improved translation quality, while comparisons within the solvers that use the same weak dual EOT objective support the benefit of the proposed optimization principle.
ATATA: One Algorithm to Align Them All
Jan 16, 2026We suggest a new multi-modal algorithm for joint inference of paired structurally aligned samples with Rectified Flow models. While some existing methods propose a codependent generation process, they do not view the problem of joint generation from a structural alignment perspective. Recent work uses Score Distillation Sampling to generate aligned 3D models, but SDS is known to be time-consuming, prone to mode collapse, and often provides cartoonish results. By contrast, our suggested approach relies on the joint transport of a segment in the sample space, yielding faster computation at inference time. Our approach can be built on top of an arbitrary Rectified Flow model operating on the structured latent space. We show the applicability of our method to the domains of image, video, and 3D shape generation using state-of-the-art baselines and evaluate it against both editing-based and joint inference-based competing approaches. We demonstrate a high degree of structural alignment for the sample pairs obtained with our method and a high visual quality of the samples. Our method improves the state-of-the-art for image and video generation pipelines. For 3D generation, it is able to show comparable quality while working orders of magnitude faster.
Edge-wise Topological Divergence Gaps: Guiding Search in Combinatorial Optimization
Dec 16, 2025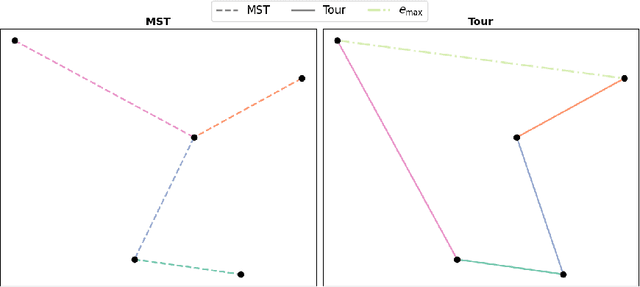
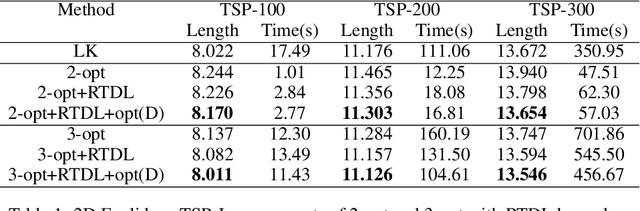
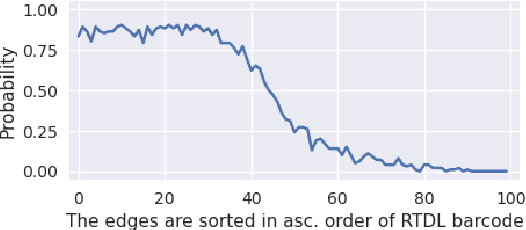
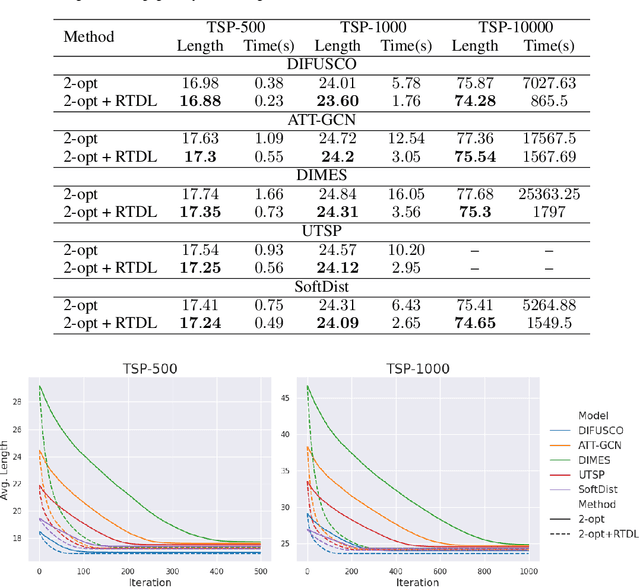
We introduce a topological feedback mechanism for the Travelling Salesman Problem (TSP) by analyzing the divergence between a tour and the minimum spanning tree (MST). Our key contribution is a canonical decomposition theorem that expresses the tour-MST gap as edge-wise topology-divergence gaps from the RTD-Lite barcode. Based on this, we develop a topological guidance for 2-opt and 3-opt heuristics that increases their performance. We carry out experiments with fine-optimization of tours obtained from heatmap-based methods, TSPLIB, and random instances. Experiments demonstrate the topology-guided optimization results in better performance and faster convergence in many cases.
Q-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training
Nov 10, 2025Retrieval-Augmented Generation (RAG) methods enhance LLM performance by efficiently filtering relevant context for LLMs, reducing hallucinations and inference cost. However, most existing RAG methods focus on single-step retrieval, which is often insufficient for answering complex questions that require multi-step search. Recently, multi-step retrieval approaches have emerged, typically involving the fine-tuning of small LLMs to perform multi-step retrieval. This type of fine-tuning is highly resource-intensive and does not enable the use of larger LLMs. In this work, we propose Q-RAG, a novel approach that fine-tunes the Embedder model for multi-step retrieval using reinforcement learning (RL). Q-RAG offers a competitive, resource-efficient alternative to existing multi-step retrieval methods for open-domain question answering and achieves state-of-the-art results on the popular long-context benchmarks Babilong and RULER for contexts up to 10M tokens.
Universal Inverse Distillation for Matching Models with Real-Data Supervision (No GANs)
Sep 26, 2025While achieving exceptional generative quality, modern diffusion, flow, and other matching models suffer from slow inference, as they require many steps of iterative generation. Recent distillation methods address this by training efficient one-step generators under the guidance of a pre-trained teacher model. However, these methods are often constrained to only one specific framework, e.g., only to diffusion or only to flow models. Furthermore, these methods are naturally data-free, and to benefit from the usage of real data, it is required to use an additional complex adversarial training with an extra discriminator model. In this paper, we present RealUID, a universal distillation framework for all matching models that seamlessly incorporates real data into the distillation procedure without GANs. Our RealUID approach offers a simple theoretical foundation that covers previous distillation methods for Flow Matching and Diffusion models, and is also extended to their modifications, such as Bridge Matching and Stochastic Interpolants.
Lightweight error mitigation strategies for post-training N:M activation sparsity in LLMs
Sep 26, 2025The demand for efficient large language model (LLM) inference has intensified the focus on sparsification techniques. While semi-structured (N:M) pruning is well-established for weights, its application to activation pruning remains underexplored despite its potential for dynamic, input-adaptive compression and reductions in I/O overhead. This work presents a comprehensive analysis of methods for post-training N:M activation pruning in LLMs. Across multiple LLMs, we demonstrate that pruning activations enables superior preservation of generative capabilities compared to weight pruning at equivalent sparsity levels. We evaluate lightweight, plug-and-play error mitigation techniques and pruning criteria, establishing strong hardware-friendly baselines that require minimal calibration. Furthermore, we explore sparsity patterns beyond NVIDIA's standard 2:4, showing that the 16:32 pattern achieves performance nearly on par with unstructured sparsity. However, considering the trade-off between flexibility and hardware implementation complexity, we focus on the 8:16 pattern as a superior candidate. Our findings provide both effective practical methods for activation pruning and a motivation for future hardware to support more flexible sparsity patterns. Our code is available https://anonymous.4open.science/r/Structured-Sparse-Activations-Inference-EC3C/README.md .
Risk-Averse Reinforcement Learning with Itakura-Saito Loss
May 22, 2025Risk-averse reinforcement learning finds application in various high-stakes fields. Unlike classical reinforcement learning, which aims to maximize expected returns, risk-averse agents choose policies that minimize risk, occasionally sacrificing expected value. These preferences can be framed through utility theory. We focus on the specific case of the exponential utility function, where we can derive the Bellman equations and employ various reinforcement learning algorithms with few modifications. However, these methods suffer from numerical instability due to the need for exponent computation throughout the process. To address this, we introduce a numerically stable and mathematically sound loss function based on the Itakura-Saito divergence for learning state-value and action-value functions. We evaluate our proposed loss function against established alternatives, both theoretically and empirically. In the experimental section, we explore multiple financial scenarios, some with known analytical solutions, and show that our loss function outperforms the alternatives.