 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-wise Topological Divergence Gaps: Guiding Search in Combinatorial Optimization
Dec 16, 2025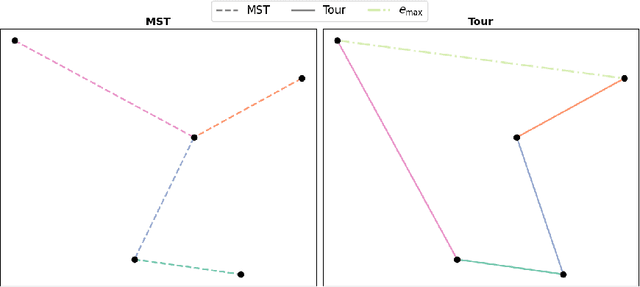
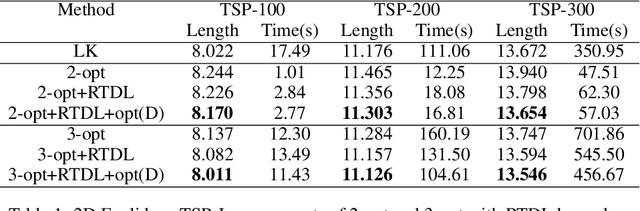
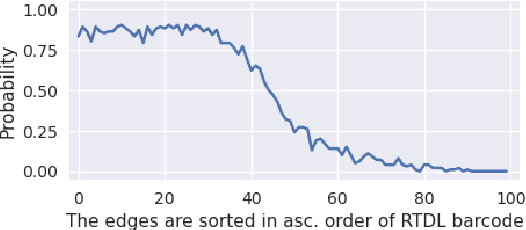
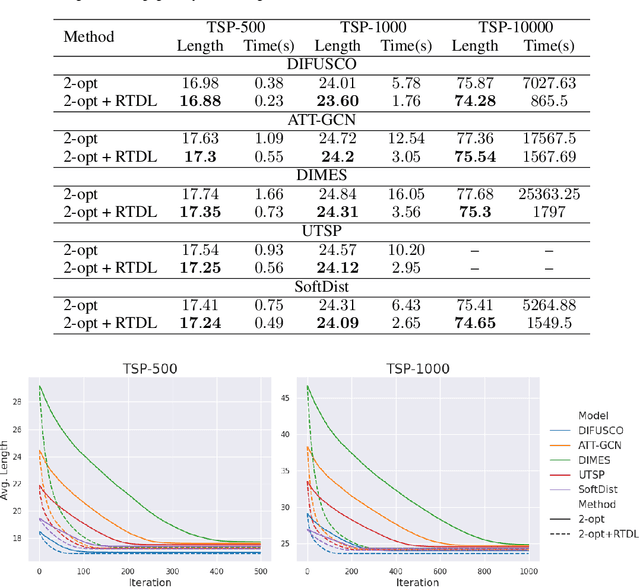
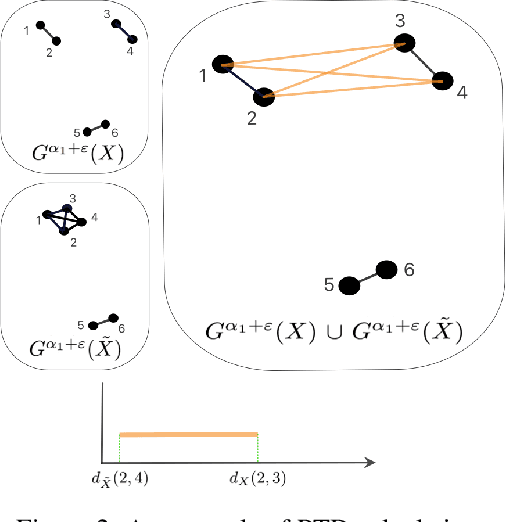
We introduce a topological feedback mechanism for the Travelling Salesman Problem (TSP) by analyzing the divergence between a tour and the minimum spanning tree (MST). Our key contribution is a canonical decomposition theorem that expresses the tour-MST gap as edge-wise topology-divergence gaps from the RTD-Lite barcode. Based on this, we develop a topological guidance for 2-opt and 3-opt heuristics that increases their performance. We carry out experiments with fine-optimization of tours obtained from heatmap-based methods, TSPLIB, and random instances. Experiments demonstrate the topology-guided optimization results in better performance and faster convergence in many cases.
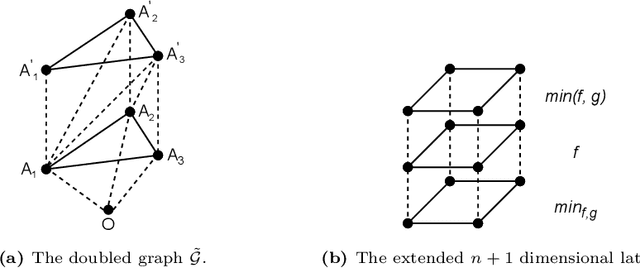
RTD-Lite: Scalable Topological Analysis for Comparing Weighted Graphs in Learning Tasks
Mar 14, 2025Topological methods for comparing weighted graphs are valuable in various learning tasks but often suffer from computational inefficiency on large datasets. We introduce RTD-Lite, a scalable algorithm that efficiently compares topological features, specifically connectivity or cluster structures at arbitrary scales, of two weighted graphs with one-to-one correspondence between vertices. Using minimal spanning trees in auxiliary graphs, RTD-Lite captures topological discrepancies with $O(n^2)$ time and memory complexity. This efficiency enables its application in tasks like dimensionality reduction and neural network training. Experiments on synthetic and real-world datasets demonstrate that RTD-Lite effectively identifies topological differences while significantly reducing computation time compared to existing methods. Moreover, integrating RTD-Lite into neural network training as a loss function component enhances the preservation of topological structures in learned representations. Our code is publicly available at https://github.com/ArGintum/RTD-Lite
Scalar Function Topology Divergence: Comparing Topology of 3D Objects
Jul 11, 2024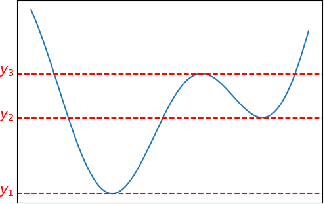


We propose a new topological tool for computer vision - Scalar Function Topology Divergence (SFTD), which measures the dissimilarity of multi-scale topology between sublevel sets of two functions having a common domain. Functions can be defined on an undirected graph or Euclidean space of any dimensionality. Most of the existing methods for comparing topology are based on Wasserstein distance between persistence barcodes and they don't take into account the localization of topological features. On the other hand, the minimization of SFTD ensures that the corresponding topological features of scalar functions are located in the same places. The proposed tool provides useful visualizations depicting areas where functions have topological dissimilarities. We provide applications of the proposed method to 3D computer vision. In particular, experiments demonstrate that SFTD improves the reconstruction of cellular 3D shapes from 2D fluorescence microscopy images, and helps to identify topological errors in 3D segmentation.
SeqNAS: Neural Architecture Search for Event Sequence Classification
Jan 06, 2024Neural Architecture Search (NAS) methods are widely used in various industries to obtain high quality taskspecific solutions with minimal human intervention. Event Sequences find widespread use in various industrial applications including churn prediction customer segmentation fraud detection and fault diagnosis among others. Such data consist of categorical and real-valued components with irregular timestamps. Despite the usefulness of NAS methods previous approaches only have been applied to other domains images texts or time series. Our work addresses this limitation by introducing a novel NAS algorithm SeqNAS specifically designed for event sequence classification. We develop a simple yet expressive search space that leverages commonly used building blocks for event sequence classification including multihead self attention convolutions and recurrent cells. To perform the search we adopt sequential Bayesian Optimization and utilize previously trained models as an ensemble of teachers to augment knowledge distillation. As a result of our work we demonstrate that our method surpasses state of the art NAS methods and popular architectures suitable for sequence classification and holds great potential for various industrial applications.
Disentanglement Learning via Topology
Aug 24, 2023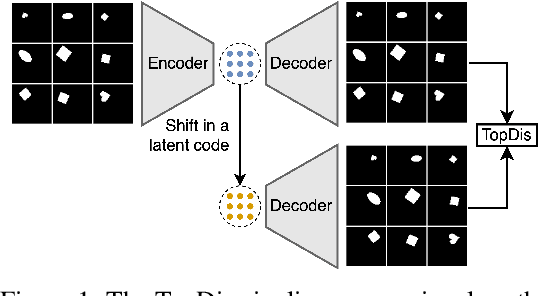
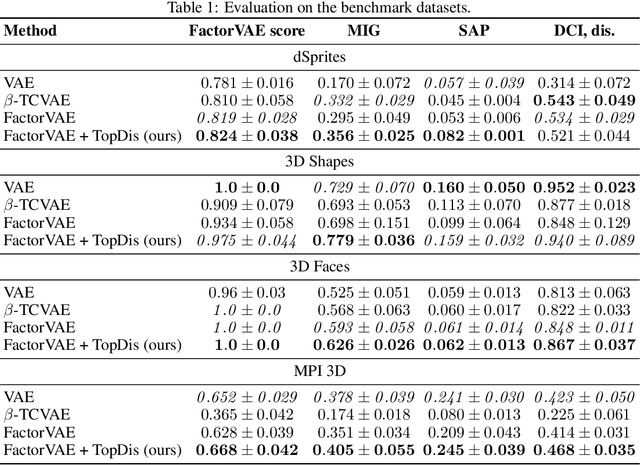
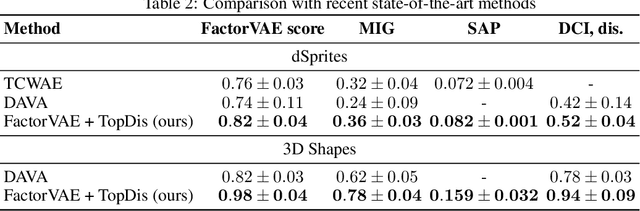
We propose TopDis (Topological Disentanglement), a method for learning disentangled representations via adding multi-scale topological loss term. Disentanglement is a crucial property of data representations substantial for the explainability and robustness of deep learning models and a step towards high-level cognition. The state-of-the-art method based on VAE minimizes the total correlation of the joint distribution of latent variables. We take a different perspective on disentanglement by analyzing topological properties of data manifolds. In particular, we optimize the topological similarity for data manifolds traversals. To the best of our knowledge, our paper is the first one to propose a differentiable topological loss for disentanglement. Our experiments have shown that the proposed topological loss improves disentanglement scores such as MIG, FactorVAE score, SAP score and DCI disentanglement score with respect to state-of-the-art results. Our method works in an unsupervised manner, permitting to apply it for problems without labeled factors of variation. Additionally, we show how to use the proposed topological loss to find disentangled directions in a trained GAN.
Learning Topology-Preserving Data Representations
Feb 15, 2023



We propose a method for learning topology-preserving data representations (dimensionality reduction). The method aims to provide topological similarity between the data manifold and its latent representation via enforcing the similarity in topological features (clusters, loops, 2D voids, etc.) and their localization. The core of the method is the minimization of the Representation Topology Divergence (RTD) between original high-dimensional data and low-dimensional representation in latent space. RTD minimization provides closeness in topological features with strong theoretical guarantees. We develop a scheme for RTD differentiation and apply it as a loss term for the autoencoder. The proposed method "RTD-AE" better preserves the global structure and topology of the data manifold than state-of-the-art competitors as measured by linear correlation, triplet distance ranking accuracy, and Wasserstein distance between persistence barcodes.
Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting
Oct 17, 2022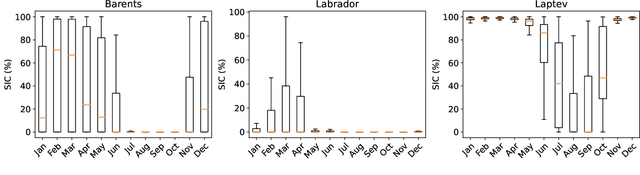
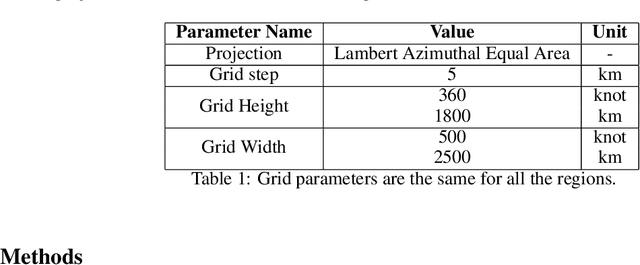
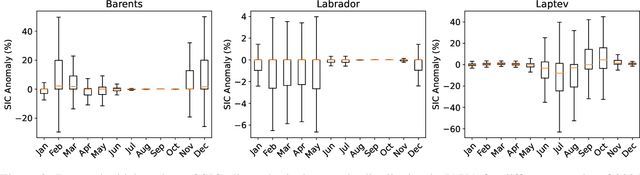

Global warming made the Arctic available for marine operations and created demand for reliable operational sea ice forecasts to make them safe. While ocean-ice numerical models are highly computationally intensive, relatively lightweight ML-based methods may be more efficient in this task. Many works have exploited different deep learning models alongside classical approaches for predicting sea ice concentration in the Arctic. However, only a few focus on daily operational forecasts and consider the real-time availability of data they need for operation. In this work, we aim to close this gap and investigate the performance of the U-Net model trained in two regimes for predicting sea ice for up to the next 10 days. We show that this deep learning model can outperform simple baselines by a significant margin and improve its quality by using additional weather data and training on multiple regions, ensuring its generalization abilities. As a practical outcome, we build a fast and flexible tool that produces operational sea ice forecasts in the Barents Sea, the Labrador Sea, and the Laptev Sea regions.
QuantNAS for super resolution: searching for efficient quantization-friendly architectures against quantization noise
Aug 31, 2022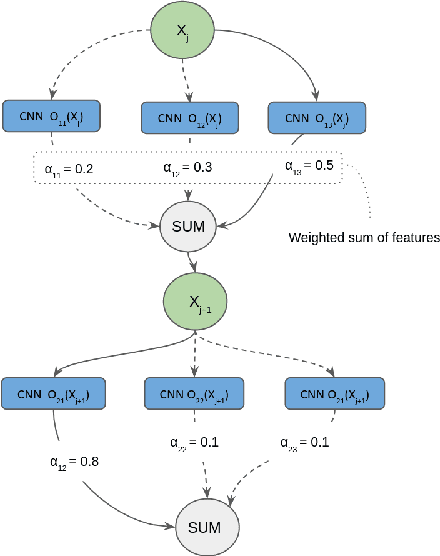
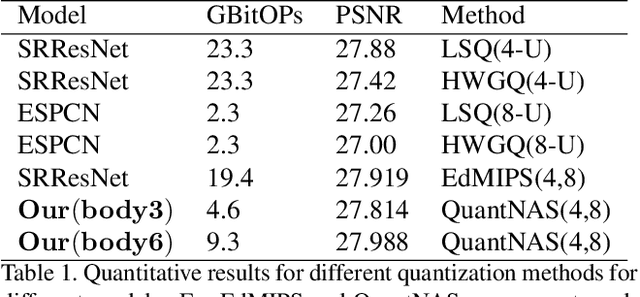
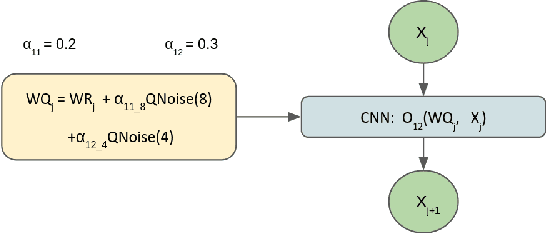
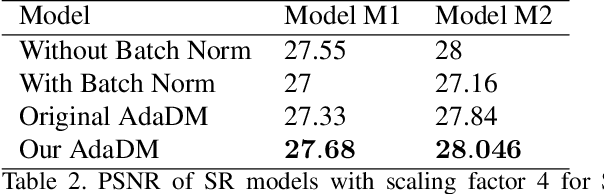
There is a constant need for high-performing and computationally efficient neural network models for image super-resolution (SR) often used on low-capacity devices. One way to obtain such models is to compress existing architectures, e.g. quantization. Another option is a neural architecture search (NAS) that discovers new efficient solutions. We propose a novel quantization-aware NAS procedure for a specifically designed SR search space. Our approach performs NAS to find quantization-friendly SR models. The search relies on adding quantization noise to parameters and activations instead of quantizing parameters directly. Our QuantNAS finds architectures with better PSNR/BitOps trade-off than uniform or mixed precision quantization of fixed architectures. Additionally, our search against noise procedure is up to 30% faster than directly quantizing weights.
Representation Topology Divergence: A Method for Comparing Neural Network Representations
Dec 31, 2021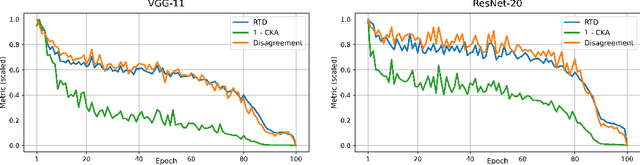


Comparison of data representations is a complex multi-aspect problem that has not enjoyed a complete solution yet. We propose a method for comparing two data representations. We introduce the Representation Topology Divergence (RTD), measuring the dissimilarity in multi-scale topology between two point clouds of equal size with a one-to-one correspondence between points. The data point clouds are allowed to lie in different ambient spaces. The RTD is one of the few TDA-based practical methods applicable to real machine learning datasets. Experiments show that the proposed RTD agrees with the intuitive assessment of data representation similarity and is sensitive to its topological structure. We apply RTD to gain insights on neural networks representations in computer vision and NLP domains for various problems: training dynamics analysis, data distribution shift, transfer learning, ensemble learning, disentanglement assessment.
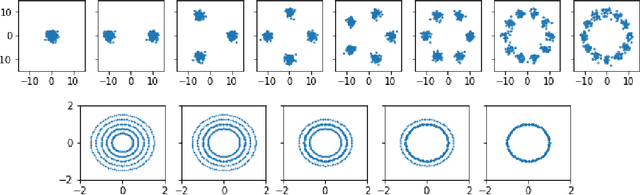
Manifold Topology Divergence: a Framework for Comparing Data Manifolds
Jun 08, 2021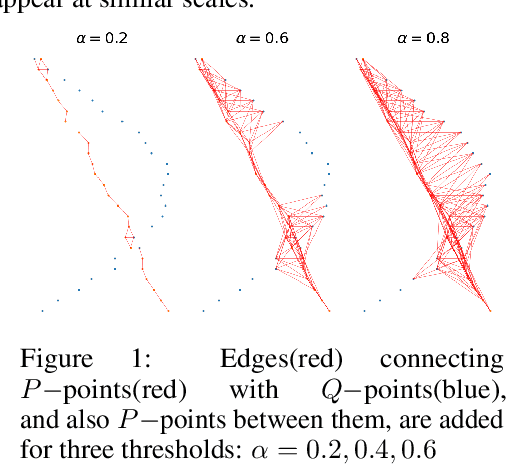
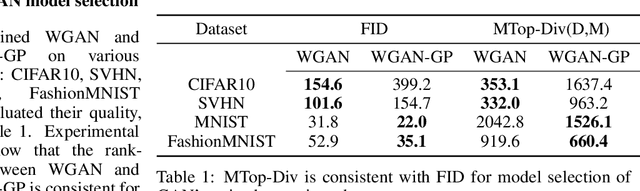
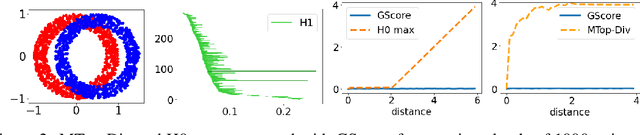
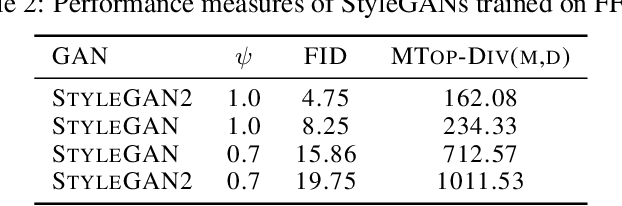
We develop a framework for comparing data manifolds, aimed, in particular, towards the evaluation of deep generative models. We describe a novel tool, Cross-Barcode(P,Q), that, given a pair of distributions in a high-dimensional space, tracks multiscale topology spacial discrepancies between manifolds on which the distributions are concentrated. Based on the Cross-Barcode, we introduce the Manifold Topology Divergence score (MTop-Divergence) and apply it to assess the performance of deep generative models in various domains: images, 3D-shapes, time-series, and on different datasets: MNIST, Fashion MNIST, SVHN, CIFAR10, FFHQ, chest X-ray images, market stock data, ShapeNet. We demonstrate that the MTop-Divergence accurately detects various degrees of mode-dropping, intra-mode collapse, mode invention, and image disturbance. Our algorithm scales well (essentially linearly) with the increase of the dimension of the ambient high-dimensional space. It is one of the first TDA-based practical methodologies that can be applied universally to datasets of different sizes and dimensions, including the ones on which the most recent GANs in the visual domain are trained. The proposed method is domain agnostic and does not rely on pre-trained networks.