 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepQ: Generalizing Quantization-Aware Training for Re-Parametrized Architectures
Nov 09, 2023



Existing neural networks are memory-consuming and computationally intensive, making deploying them challenging in resource-constrained environments. However, there are various methods to improve their efficiency. Two such methods are quantization, a well-known approach for network compression, and re-parametrization, an emerging technique designed to improve model performance. Although both techniques have been studied individually, there has been limited research on their simultaneous application. To address this gap, we propose a novel approach called RepQ, which applies quantization to re-parametrized networks. Our method is based on the insight that the test stage weights of an arbitrary re-parametrized layer can be presented as a differentiable function of trainable parameters. We enable quantization-aware training by applying quantization on top of this function. RepQ generalizes well to various re-parametrized models and outperforms the baseline method LSQ quantization scheme in all experiments.
QuantNAS for super resolution: searching for efficient quantization-friendly architectures against quantization noise
Aug 31, 2022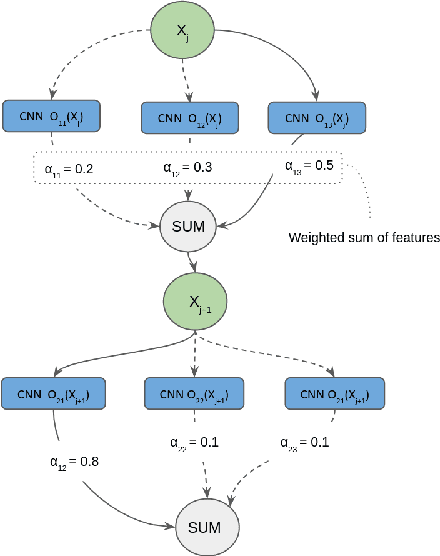
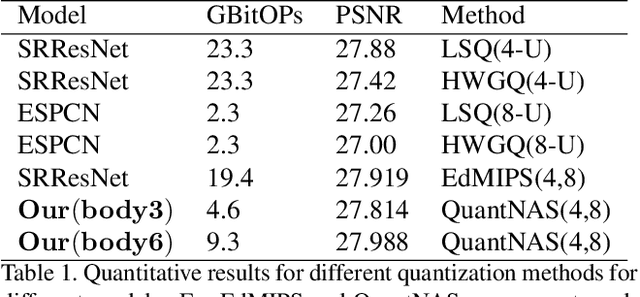
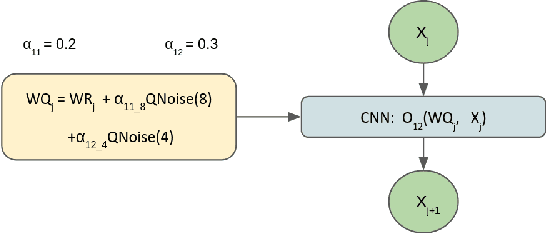
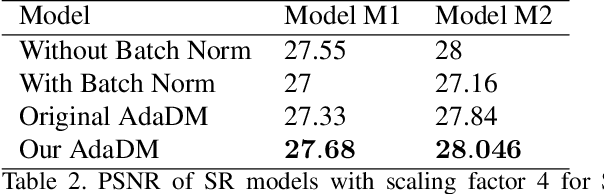
There is a constant need for high-performing and computationally efficient neural network models for image super-resolution (SR) often used on low-capacity devices. One way to obtain such models is to compress existing architectures, e.g. quantization. Another option is a neural architecture search (NAS) that discovers new efficient solutions. We propose a novel quantization-aware NAS procedure for a specifically designed SR search space. Our approach performs NAS to find quantization-friendly SR models. The search relies on adding quantization noise to parameters and activations instead of quantizing parameters directly. Our QuantNAS finds architectures with better PSNR/BitOps trade-off than uniform or mixed precision quantization of fixed architectures. Additionally, our search against noise procedure is up to 30% faster than directly quantizing weights.