 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepQ: Generalizing Quantization-Aware Training for Re-Parametrized Architectures
Nov 09, 2023



Existing neural networks are memory-consuming and computationally intensive, making deploying them challenging in resource-constrained environments. However, there are various methods to improve their efficiency. Two such methods are quantization, a well-known approach for network compression, and re-parametrization, an emerging technique designed to improve model performance. Although both techniques have been studied individually, there has been limited research on their simultaneous application. To address this gap, we propose a novel approach called RepQ, which applies quantization to re-parametrized networks. Our method is based on the insight that the test stage weights of an arbitrary re-parametrized layer can be presented as a differentiable function of trainable parameters. We enable quantization-aware training by applying quantization on top of this function. RepQ generalizes well to various re-parametrized models and outperforms the baseline method LSQ quantization scheme in all experiments.
Differentiable Channel Pruning Search
Oct 28, 2020
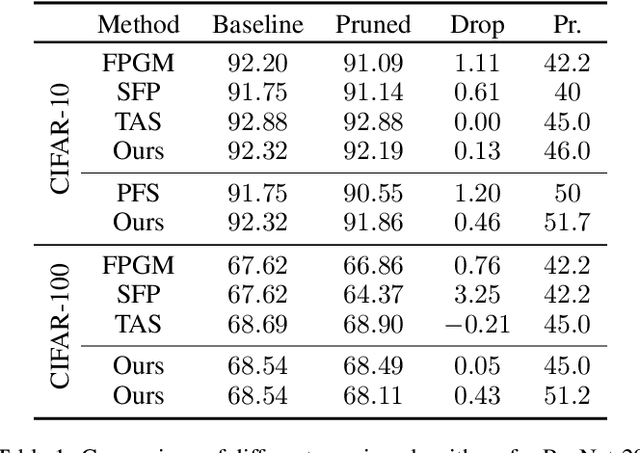
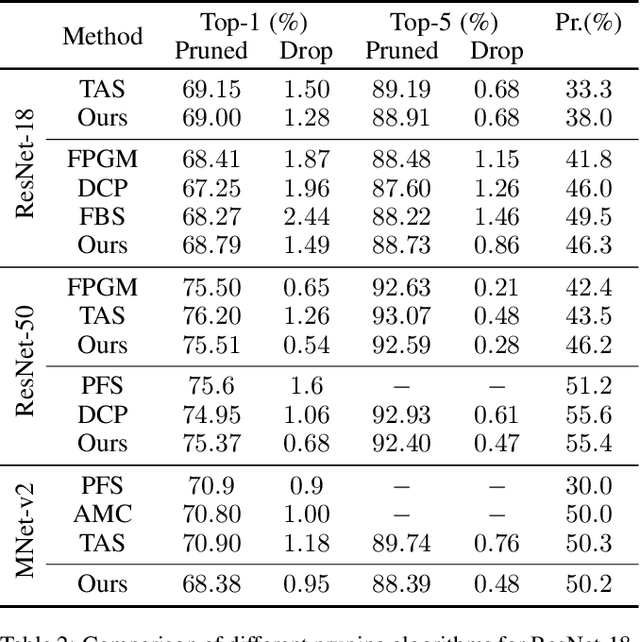
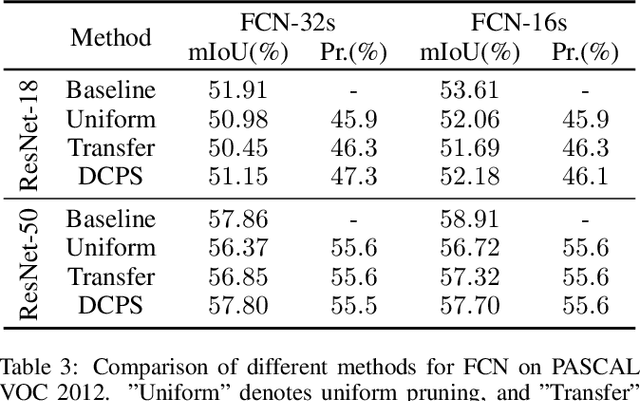
In this paper, we propose the differentiable channel pruning search (DCPS) of convolutional neural networks. Unlike traditional channel pruning algorithms which require users to manually set prune ratio for each convolutional layer, DCPS search the optimal combination of prune ratio that automatically. Inspired by the differentiable architecture search (DARTS), we draws lessons from the continuous relaxation and leverages the gradient information to balance the metrics and performance. However, directly applying the DARTS scheme will cause channel mismatching problem and huge memory consumption. Therefore, we introduce a novel weight sharing technique which can elegantly eliminate the shape mismatching problem with negligible additional resource. We test the proposed algorithm on image classification task and it achieves the state-of-the-art pruning results for image classification on CIFAR-10, CIFAR-100 and ImageNet. DCPS is further utilized for semantic segmentation on PASCAL VOC 2012 for two purposes. The first is to demonstrate that task-specific channel pruning achieves better performance against transferring slim models, and the second is to prove the memory efficiency of DCPS as the task demand more memory budget than classification. Results of the experiments validate the effectiveness and wide applicability of DCPS.