 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Short-Term Daily Operational Sea Ice Regional Forecasting
Oct 17, 2022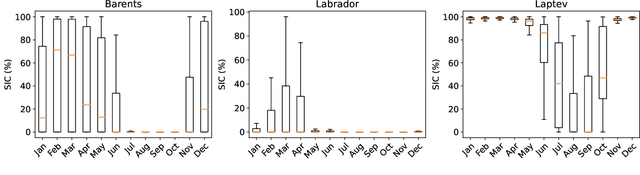
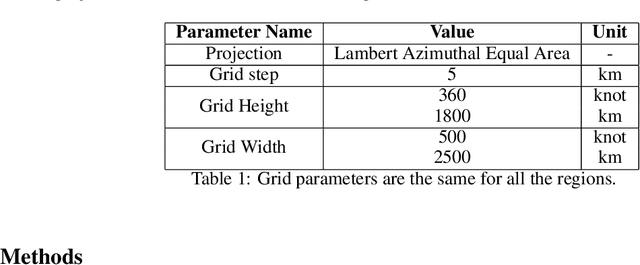
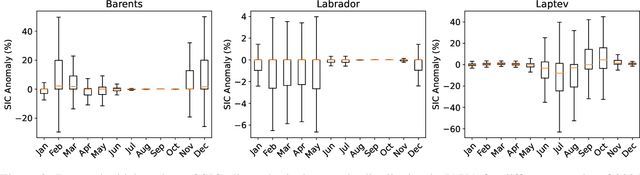

Global warming made the Arctic available for marine operations and created demand for reliable operational sea ice forecasts to make them safe. While ocean-ice numerical models are highly computationally intensive, relatively lightweight ML-based methods may be more efficient in this task. Many works have exploited different deep learning models alongside classical approaches for predicting sea ice concentration in the Arctic. However, only a few focus on daily operational forecasts and consider the real-time availability of data they need for operation. In this work, we aim to close this gap and investigate the performance of the U-Net model trained in two regimes for predicting sea ice for up to the next 10 days. We show that this deep learning model can outperform simple baselines by a significant margin and improve its quality by using additional weather data and training on multiple regions, ensuring its generalization abilities. As a practical outcome, we build a fast and flexible tool that produces operational sea ice forecasts in the Barents Sea, the Labrador Sea, and the Laptev Sea regions.
When, Why, and Which Pretrained GANs Are Useful?
Mar 10, 2022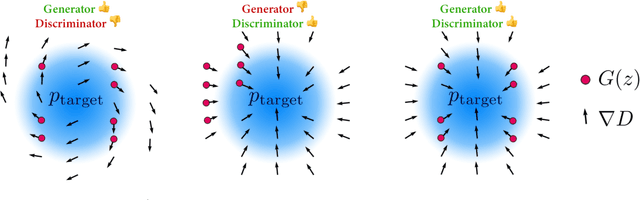



The literature has proposed several methods to finetune pretrained GANs on new datasets, which typically results in higher performance compared to training from scratch, especially in the limited-data regime. However, despite the apparent empirical benefits of GAN pretraining, its inner mechanisms were not analyzed in-depth, and understanding of its role is not entirely clear. Moreover, the essential practical details, e.g., selecting a proper pretrained GAN checkpoint, currently do not have rigorous grounding and are typically determined by trial and error. This work aims to dissect the process of GAN finetuning. First, we show that initializing the GAN training process by a pretrained checkpoint primarily affects the model's coverage rather than the fidelity of individual samples. Second, we explicitly describe how pretrained generators and discriminators contribute to the finetuning process and explain the previous evidence on the importance of pretraining both of them. Finally, as an immediate practical benefit of our analysis, we describe a simple recipe to choose an appropriate GAN checkpoint that is the most suitable for finetuning to a particular target task. Importantly, for most of the target tasks, Imagenet-pretrained GAN, despite having poor visual quality, appears to be an excellent starting point for finetuning, resembling the typical pretraining scenario of discriminative computer vision models.
Category-Learning with Context-Augmented Autoencoder
Oct 10, 2020
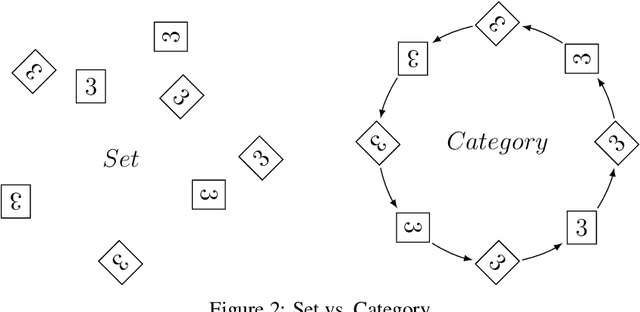
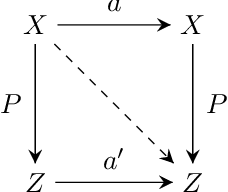
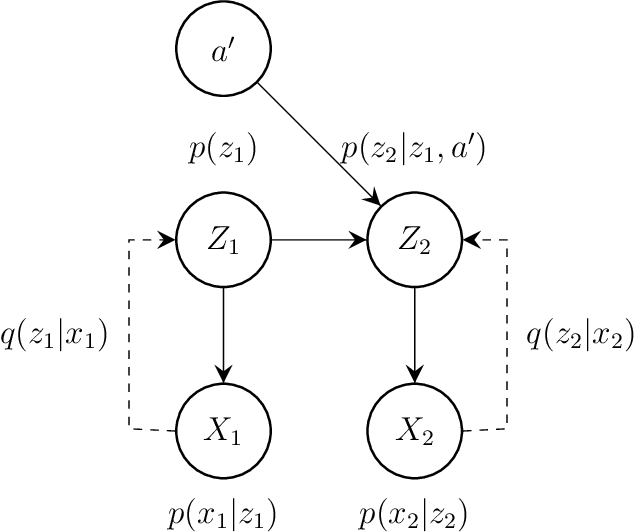
Finding an interpretable non-redundant representation of real-world data is one of the key problems in Machine Learning. Biological neural networks are known to solve this problem quite well in unsupervised manner, yet unsupervised artificial neural networks either struggle to do it or require fine tuning for each task individually. We associate this with the fact that a biological brain learns in the context of the relationships between observations, while an artificial network does not. We also notice that, though a naive data augmentation technique can be very useful for supervised learning problems, autoencoders typically fail to generalize transformations from data augmentations. Thus, we believe that providing additional knowledge about relationships between data samples will improve model's capability of finding useful inner data representation. More formally, we consider a dataset not as a manifold, but as a category, where the examples are objects. Two these objects are connected by a morphism, if they actually represent different transformations of the same entity. Following this formalism, we propose a novel method of using data augmentations when training autoencoders. We train a Variational Autoencoder in such a way, that it makes transformation outcome predictable by auxiliary network in terms of the hidden representation. We believe that the classification accuracy of a linear classifier on the learned representation is a good metric to measure its interpretability. In our experiments, present approach outperforms $\beta$-VAE and is comparable with Gaussian-mixture VAE.
* 11 pages, 12 figures