 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Autoregressive Models for Generative Image Classification
Mar 19, 2026Class-conditional generative models have emerged as accurate and robust classifiers, with diffusion models demonstrating clear advantages over other visual generative paradigms, including autoregressive (AR) models. In this work, we revisit visual AR-based generative classifiers and identify an important limitation of prior approaches: their reliance on a fixed token order, which imposes a restrictive inductive bias for image understanding. We observe that single-order predictions rely more on partial discriminative cues, while averaging over multiple token orders provides a more comprehensive signal. Based on this insight, we leverage recent any-order AR models to estimate order-marginalized predictions, unlocking the high classification potential of AR models. Our approach consistently outperforms diffusion-based classifiers across diverse image classification benchmarks, while being up to 25x more efficient. Compared to state-of-the-art self-supervised discriminative models, our method delivers competitive classification performance - a notable achievement for generative classifiers.
Unveiling the Role of Data Uncertainty in Tabular Deep Learning
Sep 04, 2025


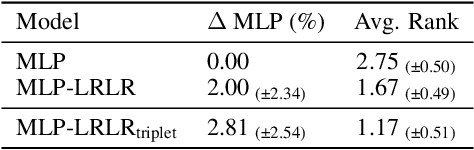
Recent advancements in tabular deep learning have demonstrated exceptional practical performance, yet the field often lacks a clear understanding of why these techniques actually succeed. To address this gap, our paper highlights the importance of the concept of data uncertainty for explaining the effectiveness of the recent tabular DL methods. In particular, we reveal that the success of many beneficial design choices in tabular DL, such as numerical feature embeddings, retrieval-augmented models and advanced ensembling strategies, can be largely attributed to their implicit mechanisms for managing high data uncertainty. By dissecting these mechanisms, we provide a unifying understanding of the recent performance improvements. Furthermore, the insights derived from this data-uncertainty perspective directly allowed us to develop more effective numerical feature embeddings as an immediate practical outcome of our analysis. Overall, our work paves the way to foundational understanding of the benefits introduced by modern tabular methods that results in the concrete advancements of existing techniques and outlines future research directions for tabular DL.
Turning Tabular Foundation Models into Graph Foundation Models
Aug 28, 2025While foundation models have revolutionized such fields as natural language processing and computer vision, their application and potential within graph machine learning remain largely unexplored. One of the key challenges in designing graph foundation models (GFMs) is handling diverse node features that can vary across different graph datasets. Although many works on GFMs have been focused exclusively on text-attributed graphs, the problem of handling arbitrary features of other types in GFMs has not been fully addressed. However, this problem is not unique to the graph domain, as it also arises in the field of machine learning for tabular data. In this work, motivated by the recent success of tabular foundation models like TabPFNv2, we propose G2T-FM, a simple graph foundation model that employs TabPFNv2 as a backbone. Specifically, G2T-FM augments the original node features with neighborhood feature aggregation, adds structural embeddings, and then applies TabPFNv2 to the constructed node representations. Even in a fully in-context regime, our model achieves strong results, significantly outperforming publicly available GFMs and performing on par with well-tuned GNNs trained from scratch. Moreover, after finetuning, G2T-FM surpasses well-tuned GNN baselines, highlighting the potential of the proposed approach. More broadly, our paper reveals a previously overlooked direction of utilizing tabular foundation models for graph machine learning tasks.
On Finetuning Tabular Foundation Models
Jun 11, 2025



Foundation models are an emerging research direction in tabular deep learning. Notably, TabPFNv2 recently claimed superior performance over traditional GBDT-based methods on small-scale datasets using an in-context learning paradigm, which does not adapt model parameters to target datasets. However, the optimal finetuning approach for adapting tabular foundational models, and how this adaptation reshapes their internal mechanisms, remains underexplored. While prior works studied finetuning for earlier foundational models, inconsistent findings and TabPFNv2's unique architecture necessitate fresh investigation. To address these questions, we first systematically evaluate various finetuning strategies on diverse datasets. Our findings establish full finetuning as the most practical solution for TabPFNv2 in terms of time-efficiency and effectiveness. We then investigate how finetuning alters TabPFNv2's inner mechanisms, drawing an analogy to retrieval-augmented models. We reveal that the success of finetuning stems from the fact that after gradient-based adaptation, the dot products of the query-representations of test objects and the key-representations of in-context training objects more accurately reflect their target similarity. This improved similarity allows finetuned TabPFNv2 to better approximate target dependency by appropriately weighting relevant in-context samples, improving the retrieval-based prediction logic. From the practical perspective, we managed to finetune TabPFNv2 on datasets with up to 50K objects, observing performance improvements on almost all tasks. More precisely, on academic datasets with I.I.D. splits, finetuning allows TabPFNv2 to achieve state-of-the-art results, while on datasets with gradual temporal shifts and rich feature sets, TabPFNv2 is less stable and prior methods remain better.
Scale-wise Distillation of Diffusion Models
Mar 20, 2025



We present SwD, a scale-wise distillation framework for diffusion models (DMs), which effectively employs next-scale prediction ideas for diffusion-based few-step generators. In more detail, SwD is inspired by the recent insights relating diffusion processes to the implicit spectral autoregression. We suppose that DMs can initiate generation at lower data resolutions and gradually upscale the samples at each denoising step without loss in performance while significantly reducing computational costs. SwD naturally integrates this idea into existing diffusion distillation methods based on distribution matching. Also, we enrich the family of distribution matching approaches by introducing a novel patch loss enforcing finer-grained similarity to the target distribution. When applied to state-of-the-art text-to-image diffusion models, SwD approaches the inference times of two full resolution steps and significantly outperforms the counterparts under the same computation budget, as evidenced by automated metrics and human preference studies.
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
Oct 31, 2024
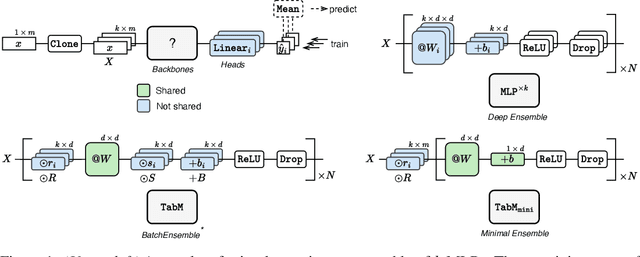
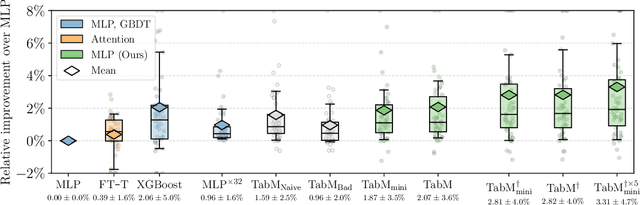

Deep learning architectures for supervised learning on tabular data range from simple multilayer perceptrons (MLP) to sophisticated Transformers and retrieval-augmented methods. This study highlights a major, yet so far overlooked opportunity for substantially improving tabular MLPs: namely, parameter-efficient ensembling -- a paradigm for implementing an ensemble of models as one model producing multiple predictions. We start by developing TabM -- a simple model based on MLP and our variations of BatchEnsemble (an existing technique). Then, we perform a large-scale evaluation of tabular DL architectures on public benchmarks in terms of both task performance and efficiency, which renders the landscape of tabular DL in a new light. Generally, we show that MLPs, including TabM, form a line of stronger and more practical models compared to attention- and retrieval-based architectures. In particular, we find that TabM demonstrates the best performance among tabular DL models. Lastly, we conduct an empirical analysis on the ensemble-like nature of TabM. For example, we observe that the multiple predictions of TabM are weak individually, but powerful collectively. Overall, our work brings an impactful technique to tabular DL, analyses its behaviour, and advances the performance-efficiency trade-off with TabM -- a simple and powerful baseline for researchers and practitioners.
TabReD: A Benchmark of Tabular Machine Learning in-the-Wild
Jun 27, 2024



Benchmarks that closely reflect downstream application scenarios are essential for the streamlined adoption of new research in tabular machine learning (ML). In this work, we examine existing tabular benchmarks and find two common characteristics of industry-grade tabular data that are underrepresented in the datasets available to the academic community. First, tabular data often changes over time in real-world deployment scenarios. This impacts model performance and requires time-based train and test splits for correct model evaluation. Yet, existing academic tabular datasets often lack timestamp metadata to enable such evaluation. Second, a considerable portion of datasets in production settings stem from extensive data acquisition and feature engineering pipelines. For each specific dataset, this can have a different impact on the absolute and relative number of predictive, uninformative, and correlated features, which in turn can affect model selection. To fill the aforementioned gaps in academic benchmarks, we introduce TabReD -- a collection of eight industry-grade tabular datasets covering a wide range of domains from finance to food delivery services. We assess a large number of tabular ML models in the feature-rich, temporally-evolving data setting facilitated by TabReD. We demonstrate that evaluation on time-based data splits leads to different methods ranking, compared to evaluation on random splits more common in academic benchmarks. Furthermore, on the TabReD datasets, MLP-like architectures and GBDT show the best results, while more sophisticated DL models are yet to prove their effectiveness.
Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps
Jun 20, 2024
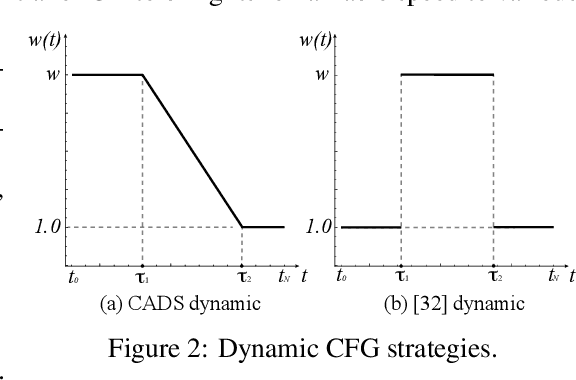


Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3-4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
YaART: Yet Another ART Rendering Technology
Apr 08, 2024



In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024



This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.