 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Role of Data Uncertainty in Tabular Deep Learning
Sep 04, 2025Recent advancements in tabular deep learning have demonstrated exceptional practical performance, yet the field often lacks a clear understanding of why these techniques actually succeed. To address this gap, our paper highlights the importance of the concept of data uncertainty for explaining the effectiveness of the recent tabular DL methods. In particular, we reveal that the success of many beneficial design choices in tabular DL, such as numerical feature embeddings, retrieval-augmented models and advanced ensembling strategies, can be largely attributed to their implicit mechanisms for managing high data uncertainty. By dissecting these mechanisms, we provide a unifying understanding of the recent performance improvements. Furthermore, the insights derived from this data-uncertainty perspective directly allowed us to develop more effective numerical feature embeddings as an immediate practical outcome of our analysis. Overall, our work paves the way to foundational understanding of the benefits introduced by modern tabular methods that results in the concrete advancements of existing techniques and outlines future research directions for tabular DL.
On Finetuning Tabular Foundation Models
Jun 11, 2025



Foundation models are an emerging research direction in tabular deep learning. Notably, TabPFNv2 recently claimed superior performance over traditional GBDT-based methods on small-scale datasets using an in-context learning paradigm, which does not adapt model parameters to target datasets. However, the optimal finetuning approach for adapting tabular foundational models, and how this adaptation reshapes their internal mechanisms, remains underexplored. While prior works studied finetuning for earlier foundational models, inconsistent findings and TabPFNv2's unique architecture necessitate fresh investigation. To address these questions, we first systematically evaluate various finetuning strategies on diverse datasets. Our findings establish full finetuning as the most practical solution for TabPFNv2 in terms of time-efficiency and effectiveness. We then investigate how finetuning alters TabPFNv2's inner mechanisms, drawing an analogy to retrieval-augmented models. We reveal that the success of finetuning stems from the fact that after gradient-based adaptation, the dot products of the query-representations of test objects and the key-representations of in-context training objects more accurately reflect their target similarity. This improved similarity allows finetuned TabPFNv2 to better approximate target dependency by appropriately weighting relevant in-context samples, improving the retrieval-based prediction logic. From the practical perspective, we managed to finetune TabPFNv2 on datasets with up to 50K objects, observing performance improvements on almost all tasks. More precisely, on academic datasets with I.I.D. splits, finetuning allows TabPFNv2 to achieve state-of-the-art results, while on datasets with gradual temporal shifts and rich feature sets, TabPFNv2 is less stable and prior methods remain better.
TabReD: A Benchmark of Tabular Machine Learning in-the-Wild
Jun 27, 2024



Benchmarks that closely reflect downstream application scenarios are essential for the streamlined adoption of new research in tabular machine learning (ML). In this work, we examine existing tabular benchmarks and find two common characteristics of industry-grade tabular data that are underrepresented in the datasets available to the academic community. First, tabular data often changes over time in real-world deployment scenarios. This impacts model performance and requires time-based train and test splits for correct model evaluation. Yet, existing academic tabular datasets often lack timestamp metadata to enable such evaluation. Second, a considerable portion of datasets in production settings stem from extensive data acquisition and feature engineering pipelines. For each specific dataset, this can have a different impact on the absolute and relative number of predictive, uninformative, and correlated features, which in turn can affect model selection. To fill the aforementioned gaps in academic benchmarks, we introduce TabReD -- a collection of eight industry-grade tabular datasets covering a wide range of domains from finance to food delivery services. We assess a large number of tabular ML models in the feature-rich, temporally-evolving data setting facilitated by TabReD. We demonstrate that evaluation on time-based data splits leads to different methods ranking, compared to evaluation on random splits more common in academic benchmarks. Furthermore, on the TabReD datasets, MLP-like architectures and GBDT show the best results, while more sophisticated DL models are yet to prove their effectiveness.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).
TabDDPM: Modelling Tabular Data with Diffusion Models
Sep 30, 2022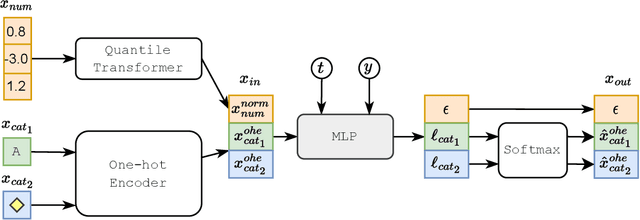
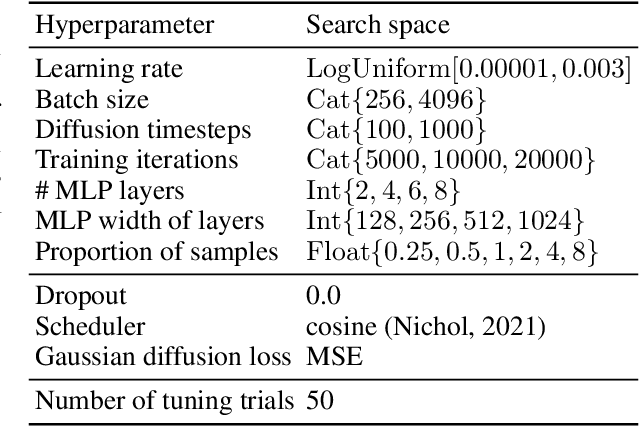
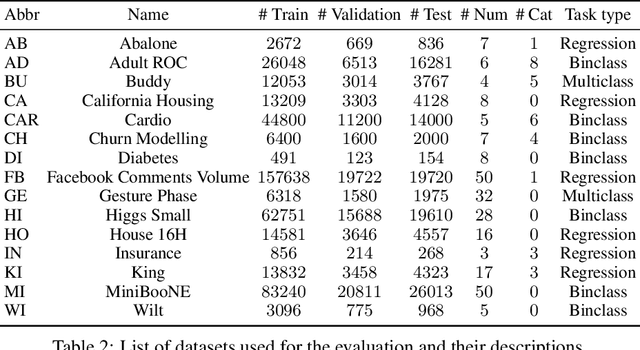
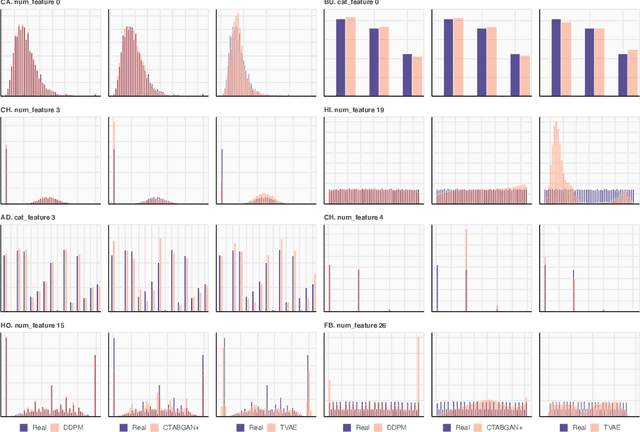
Denoising diffusion probabilistic models are currently becoming the leading paradigm of generative modeling for many important data modalities. Being the most prevalent in the computer vision community, diffusion models have also recently gained some attention in other domains, including speech, NLP, and graph-like data. In this work, we investigate if the framework of diffusion models can be advantageous for general tabular problems, where datapoints are typically represented by vectors of heterogeneous features. The inherent heterogeneity of tabular data makes it quite challenging for accurate modeling, since the individual features can be of completely different nature, i.e., some of them can be continuous and some of them can be discrete. To address such data types, we introduce TabDDPM -- a diffusion model that can be universally applied to any tabular dataset and handles any type of feature. We extensively evaluate TabDDPM on a wide set of benchmarks and demonstrate its superiority over existing GAN/VAE alternatives, which is consistent with the advantage of diffusion models in other fields. Additionally, we show that TabDDPM is eligible for privacy-oriented setups, where the original datapoints cannot be publicly shared.
Revisiting Pretraining Objectives for Tabular Deep Learning
Jul 12, 2022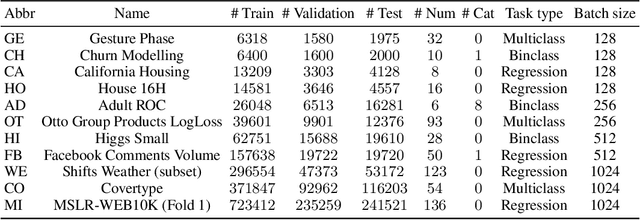
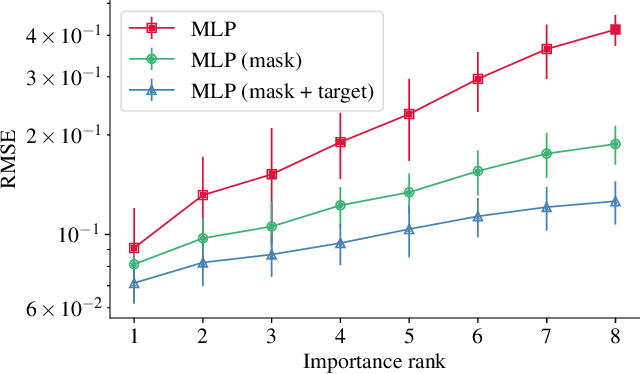
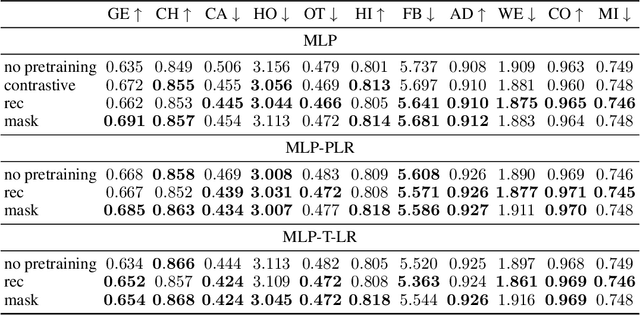
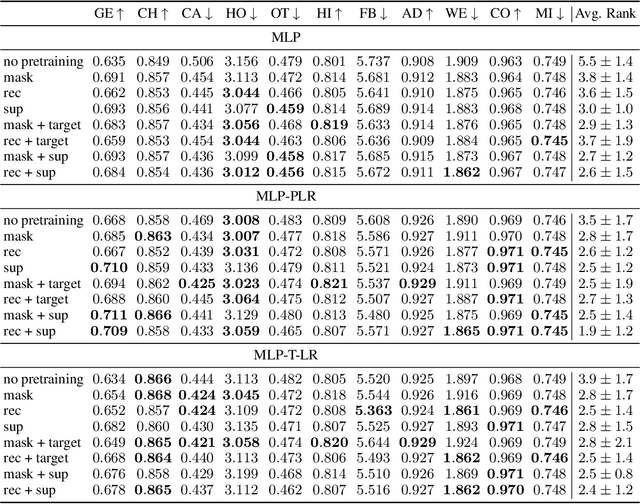
Recent deep learning models for tabular data currently compete with the traditional ML models based on decision trees (GBDT). Unlike GBDT, deep models can additionally benefit from pretraining, which is a workhorse of DL for vision and NLP. For tabular problems, several pretraining methods were proposed, but it is not entirely clear if pretraining provides consistent noticeable improvements and what method should be used, since the methods are often not compared to each other or comparison is limited to the simplest MLP architectures. In this work, we aim to identify the best practices to pretrain tabular DL models that can be universally applied to different datasets and architectures. Among our findings, we show that using the object target labels during the pretraining stage is beneficial for the downstream performance and advocate several target-aware pretraining objectives. Overall, our experiments demonstrate that properly performed pretraining significantly increases the performance of tabular DL models, which often leads to their superiority over GBDTs.
On Embeddings for Numerical Features in Tabular Deep Learning
Mar 15, 2022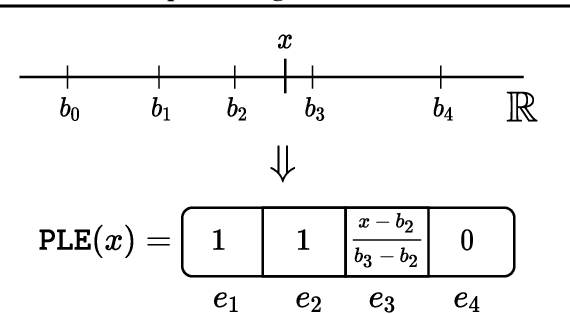

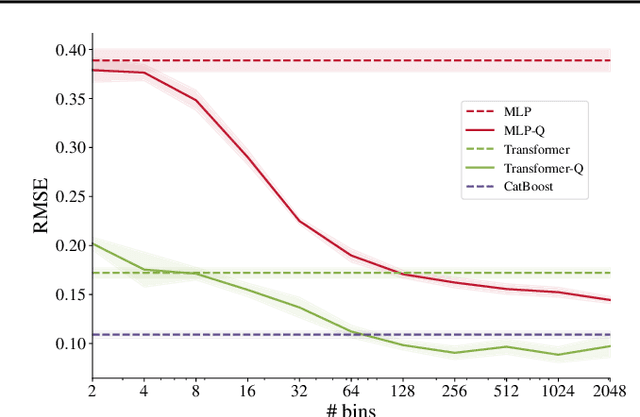

Recently, Transformer-like deep architectures have shown strong performance on tabular data problems. Unlike traditional models, e.g., MLP, these architectures map scalar values of numerical features to high-dimensional embeddings before mixing them in the main backbone. In this work, we argue that embeddings for numerical features are an underexplored degree of freedom in tabular DL, which allows constructing more powerful DL models and competing with GBDT on some traditionally GBDT-friendly benchmarks. We start by describing two conceptually different approaches to building embedding modules: the first one is based on a piecewise linear encoding of scalar values, and the second one utilizes periodic activations. Then, we empirically demonstrate that these two approaches can lead to significant performance boosts compared to the embeddings based on conventional blocks such as linear layers and ReLU activations. Importantly, we also show that embedding numerical features is beneficial for many backbones, not only for Transformers. Specifically, after proper embeddings, simple MLP-like models can perform on par with the attention-based architectures. Overall, we highlight embeddings for numerical features as an important design aspect with good potential for further improvements in tabular DL.
Label-Efficient Semantic Segmentation with Diffusion Models
Dec 27, 2021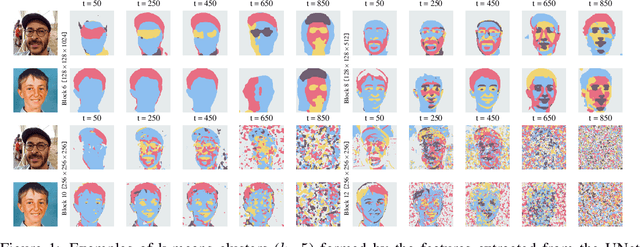

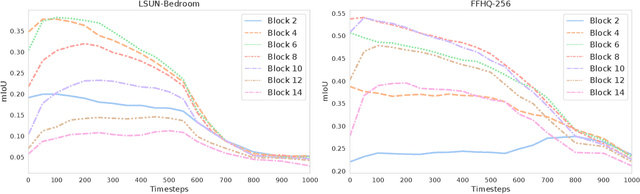
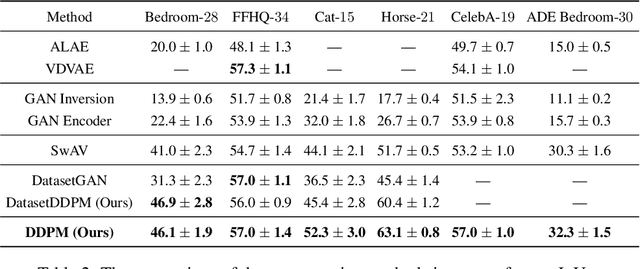
Denoising diffusion probabilistic models have recently received much research attention since they outperform alternative approaches, such as GANs, and currently provide state-of-the-art generative performance. The superior performance of diffusion models has made them an appealing tool in several applications, including inpainting, super-resolution, and semantic editing. In this paper, we demonstrate that diffusion models can also serve as an instrument for semantic segmentation, especially in the setup when labeled data is scarce. In particular, for several pretrained diffusion models, we investigate the intermediate activations from the networks that perform the Markov step of the reverse diffusion process. We show that these activations effectively capture the semantic information from an input image and appear to be excellent pixel-level representations for the segmentation problem. Based on these observations, we describe a simple segmentation method, which can work even if only a few training images are provided. Our approach significantly outperforms the existing alternatives on several datasets for the same amount of human supervision.
Revisiting Deep Learning Models for Tabular Data
Jun 22, 2021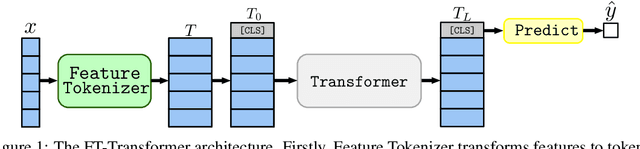
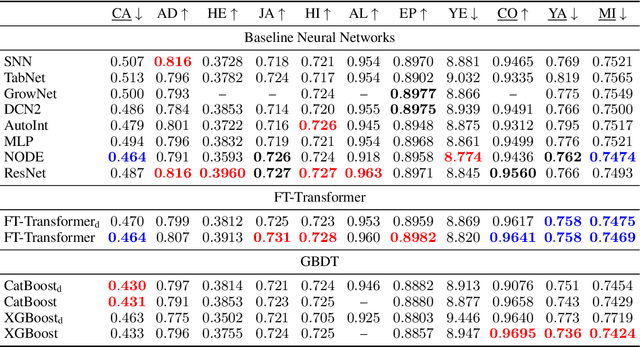
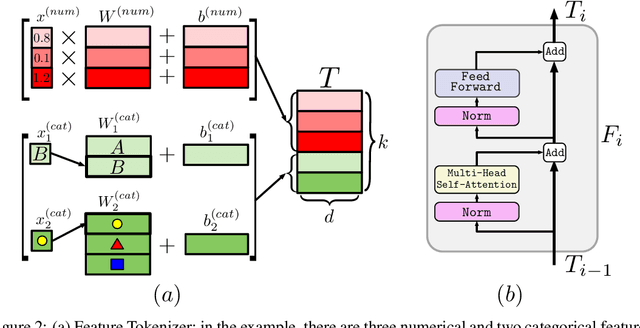
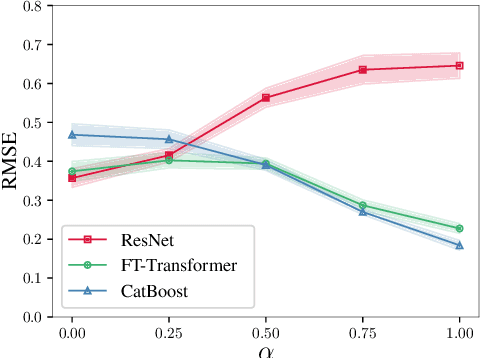
The necessity of deep learning for tabular data is still an unanswered question addressed by a large number of research efforts. The recent literature on tabular DL proposes several deep architectures reported to be superior to traditional "shallow" models like Gradient Boosted Decision Trees. However, since existing works often use different benchmarks and tuning protocols, it is unclear if the proposed models universally outperform GBDT. Moreover, the models are often not compared to each other, therefore, it is challenging to identify the best deep model for practitioners. In this work, we start from a thorough review of the main families of DL models recently developed for tabular data. We carefully tune and evaluate them on a wide range of datasets and reveal two significant findings. First, we show that the choice between GBDT and DL models highly depends on data and there is still no universally superior solution. Second, we demonstrate that a simple ResNet-like architecture is a surprisingly effective baseline, which outperforms most of the sophisticated models from the DL literature. Finally, we design a simple adaptation of the Transformer architecture for tabular data that becomes a new strong DL baseline and reduces the gap between GBDT and DL models on datasets where GBDT dominates.