 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Editing of Video Content, Actions, and Dynamics without Training
Mar 18, 2026Controlled video generation has seen drastic improvements in recent years. However, editing actions and dynamic events, or inserting contents that should affect the behaviors of other objects in real-world videos, remains a major challenge. Existing trained models struggle with complex edits, likely due to the difficulty of collecting relevant training data. Similarly, existing training-free methods are inherently restricted to structure- and motion-preserving edits and do not support modification of motion or interactions. Here, we introduce DynaEdit, a training-free editing method that unlocks versatile video editing capabilities with pretrained text-to-video flow models. Our method relies on the recently introduced inversion-free approach, which does not intervene in the model internals, and is thus model-agnostic. We show that naively attempting to adapt this approach to general unconstrained editing results in severe low-frequency misalignment and high-frequency jitter. We explain the sources for these phenomena and introduce novel mechanisms for overcoming them. Through extensive experiments, we show that DynaEdit achieves state-of-the-art results on complex text-based video editing tasks, including modifying actions, inserting objects that interact with the scene, and introducing global effects.
Visual Diffusion Models are Geometric Solvers
Oct 24, 2025In this paper we show that visual diffusion models can serve as effective geometric solvers: they can directly reason about geometric problems by working in pixel space. We first demonstrate this on the Inscribed Square Problem, a long-standing problem in geometry that asks whether every Jordan curve contains four points forming a square. We then extend the approach to two other well-known hard geometric problems: the Steiner Tree Problem and the Simple Polygon Problem. Our method treats each problem instance as an image and trains a standard visual diffusion model that transforms Gaussian noise into an image representing a valid approximate solution that closely matches the exact one. The model learns to transform noisy geometric structures into correct configurations, effectively recasting geometric reasoning as image generation. Unlike prior work that necessitates specialized architectures and domain-specific adaptations when applying diffusion to parametric geometric representations, we employ a standard visual diffusion model that operates on the visual representation of the problem. This simplicity highlights a surprising bridge between generative modeling and geometric problem solving. Beyond the specific problems studied here, our results point toward a broader paradigm: operating in image space provides a general and practical framework for approximating notoriously hard problems, and opens the door to tackling a far wider class of challenging geometric tasks.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
ReNoise: Real Image Inversion Through Iterative Noising
Mar 21, 2024Recent advancements in text-guided diffusion models have unlocked powerful image manipulation capabilities. However, applying these methods to real images necessitates the inversion of the images into the domain of the pretrained diffusion model. Achieving faithful inversion remains a challenge, particularly for more recent models trained to generate images with a small number of denoising steps. In this work, we introduce an inversion method with a high quality-to-operation ratio, enhancing reconstruction accuracy without increasing the number of operations. Building on reversing the diffusion sampling process, our method employs an iterative renoising mechanism at each inversion sampling step. This mechanism refines the approximation of a predicted point along the forward diffusion trajectory, by iteratively applying the pretrained diffusion model, and averaging these predictions. We evaluate the performance of our ReNoise technique using various sampling algorithms and models, including recent accelerated diffusion models. Through comprehensive evaluations and comparisons, we show its effectiveness in terms of both accuracy and speed. Furthermore, we confirm that our method preserves editability by demonstrating text-driven image editing on real images.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024



Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
Style Aligned Image Generation via Shared Attention
Dec 04, 2023Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing methods necessitating fine-tuning and manual intervention to disentangle content and style. In this paper, we introduce StyleAligned, a novel technique designed to establish style alignment among a series of generated images. By employing minimal `attention sharing' during the diffusion process, our method maintains style consistency across images within T2I models. This approach allows for the creation of style-consistent images using a reference style through a straightforward inversion operation. Our method's evaluation across diverse styles and text prompts demonstrates high-quality synthesis and fidelity, underscoring its efficacy in achieving consistent style across various inputs.
AnyLens: A Generative Diffusion Model with Any Rendering Lens
Nov 29, 2023State-of-the-art diffusion models can generate highly realistic images based on various conditioning like text, segmentation, and depth. However, an essential aspect often overlooked is the specific camera geometry used during image capture. The influence of different optical systems on the final scene appearance is frequently overlooked. This study introduces a framework that intimately integrates a text-to-image diffusion model with the particular lens geometry used in image rendering. Our method is based on a per-pixel coordinate conditioning method, enabling the control over the rendering geometry. Notably, we demonstrate the manipulation of curvature properties, achieving diverse visual effects, such as fish-eye, panoramic views, and spherical texturing using a single diffusion model.
Concept Decomposition for Visual Exploration and Inspiration
May 31, 2023



A creative idea is often born from transforming, combining, and modifying ideas from existing visual examples capturing various concepts. However, one cannot simply copy the concept as a whole, and inspiration is achieved by examining certain aspects of the concept. Hence, it is often necessary to separate a concept into different aspects to provide new perspectives. In this paper, we propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent space for concept decomposition and generation. Each node in the tree represents a sub-concept using a learned vector embedding injected into the latent space of a pretrained text-to-image model. We use a set of regularizations to guide the optimization of the embedding vectors encoded in the nodes to follow the hierarchical structure of the tree. Our method allows to explore and discover new concepts derived from the original one. The tree provides the possibility of endless visual sampling at each node, allowing the user to explore the hidden sub-concepts of the object of interest. The learned aspects in each node can be combined within and across trees to create new visual ideas, and can be used in natural language sentences to apply such aspects to new designs.
$P+$: Extended Textual Conditioning in Text-to-Image Generation
Mar 27, 2023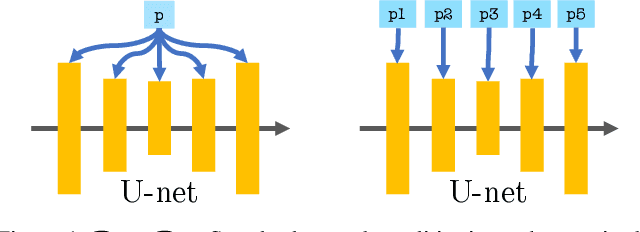



We introduce an Extended Textual Conditioning space in text-to-image models, referred to as $P+$. This space consists of multiple textual conditions, derived from per-layer prompts, each corresponding to a layer of the denoising U-net of the diffusion model. We show that the extended space provides greater disentangling and control over image synthesis. We further introduce Extended Textual Inversion (XTI), where the images are inverted into $P+$, and represented by per-layer tokens. We show that XTI is more expressive and precise, and converges faster than the original Textual Inversion (TI) space. The extended inversion method does not involve any noticeable trade-off between reconstruction and editability and induces more regular inversions. We conduct a series of extensive experiments to analyze and understand the properties of the new space, and to showcase the effectiveness of our method for personalizing text-to-image models. Furthermore, we utilize the unique properties of this space to achieve previously unattainable results in object-style mixing using text-to-image models. Project page: https://prompt-plus.github.io
Sketch-Guided Text-to-Image Diffusion Models
Nov 24, 2022Text-to-Image models have introduced a remarkable leap in the evolution of machine learning, demonstrating high-quality synthesis of images from a given text-prompt. However, these powerful pretrained models still lack control handles that can guide spatial properties of the synthesized images. In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task. Our key idea is to train a Latent Guidance Predictor (LGP) - a small, per-pixel, Multi-Layer Perceptron (MLP) that maps latent features of noisy images to spatial maps, where the deep features are extracted from the core Denoising Diffusion Probabilistic Model (DDPM) network. The LGP is trained only on a few thousand images and constitutes a differential guiding map predictor, over which the loss is computed and propagated back to push the intermediate images to agree with the spatial map. The per-pixel training offers flexibility and locality which allows the technique to perform well on out-of-domain sketches, including free-hand style drawings. We take a particular focus on the sketch-to-image translation task, revealing a robust and expressive way to generate images that follow the guidance of a sketch of arbitrary style or domain. Project page: sketch-guided-diffusion.github.io