 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshOn: Intersection-Free Mesh-to-Mesh Composition
Apr 09, 2026We propose MeshOn, a method that finds physically and semantically realistic compositions of two input meshes. Given an accessory, a base mesh with a user-defined target region, and optional text strings for both meshes, MeshOn uses a multi-step optimization framework to realistically fit the meshes onto each other while preventing intersections. We initialize the shapes' rigid configuration via a structured alignment scheme using Vision-to-Language Models, which we then optimize using a combination of attractive geometric losses, and a physics-inspired barrier loss that prevents surface intersections. We then obtain a final deformation of the object, assisted by a diffusion prior. Our method successfully fits accessories of various materials over a breadth of target regions, and is designed to fit directly into existing digital artist workflows. We demonstrate the robustness and accuracy of our pipeline by comparing it with generative approaches and traditional registration algorithms.
HyperCT: Low-Rank Hypernet for Unified Chest CT Analysis
Apr 03, 2026Non-contrast chest CTs offer a rich opportunity for both conventional pulmonary and opportunistic extra-pulmonary screening. While Multi-Task Learning (MTL) can unify these diverse tasks, standard hard-parameter sharing approaches are often suboptimal for modeling distinct pathologies. We propose HyperCT, a framework that dynamically adapts a Vision Transformer backbone via a Hypernetwork. To ensure computational efficiency, we integrate Low-Rank Adaptation (LoRA), allowing the model to regress task-specific low-rank weight updates rather than full parameters. Validated on a large-scale dataset of radiological and cardiological tasks, \method{} outperforms various strong baselines, offering a unified, parameter-efficient solution for holistic patient assessment. Our code is available at https://github.com/lfb-1/HyperCT.
Scene Grounding In the Wild
Mar 27, 2026Reconstructing accurate 3D models of large-scale real-world scenes from unstructured, in-the-wild imagery remains a core challenge in computer vision, especially when the input views have little or no overlap. In such cases, existing reconstruction pipelines often produce multiple disconnected partial reconstructions or erroneously merge non-overlapping regions into overlapping geometry. In this work, we propose a framework that grounds each partial reconstruction to a complete reference model of the scene, enabling globally consistent alignment even in the absence of visual overlap. We obtain reference models from dense, geospatially accurate pseudo-synthetic renderings derived from Google Earth Studio. These renderings provide full scene coverage but differ substantially in appearance from real-world photographs. Our key insight is that, despite this significant domain gap, both domains share the same underlying scene semantics. We represent the reference model using 3D Gaussian Splatting, augmenting each Gaussian with semantic features, and formulate alignment as an inverse feature-based optimization scheme that estimates a global 6DoF pose and scale while keeping the reference model fixed. Furthermore, we introduce the WikiEarth dataset, which registers existing partial 3D reconstructions with pseudo-synthetic reference models. We demonstrate that our approach consistently improves global alignment when initialized with various classical and learning-based pipelines, while mitigating failure modes of state-of-the-art end-to-end models. All code and data will be released.
Raster2Seq: Polygon Sequence Generation for Floorplan Reconstruction
Feb 09, 2026Reconstructing a structured vector-graphics representation from a rasterized floorplan image is typically an important prerequisite for computational tasks involving floorplans such as automated understanding or CAD workflows. However, existing techniques struggle in faithfully generating the structure and semantics conveyed by complex floorplans that depict large indoor spaces with many rooms and a varying numbers of polygon corners. To this end, we propose Raster2Seq, framing floorplan reconstruction as a sequence-to-sequence task in which floorplan elements--such as rooms, windows, and doors--are represented as labeled polygon sequences that jointly encode geometry and semantics. Our approach introduces an autoregressive decoder that learns to predict the next corner conditioned on image features and previously generated corners using guidance from learnable anchors. These anchors represent spatial coordinates in image space, hence allowing for effectively directing the attention mechanism to focus on informative image regions. By embracing the autoregressive mechanism, our method offers flexibility in the output format, enabling for efficiently handling complex floorplans with numerous rooms and diverse polygon structures. Our method achieves state-of-the-art performance on standard benchmarks such as Structure3D, CubiCasa5K, and Raster2Graph, while also demonstrating strong generalization to more challenging datasets like WAFFLE, which contain diverse room structures and complex geometric variations.
Lang3D-XL: Language Embedded 3D Gaussians for Large-scale Scenes
Dec 08, 2025Embedding a language field in a 3D representation enables richer semantic understanding of spatial environments by linking geometry with descriptive meaning. This allows for a more intuitive human-computer interaction, enabling querying or editing scenes using natural language, and could potentially improve tasks like scene retrieval, navigation, and multimodal reasoning. While such capabilities could be transformative, in particular for large-scale scenes, we find that recent feature distillation approaches cannot effectively learn over massive Internet data due to challenges in semantic feature misalignment and inefficiency in memory and runtime. To this end, we propose a novel approach to address these challenges. First, we introduce extremely low-dimensional semantic bottleneck features as part of the underlying 3D Gaussian representation. These are processed by rendering and passing them through a multi-resolution, feature-based, hash encoder. This significantly improves efficiency both in runtime and GPU memory. Second, we introduce an Attenuated Downsampler module and propose several regularizations addressing the semantic misalignment of ground truth 2D features. We evaluate our method on the in-the-wild HolyScenes dataset and demonstrate that it surpasses existing approaches in both performance and efficiency.
Not Every Gift Comes in Gold Paper or with a Red Ribbon: Exploring Color Perception in Text-to-Image Models
Aug 27, 2025Text-to-image generation has recently seen remarkable success, granting users with the ability to create high-quality images through the use of text. However, contemporary methods face challenges in capturing the precise semantics conveyed by complex multi-object prompts. Consequently, many works have sought to mitigate such semantic misalignments, typically via inference-time schemes that modify the attention layers of the denoising networks. However, prior work has mostly utilized coarse metrics, such as the cosine similarity between text and image CLIP embeddings, or human evaluations, which are challenging to conduct on a larger-scale. In this work, we perform a case study on colors -- a fundamental attribute commonly associated with objects in text prompts, which offer a rich test bed for rigorous evaluation. Our analysis reveals that pretrained models struggle to generate images that faithfully reflect multiple color attributes-far more so than with single-color prompts-and that neither inference-time techniques nor existing editing methods reliably resolve these semantic misalignments. Accordingly, we introduce a dedicated image editing technique, mitigating the issue of multi-object semantic alignment for prompts containing multiple colors. We demonstrate that our approach significantly boosts performance over a wide range of metrics, considering images generated by various text-to-image diffusion-based techniques.
WildCAT3D: Appearance-Aware Multi-View Diffusion in the Wild
Jun 16, 2025Despite recent advances in sparse novel view synthesis (NVS) applied to object-centric scenes, scene-level NVS remains a challenge. A central issue is the lack of available clean multi-view training data, beyond manually curated datasets with limited diversity, camera variation, or licensing issues. On the other hand, an abundance of diverse and permissively-licensed data exists in the wild, consisting of scenes with varying appearances (illuminations, transient occlusions, etc.) from sources such as tourist photos. To this end, we present WildCAT3D, a framework for generating novel views of scenes learned from diverse 2D scene image data captured in the wild. We unlock training on these data sources by explicitly modeling global appearance conditions in images, extending the state-of-the-art multi-view diffusion paradigm to learn from scene views of varying appearances. Our trained model generalizes to new scenes at inference time, enabling the generation of multiple consistent novel views. WildCAT3D provides state-of-the-art results on single-view NVS in object- and scene-level settings, while training on strictly less data sources than prior methods. Additionally, it enables novel applications by providing global appearance control during generation.
InstanceGen: Image Generation with Instance-level Instructions
May 08, 2025Despite rapid advancements in the capabilities of generative models, pretrained text-to-image models still struggle in capturing the semantics conveyed by complex prompts that compound multiple objects and instance-level attributes. Consequently, we are witnessing growing interests in integrating additional structural constraints, %leveraging additional structural inputs typically in the form of coarse bounding boxes, to better guide the generation process in such challenging cases. In this work, we take the idea of structural guidance a step further by making the observation that contemporary image generation models can directly provide a plausible \emph{fine-grained} structural initialization. We propose a technique that couples this image-based structural guidance with LLM-based instance-level instructions, yielding output images that adhere to all parts of the text prompt, including object counts, instance-level attributes, and spatial relations between instances.
Let it Snow! Animating Static Gaussian Scenes With Dynamic Weather Effects
Apr 07, 2025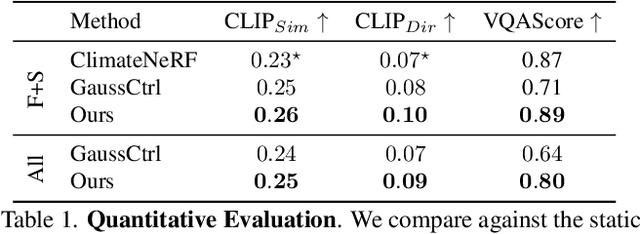
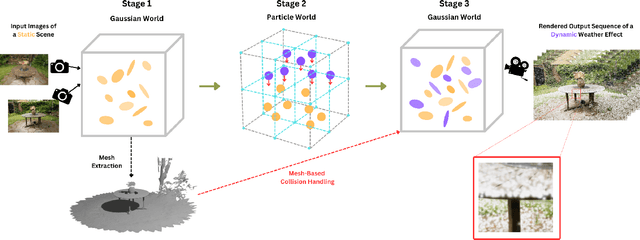


3D Gaussian Splatting has recently enabled fast and photorealistic reconstruction of static 3D scenes. However, introducing dynamic elements that interact naturally with such static scenes remains challenging. Accordingly, we present a novel hybrid framework that combines Gaussian-particle representations for incorporating physically-based global weather effects into static 3D Gaussian Splatting scenes, correctly handling the interactions of dynamic elements with the static scene. We follow a three-stage process: we first map static 3D Gaussians to a particle-based representation. We then introduce dynamic particles and simulate their motion using the Material Point Method (MPM). Finally, we map the simulated particles back to the Gaussian domain while introducing appearance parameters tailored for specific effects. To correctly handle the interactions of dynamic elements with the static scene, we introduce specialized collision handling techniques. Our approach supports a variety of weather effects, including snowfall, rainfall, fog, and sandstorms, and can also support falling objects, all with physically plausible motion and appearance. Experiments demonstrate that our method significantly outperforms existing approaches in both visual quality and physical realism.
Dynamic Scene Understanding from Vision-Language Representations
Jan 20, 2025



Images depicting complex, dynamic scenes are challenging to parse automatically, requiring both high-level comprehension of the overall situation and fine-grained identification of participating entities and their interactions. Current approaches use distinct methods tailored to sub-tasks such as Situation Recognition and detection of Human-Human and Human-Object Interactions. However, recent advances in image understanding have often leveraged web-scale vision-language (V&L) representations to obviate task-specific engineering. In this work, we propose a framework for dynamic scene understanding tasks by leveraging knowledge from modern, frozen V&L representations. By framing these tasks in a generic manner - as predicting and parsing structured text, or by directly concatenating representations to the input of existing models - we achieve state-of-the-art results while using a minimal number of trainable parameters relative to existing approaches. Moreover, our analysis of dynamic knowledge of these representations shows that recent, more powerful representations effectively encode dynamic scene semantics, making this approach newly possible.