 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceGen: Image Generation with Instance-level Instructions
May 08, 2025Despite rapid advancements in the capabilities of generative models, pretrained text-to-image models still struggle in capturing the semantics conveyed by complex prompts that compound multiple objects and instance-level attributes. Consequently, we are witnessing growing interests in integrating additional structural constraints, %leveraging additional structural inputs typically in the form of coarse bounding boxes, to better guide the generation process in such challenging cases. In this work, we take the idea of structural guidance a step further by making the observation that contemporary image generation models can directly provide a plausible \emph{fine-grained} structural initialization. We propose a technique that couples this image-based structural guidance with LLM-based instance-level instructions, yielding output images that adhere to all parts of the text prompt, including object counts, instance-level attributes, and spatial relations between instances.
Meta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects
Jul 02, 2024



The recent availability and adaptability of text-to-image models has sparked a new era in many related domains that benefit from the learned text priors as well as high-quality and fast generation capabilities, one of which is texture generation for 3D objects. Although recent texture generation methods achieve impressive results by using text-to-image networks, the combination of global consistency, quality, and speed, which is crucial for advancing texture generation to real-world applications, remains elusive. To that end, we introduce Meta 3D TextureGen: a new feedforward method comprised of two sequential networks aimed at generating high-quality and globally consistent textures for arbitrary geometries of any complexity degree in less than 20 seconds. Our method achieves state-of-the-art results in quality and speed by conditioning a text-to-image model on 3D semantics in 2D space and fusing them into a complete and high-resolution UV texture map, as demonstrated by extensive qualitative and quantitative evaluations. In addition, we introduce a texture enhancement network that is capable of up-scaling any texture by an arbitrary ratio, producing 4k pixel resolution textures.
Meta 3D Gen
Jul 02, 2024


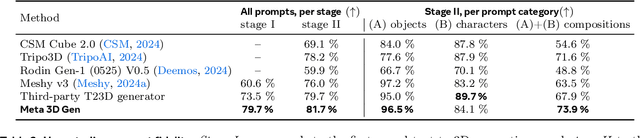
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
Jul 02, 2024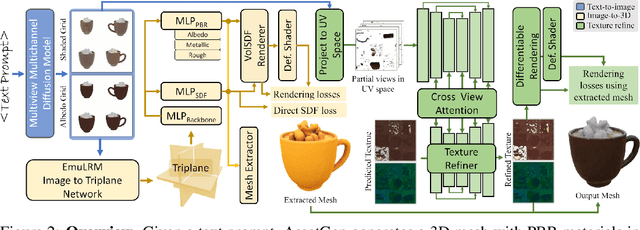
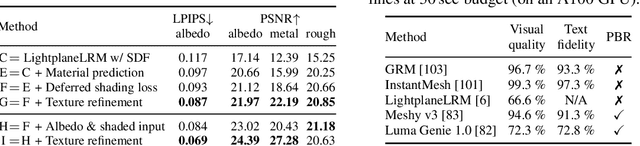
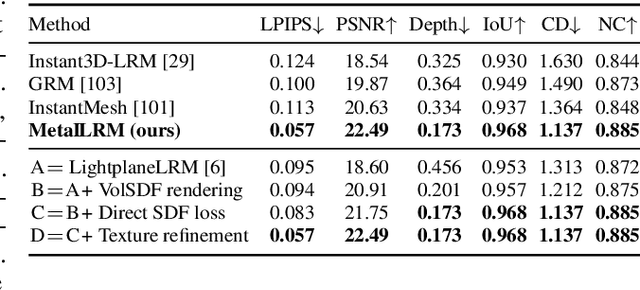

We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object's appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with factored shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
Replay: Multi-modal Multi-view Acted Videos for Casual Holography
Jul 22, 2023We introduce Replay, a collection of multi-view, multi-modal videos of humans interacting socially. Each scene is filmed in high production quality, from different viewpoints with several static cameras, as well as wearable action cameras, and recorded with a large array of microphones at different positions in the room. Overall, the dataset contains over 4000 minutes of footage and over 7 million timestamped high-resolution frames annotated with camera poses and partially with foreground masks. The Replay dataset has many potential applications, such as novel-view synthesis, 3D reconstruction, novel-view acoustic synthesis, human body and face analysis, and training generative models. We provide a benchmark for training and evaluating novel-view synthesis, with two scenarios of different difficulty. Finally, we evaluate several baseline state-of-the-art methods on the new benchmark.
Bundle Optimization for Multi-aspect Embedding
Sep 16, 2017
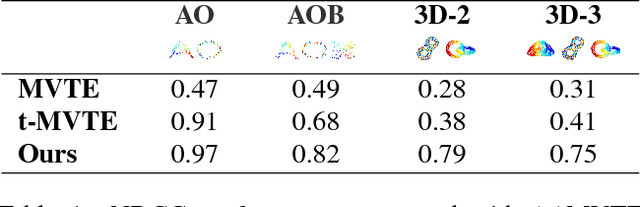
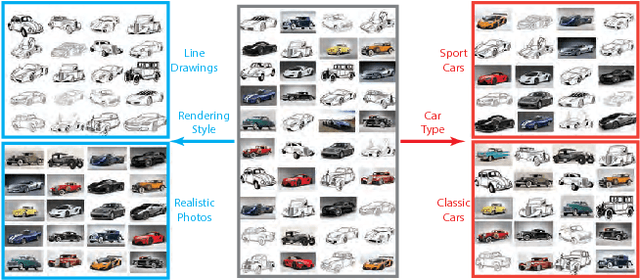
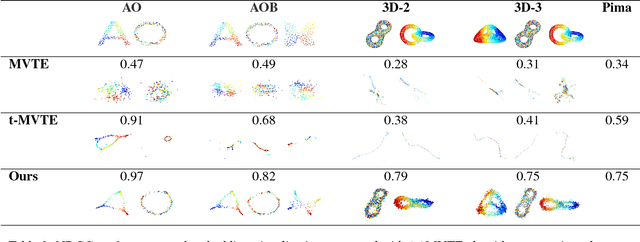
Understanding semantic similarity among images is the core of a wide range of computer vision applications. An important step towards this goal is to collect and learn human perceptions. Interestingly, the semantic context of images is often ambiguous as images can be perceived with emphasis on different aspects, which may be contradictory to each other. In this paper, we present a method for learning the semantic similarity among images, inferring their latent aspects and embedding them into multi-spaces corresponding to their semantic aspects. We consider the multi-embedding problem as an optimization function that evaluates the embedded distances with respect to the qualitative clustering queries. The key idea of our approach is to collect and embed qualitative measures that share the same aspects in bundles. To ensure similarity aspect sharing among multiple measures, image classification queries are presented to, and solved by users. The collected image clusters are then converted into bundles of tuples, which are fed into our bundle optimization algorithm that jointly infers the aspect similarity and multi-aspect embedding. Extensive experimental results show that our approach significantly outperforms state-of-the-art multi-embedding approaches on various datasets, and scales well for large multi-aspect similarity measures.