 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects
Jul 02, 2024



The recent availability and adaptability of text-to-image models has sparked a new era in many related domains that benefit from the learned text priors as well as high-quality and fast generation capabilities, one of which is texture generation for 3D objects. Although recent texture generation methods achieve impressive results by using text-to-image networks, the combination of global consistency, quality, and speed, which is crucial for advancing texture generation to real-world applications, remains elusive. To that end, we introduce Meta 3D TextureGen: a new feedforward method comprised of two sequential networks aimed at generating high-quality and globally consistent textures for arbitrary geometries of any complexity degree in less than 20 seconds. Our method achieves state-of-the-art results in quality and speed by conditioning a text-to-image model on 3D semantics in 2D space and fusing them into a complete and high-resolution UV texture map, as demonstrated by extensive qualitative and quantitative evaluations. In addition, we introduce a texture enhancement network that is capable of up-scaling any texture by an arbitrary ratio, producing 4k pixel resolution textures.
Meta 3D Gen
Jul 02, 2024


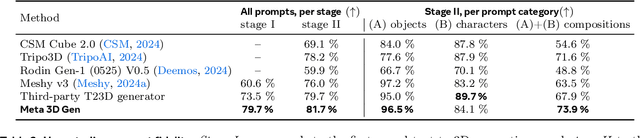
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Localizing Object-level Shape Variations with Text-to-Image Diffusion Models
Mar 20, 2023



Text-to-image models give rise to workflows which often begin with an exploration step, where users sift through a large collection of generated images. The global nature of the text-to-image generation process prevents users from narrowing their exploration to a particular object in the image. In this paper, we present a technique to generate a collection of images that depicts variations in the shape of a specific object, enabling an object-level shape exploration process. Creating plausible variations is challenging as it requires control over the shape of the generated object while respecting its semantics. A particular challenge when generating object variations is accurately localizing the manipulation applied over the object's shape. We introduce a prompt-mixing technique that switches between prompts along the denoising process to attain a variety of shape choices. To localize the image-space operation, we present two techniques that use the self-attention layers in conjunction with the cross-attention layers. Moreover, we show that these localization techniques are general and effective beyond the scope of generating object variations. Extensive results and comparisons demonstrate the effectiveness of our method in generating object variations, and the competence of our localization techniques.
Learning from Small Data Through Sampling an Implicit Conditional Generative Latent Optimization Model
Apr 17, 2020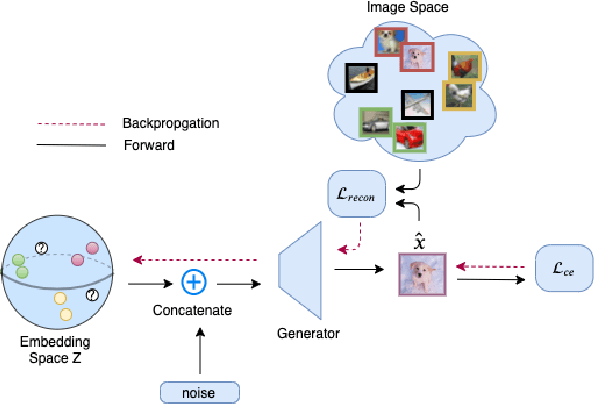

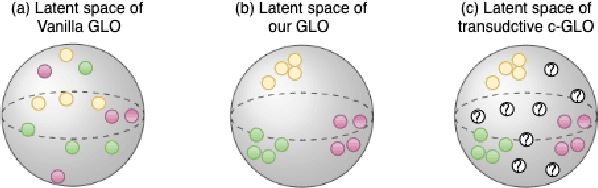

We revisit the long-standing problem of \emph{learning from small sample}. In recent years major efforts have been invested into the generation of new samples from a small set of training data points. Some use classical transformations, others synthesize new examples. Our approach belongs to the second one. We propose a new model based on conditional Generative Latent Optimization (cGLO). Our model learns to synthesize completely new samples for every class just by interpolating between samples in the latent space. The proposed method samples the learned latent space using spherical interpolations (\emph{slerp}) and generates a new sample using the trained generator. Our empirical results show that the new sampled set is diverse enough, leading to improvement in image classification in comparison to the state of the art, when trained on small samples of CIFAR-100 and CUB-200.