 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Based Method for Fast Registration of Cardiac Magnetic Resonance Images
Jun 23, 2025



Image registration is used in many medical image analysis applications, such as tracking the motion of tissue in cardiac images, where cardiac kinematics can be an indicator of tissue health. Registration is a challenging problem for deep learning algorithms because ground truth transformations are not feasible to create, and because there are potentially multiple transformations that can produce images that appear correlated with the goal. Unsupervised methods have been proposed to learn to predict effective transformations, but these methods take significantly longer to predict than established baseline methods. For a deep learning method to see adoption in wider research and clinical settings, it should be designed to run in a reasonable time on common, mid-level hardware. Fast methods have been proposed for the task of image registration but often use patch-based methods which can affect registration accuracy for a highly dynamic organ such as the heart. In this thesis, a fast, volumetric registration model is proposed for the use of quantifying cardiac strain. The proposed Deep Learning Neural Network (DLNN) is designed to utilize an architecture that can compute convolutions incredibly efficiently, allowing the model to achieve registration fidelity similar to other state-of-the-art models while taking a fraction of the time to perform inference. The proposed fast and lightweight registration (FLIR) model is used to predict tissue motion which is then used to quantify the non-uniform strain experienced by the tissue. For acquisitions taken from the same patient at approximately the same time, it would be expected that strain values measured between the acquisitions would have very small differences. Using this metric, strain values computed using the FLIR method are shown to be very consistent.
Unsupervised 2D-3D lifting of non-rigid objects using local constraints
Apr 27, 2025For non-rigid objects, predicting the 3D shape from 2D keypoint observations is ill-posed due to occlusions, and the need to disentangle changes in viewpoint and changes in shape. This challenge has often been addressed by embedding low-rank constraints into specialized models. These models can be hard to train, as they depend on finding a canonical way of aligning observations, before they can learn detailed geometry. These constraints have limited the reconstruction quality. We show that generic, high capacity models, trained with an unsupervised loss, allow for more accurate predicted shapes. In particular, applying low-rank constraints to localized subsets of the full shape allows the high capacity to be suitably constrained. We reduce the state-of-the-art reconstruction error on the S-Up3D dataset by over 70%.
Meta 3D Gen
Jul 02, 2024


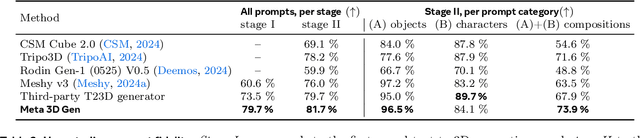
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
CoTracker: It is Better to Track Together
Jul 14, 2023



Methods for video motion prediction either estimate jointly the instantaneous motion of all points in a given video frame using optical flow or independently track the motion of individual points throughout the video. The latter is true even for powerful deep-learning methods that can track points through occlusions. Tracking points individually ignores the strong correlation that can exist between the points, for instance, because they belong to the same physical object, potentially harming performance. In this paper, we thus propose CoTracker, an architecture that jointly tracks multiple points throughout an entire video. This architecture combines several ideas from the optical flow and tracking literature in a new, flexible and powerful design. It is based on a transformer network that models the correlation of different points in time via specialised attention layers. The transformer iteratively updates an estimate of several trajectories. It can be applied in a sliding-window manner to very long videos, for which we engineer an unrolled training loop. It can track from one to several points jointly and supports adding new points to track at any time. The result is a flexible and powerful tracking algorithm that outperforms state-of-the-art methods in almost all benchmarks.
DynamicStereo: Consistent Dynamic Depth from Stereo Videos
May 03, 2023



We consider the problem of reconstructing a dynamic scene observed from a stereo camera. Most existing methods for depth from stereo treat different stereo frames independently, leading to temporally inconsistent depth predictions. Temporal consistency is especially important for immersive AR or VR scenarios, where flickering greatly diminishes the user experience. We propose DynamicStereo, a novel transformer-based architecture to estimate disparity for stereo videos. The network learns to pool information from neighboring frames to improve the temporal consistency of its predictions. Our architecture is designed to process stereo videos efficiently through divided attention layers. We also introduce Dynamic Replica, a new benchmark dataset containing synthetic videos of people and animals in scanned environments, which provides complementary training and evaluation data for dynamic stereo closer to real applications than existing datasets. Training with this dataset further improves the quality of predictions of our proposed DynamicStereo as well as prior methods. Finally, it acts as a benchmark for consistent stereo methods.
Real-time volumetric rendering of dynamic humans
Mar 21, 2023



We present a method for fast 3D reconstruction and real-time rendering of dynamic humans from monocular videos with accompanying parametric body fits. Our method can reconstruct a dynamic human in less than 3h using a single GPU, compared to recent state-of-the-art alternatives that take up to 72h. These speedups are obtained by using a lightweight deformation model solely based on linear blend skinning, and an efficient factorized volumetric representation for modeling the shape and color of the person in canonical pose. Moreover, we propose a novel local ray marching rendering which, by exploiting standard GPU hardware and without any baking or conversion of the radiance field, allows visualizing the neural human on a mobile VR device at 40 frames per second with minimal loss of visual quality. Our experimental evaluation shows superior or competitive results with state-of-the art methods while obtaining large training speedup, using a simple model, and achieving real-time rendering.
Self-Supervised Correspondence Estimation via Multiview Registration
Dec 06, 2022



Video provides us with the spatio-temporal consistency needed for visual learning. Recent approaches have utilized this signal to learn correspondence estimation from close-by frame pairs. However, by only relying on close-by frame pairs, those approaches miss out on the richer long-range consistency between distant overlapping frames. To address this, we propose a self-supervised approach for correspondence estimation that learns from multiview consistency in short RGB-D video sequences. Our approach combines pairwise correspondence estimation and registration with a novel SE(3) transformation synchronization algorithm. Our key insight is that self-supervised multiview registration allows us to obtain correspondences over longer time frames; increasing both the diversity and difficulty of sampled pairs. We evaluate our approach on indoor scenes for correspondence estimation and RGB-D pointcloud registration and find that we perform on-par with supervised approaches.
DensePose 3D: Lifting Canonical Surface Maps of Articulated Objects to the Third Dimension
Aug 31, 2021
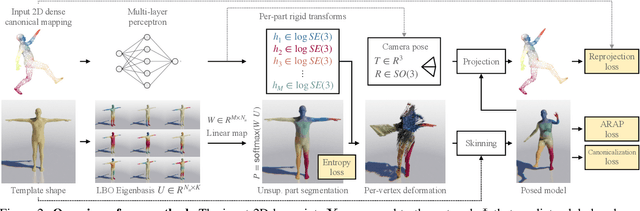


We tackle the problem of monocular 3D reconstruction of articulated objects like humans and animals. We contribute DensePose 3D, a method that can learn such reconstructions in a weakly supervised fashion from 2D image annotations only. This is in stark contrast with previous deformable reconstruction methods that use parametric models such as SMPL pre-trained on a large dataset of 3D object scans. Because it does not require 3D scans, DensePose 3D can be used for learning a wide range of articulated categories such as different animal species. The method learns, in an end-to-end fashion, a soft partition of a given category-specific 3D template mesh into rigid parts together with a monocular reconstruction network that predicts the part motions such that they reproject correctly onto 2D DensePose-like surface annotations of the object. The decomposition of the object into parts is regularized by expressing part assignments as a combination of the smooth eigenfunctions of the Laplace-Beltrami operator. We show significant improvements compared to state-of-the-art non-rigid structure-from-motion baselines on both synthetic and real data on categories of humans and animals.
Pri3D: Can 3D Priors Help 2D Representation Learning?
Apr 22, 2021
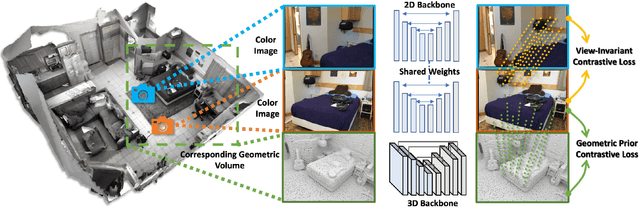

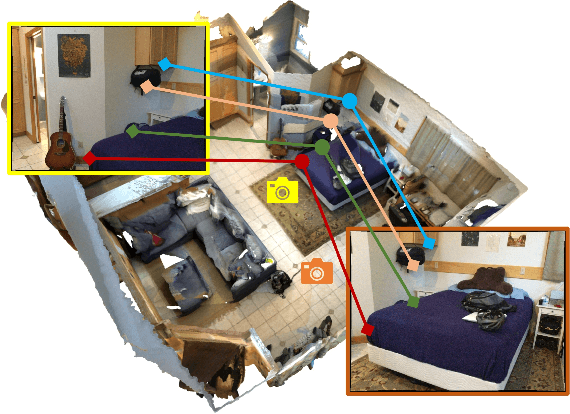
Recent advances in 3D perception have shown impressive progress in understanding geometric structures of 3Dshapes and even scenes. Inspired by these advances in geometric understanding, we aim to imbue image-based perception with representations learned under geometric constraints. We introduce an approach to learn view-invariant,geometry-aware representations for network pre-training, based on multi-view RGB-D data, that can then be effectively transferred to downstream 2D tasks. We propose to employ contrastive learning under both multi-view im-age constraints and image-geometry constraints to encode3D priors into learned 2D representations. This results not only in improvement over 2D-only representation learning on the image-based tasks of semantic segmentation, instance segmentation, and object detection on real-world in-door datasets, but moreover, provides significant improvement in the low data regime. We show a significant improvement of 6.0% on semantic segmentation on full data as well as 11.9% on 20% data against baselines on ScanNet.
Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts
Dec 16, 2020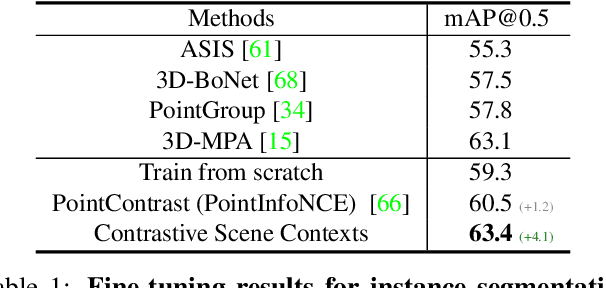
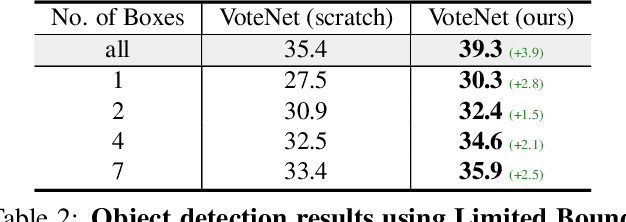
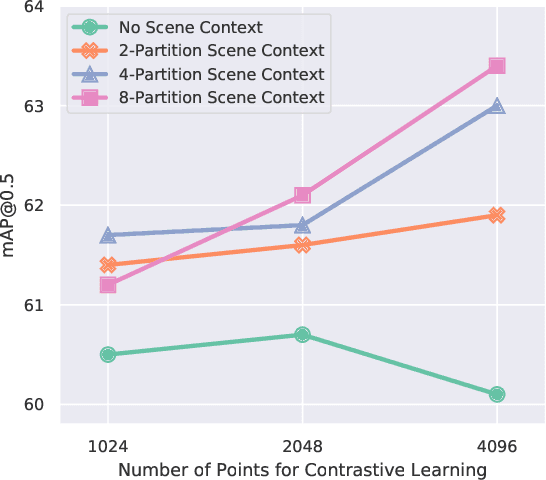
The rapid progress in 3D scene understanding has come with growing demand for data; however, collecting and annotating 3D scenes (e.g. point clouds) are notoriously hard. For example, the number of scenes (e.g. indoor rooms) that can be accessed and scanned might be limited; even given sufficient data, acquiring 3D labels (e.g. instance masks) requires intensive human labor. In this paper, we explore data-efficient learning for 3D point cloud. As a first step towards this direction, we propose Contrastive Scene Contexts, a 3D pre-training method that makes use of both point-level correspondences and spatial contexts in a scene. Our method achieves state-of-the-art results on a suite of benchmarks where training data or labels are scarce. Our study reveals that exhaustive labelling of 3D point clouds might be unnecessary; and remarkably, on ScanNet, even using 0.1% of point labels, we still achieve 89% (instance segmentation) and 96% (semantic segmentation) of the baseline performance that uses full annotations.