 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMaster: Lifting Rendered Scenes into Photorealistic Video
Mar 24, 2026State-of-the-art video generation models produce remarkable photorealism, but they lack the precise control required to align generated content with specific scene requirements. Furthermore, without an underlying explicit geometry, these models cannot guarantee 3D consistency. Conversely, 3D engines offer granular control over every scene element and provide native 3D consistency by design, yet their output often remains trapped in the "uncanny valley". Bridging this sim-to-real gap requires both structural precision, where the output must exactly preserve the geometry and dynamics of the input, and global semantic transformation, where materials, lighting, and textures must be holistically transformed to achieve photorealism. We present RealMaster, a method that leverages video diffusion models to lift rendered video into photorealistic video while maintaining full alignment with the output of the 3D engine. To train this model, we generate a paired dataset via an anchor-based propagation strategy, where the first and last frames are enhanced for realism and propagated across the intermediate frames using geometric conditioning cues. We then train an IC-LoRA on these paired videos to distill the high-quality outputs of the pipeline into a model that generalizes beyond the pipeline's constraints, handling objects and characters that appear mid-sequence and enabling inference without requiring anchor frames. Evaluated on complex GTA-V sequences, RealMaster significantly outperforms existing video editing baselines, improving photorealism while preserving the geometry, dynamics, and identity specified by the original 3D control.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Meta 3D Gen
Jul 02, 2024


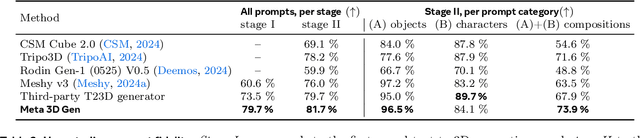
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Meta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects
Jul 02, 2024



The recent availability and adaptability of text-to-image models has sparked a new era in many related domains that benefit from the learned text priors as well as high-quality and fast generation capabilities, one of which is texture generation for 3D objects. Although recent texture generation methods achieve impressive results by using text-to-image networks, the combination of global consistency, quality, and speed, which is crucial for advancing texture generation to real-world applications, remains elusive. To that end, we introduce Meta 3D TextureGen: a new feedforward method comprised of two sequential networks aimed at generating high-quality and globally consistent textures for arbitrary geometries of any complexity degree in less than 20 seconds. Our method achieves state-of-the-art results in quality and speed by conditioning a text-to-image model on 3D semantics in 2D space and fusing them into a complete and high-resolution UV texture map, as demonstrated by extensive qualitative and quantitative evaluations. In addition, we introduce a texture enhancement network that is capable of up-scaling any texture by an arbitrary ratio, producing 4k pixel resolution textures.
Neural Inverse Kinematics
May 22, 2022

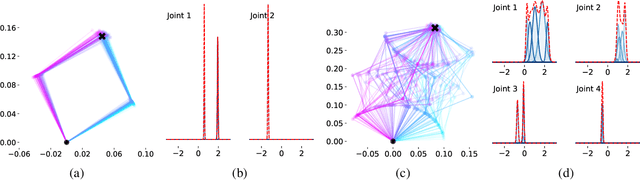

Inverse kinematic (IK) methods recover the parameters of the joints, given the desired position of selected elements in the kinematic chain. While the problem is well-defined and low-dimensional, it has to be solved rapidly, accounting for multiple possible solutions. In this work, we propose a neural IK method that employs the hierarchical structure of the problem to sequentially sample valid joint angles conditioned on the desired position and on the preceding joints along the chain. In our solution, a hypernetwork $f$ recovers the parameters of multiple primary networks {$g_1,g_2,\dots,g_N$, where $N$ is the number of joints}, such that each $g_i$ outputs a distribution of possible joint angles, and is conditioned on the sampled values obtained from the previous primary networks $g_j, j<i$. The hypernetwork can be trained on readily available pairs of matching joint angles and positions, without observing multiple solutions. At test time, a high-variance joint distribution is presented, by sampling sequentially from the primary networks. We demonstrate the advantage of the proposed method both in comparison to other IK methods for isolated instances of IK and with regard to following the path of the end effector in Cartesian space.
Meta Internal Learning
Oct 06, 2021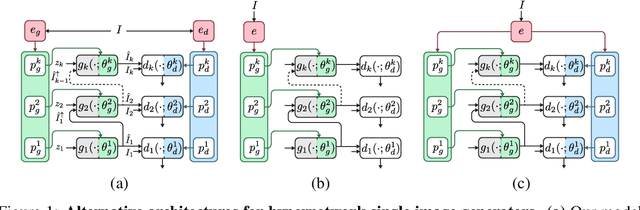
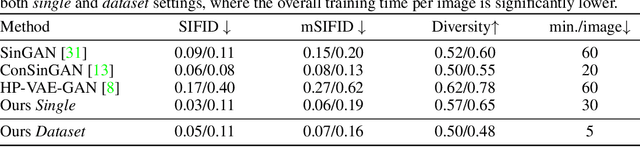


Internal learning for single-image generation is a framework, where a generator is trained to produce novel images based on a single image. Since these models are trained on a single image, they are limited in their scale and application. To overcome these issues, we propose a meta-learning approach that enables training over a collection of images, in order to model the internal statistics of the sample image more effectively. In the presented meta-learning approach, a single-image GAN model is generated given an input image, via a convolutional feedforward hypernetwork $f$. This network is trained over a dataset of images, allowing for feature sharing among different models, and for interpolation in the space of generative models. The generated single-image model contains a hierarchy of multiple generators and discriminators. It is therefore required to train the meta-learner in an adversarial manner, which requires careful design choices that we justify by a theoretical analysis. Our results show that the models obtained are as suitable as single-image GANs for many common image applications, significantly reduce the training time per image without loss in performance, and introduce novel capabilities, such as interpolation and feedforward modeling of novel images.