 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Field Parallel Decoding for Discrete Diffusion Language Models
Jun 14, 2026Discrete diffusion language models enable parallel token generation, offering a pathway to low-latency decoding. However, selecting tokens independently by marginal confidence limits effective parallelism: tokens that appear reliable in isolation can form incompatible configurations when several positions are updated at once. We introduce a training-free decoding framework that coordinates these parallel updates. At each forward pass, the method assigns a commit score to each masked position and refines these scores using pairwise interactions derived from the model's predictive distributions. A variational relaxation yields a simple fixed-point update that suppresses conflicting simultaneous commitments within a single forward pass. This mechanism allows the decoder to commit more tokens in parallel while maintaining competitive generation quality. The method is lightweight, requires no auxiliary model or retraining, and drops into existing diffusion decoding pipelines without modification. Experiments on reasoning and code-generation benchmarks show consistent improvements in the quality-latency trade-off.
Bootstrap Your Generator: Unpaired Visual Editing with Flow Matching
Jun 02, 2026Modern generative models possess a deep understanding of visual content, yet training them for image editing typically requires massive datasets of paired examples. This limits scalability, especially for video editing where collecting paired data is prohibitively expensive. We propose Bootstrap Your Generator (ByG), a general framework for unpaired training of flow matching editing models. It leverages the base model's knowledge without any external signal. Our approach pairs instruction-following cues extracted from the frozen model with cycle-consistency for structure preservation. To make this tractable, we propose to route gradients from downstream losses over clean predictions to noisy training states. We demonstrate state-of-the-art results on challenging data-scarce image and video editing scenarios. Extensive evaluations and user studies show that our method effectively generalizes to unseen domains and outperforms supervised baselines trained on millions of samples. Analysis reveals that our gradient routing bridges the train-inference gap, and extracting semantic cues from a base model provides a robust training signal that obviates the need for external reward models.
Compositional Video Generation via Inference-Time Guidance
May 14, 2026Text-to-video diffusion models generate realistic videos, but often fail on prompts requiring fine-grained compositional understanding, such as relations between entities, attributes, actions, and motion directions. We hypothesize that these failures need not be addressed by retraining the generator, but can instead be mitigated by steering the denoising process using the model's own internal grounding signals. We propose \textbf{CVG}, an inference-time guidance method for improving compositional faithfulness in frozen text-to-video models. Our key observation is that cross-attention maps already encode how prompt concepts are grounded across space and time. We train a lightweight compositional classifier on these attention features and use its gradients during early denoising steps to steer the latent trajectory toward the desired composition. Built on a frozen VLM backbone, the classifier transfers across semantically related composition labels rather than relying only on narrow category-specific features. CVG improves compositional generation without modifying the model architecture, fine-tuning the generator, or requiring layouts, boxes, or other user-supplied controls. Experiments on compositional text-to-video benchmarks show improved prompt faithfulness while preserving the visual quality of the underlying generator.
Faithfulness Serum: Mitigating the Faithfulness Gap in Textual Explanations of LLM Decisions via Attribution Guidance
Apr 15, 2026Large language models (LLMs) achieve strong performance and have revolutionized NLP, but their lack of explainability keeps them treated as black boxes, limiting their use in domains that demand transparency and trust. A promising direction to address this issue is post-hoc text-based explanations, which aim to explain model decisions in natural language. Prior work has focused on generating convincing rationales that appear to be subjectively faithful, but it remains unclear whether these explanations are epistemically faithful, whether they reflect the internal evidence the model actually relied on for its decision. In this paper, we first assess the epistemic faithfulness of LLM-generated explanations via counterfactuals and show that they are often unfaithful. We then introduce a training-free method that enhances faithfulness by guiding explanation generation through attention-level interventions, informed by token-level heatmaps extracted via a faithful attribution method. This method significantly improves epistemic faithfulness across multiple models, benchmarks, and prompts.
ID-LoRA: Identity-Driven Audio-Video Personalization with In-Context LoRA
Mar 10, 2026Existing video personalization methods preserve visual likeness but treat video and audio separately. Without access to the visual scene, audio models cannot synchronize sounds with on-screen actions; and because classical voice-cloning models condition only on a reference recording, a text prompt cannot redirect speaking style or acoustic environment. We propose ID-LoRA (Identity-Driven In-Context LoRA), which jointly generates a subject's appearance and voice in a single model, letting a text prompt, a reference image, and a short audio clip govern both modalities together. ID-LoRA adapts the LTX-2 joint audio-video diffusion backbone via parameter-efficient In-Context LoRA and, to our knowledge, is the first method to personalize visual appearance and voice in a single generative pass. Two challenges arise. Reference and generation tokens share the same positional-encoding space, making them hard to distinguish; we address this with negative temporal positions, placing reference tokens in a disjoint RoPE region while preserving their internal temporal structure. Speaker characteristics also tend to be diluted during denoising; we introduce identity guidance, a classifier-free guidance variant that amplifies speaker-specific features by contrasting predictions with and without the reference signal. In human preference studies, ID-LoRA is preferred over Kling 2.6 Pro by 73% of annotators for voice similarity and 65% for speaking style. On cross-environment settings, speaker similarity improves by 24% over Kling, with the gap widening as conditions diverge. A preliminary user study further suggests that joint generation provides a useful inductive bias for physically grounded sound synthesis. ID-LoRA achieves these results with only ~3K training pairs on a single GPU. Code, models, and data will be released.
TokenTrim: Inference-Time Token Pruning for Autoregressive Long Video Generation
Jan 30, 2026Auto-regressive video generation enables long video synthesis by iteratively conditioning each new batch of frames on previously generated content. However, recent work has shown that such pipelines suffer from severe temporal drift, where errors accumulate and amplify over long horizons. We hypothesize that this drift does not primarily stem from insufficient model capacity, but rather from inference-time error propagation. Specifically, we contend that drift arises from the uncontrolled reuse of corrupted latent conditioning tokens during auto-regressive inference. To correct this accumulation of errors, we propose a simple, inference-time method that mitigates temporal drift by identifying and removing unstable latent tokens before they are reused for conditioning. For this purpose, we define unstable tokens as latent tokens whose representations deviate significantly from those of the previously generated batch, indicating potential corruption or semantic drift. By explicitly removing corrupted latent tokens from the auto-regressive context, rather than modifying entire spatial regions or model parameters, our method prevents unreliable latent information from influencing future generation steps. As a result, it significantly improves long-horizon temporal consistency without modifying the model architecture, training procedure, or leaving latent space.
TensorLens: End-to-End Transformer Analysis via High-Order Attention Tensors
Jan 25, 2026Attention matrices are fundamental to transformer research, supporting a broad range of applications including interpretability, visualization, manipulation, and distillation. Yet, most existing analyses focus on individual attention heads or layers, failing to account for the model's global behavior. While prior efforts have extended attention formulations across multiple heads via averaging and matrix multiplications or incorporated components such as normalization and FFNs, a unified and complete representation that encapsulates all transformer blocks is still lacking. We address this gap by introducing TensorLens, a novel formulation that captures the entire transformer as a single, input-dependent linear operator expressed through a high-order attention-interaction tensor. This tensor jointly encodes attention, FFNs, activations, normalizations, and residual connections, offering a theoretically coherent and expressive linear representation of the model's computation. TensorLens is theoretically grounded and our empirical validation shows that it yields richer representations than previous attention-aggregation methods. Our experiments demonstrate that the attention tensor can serve as a powerful foundation for developing tools aimed at interpretability and model understanding. Our code is attached as a supplementary.
AlignTree: Efficient Defense Against LLM Jailbreak Attacks
Nov 15, 2025



Large Language Models (LLMs) are vulnerable to adversarial attacks that bypass safety guidelines and generate harmful content. Mitigating these vulnerabilities requires defense mechanisms that are both robust and computationally efficient. However, existing approaches either incur high computational costs or rely on lightweight defenses that can be easily circumvented, rendering them impractical for real-world LLM-based systems. In this work, we introduce the AlignTree defense, which enhances model alignment while maintaining minimal computational overhead. AlignTree monitors LLM activations during generation and detects misaligned behavior using an efficient random forest classifier. This classifier operates on two signals: (i) the refusal direction -- a linear representation that activates on misaligned prompts, and (ii) an SVM-based signal that captures non-linear features associated with harmful content. Unlike previous methods, AlignTree does not require additional prompts or auxiliary guard models. Through extensive experiments, we demonstrate the efficiency and robustness of AlignTree across multiple LLMs and benchmarks.
Suppressing VLM Hallucinations with Spectral Representation Filtering
Nov 15, 2025



Vision-language models (VLMs) frequently produce hallucinations in the form of descriptions of objects, attributes, or relations that do not exist in the image due to over-reliance on language priors and imprecise cross-modal grounding. We introduce Spectral Representation Filtering (SRF), a lightweight, training-free method to suppress such hallucinations by analyzing and correcting the covariance structure of the model's representations. SRF identifies low-rank hallucination modes through eigendecomposition of the covariance of the differences between features collected for truthful and hallucinatory captions, revealing structured biases in the feature space. A soft spectral filter then attenuates these modes in the feed-forward projection weights of deeper vLLM layers, equalizing feature variance while preserving semantic fidelity. Unlike decoding or retraining-based approaches, SRF operates entirely post-hoc, incurs zero inference overhead, and requires no architectural modifications. Across three families of VLMs (LLaVA-1.5, MiniGPT-4, and mPLUG-Owl2), SRF consistently reduces hallucination rates on MSCOCO, POPE-VQA, and other visual tasks benchmarks, achieving state-of-the-art faithfulness without degrading caption quality.
Execution Guided Line-by-Line Code Generation
Jun 12, 2025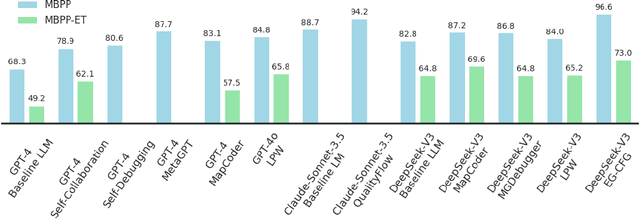
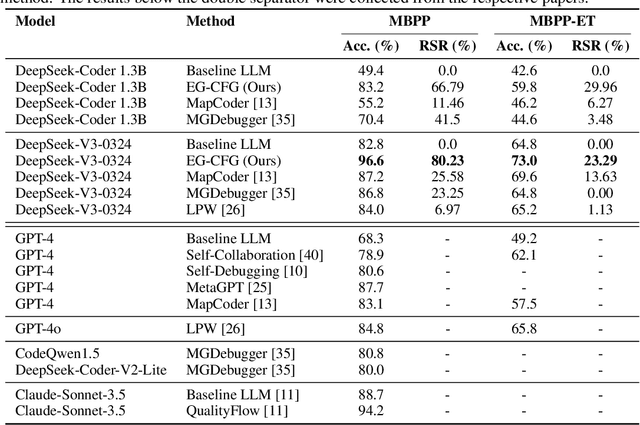
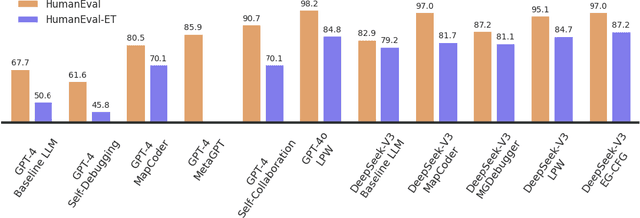
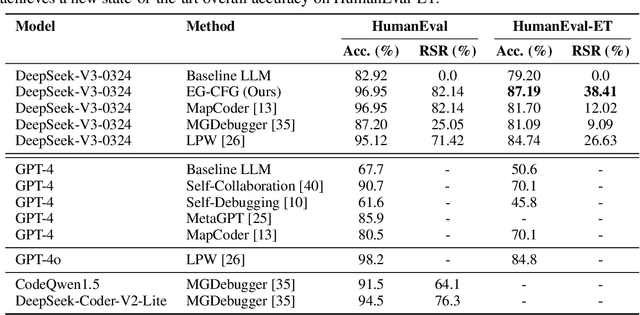
We present a novel approach to neural code generation that incorporates real-time execution signals into the language model generation process. While large language models (LLMs) have demonstrated impressive code generation capabilities, they typically do not utilize execution feedback during inference, a critical signal that human programmers regularly leverage. Our method, Execution-Guided Classifier-Free Guidance (EG-CFG), dynamically incorporates execution signals as the model generates code, providing line-by-line feedback that guides the generation process toward executable solutions. EG-CFG employs a multi-stage process: first, we conduct beam search to sample candidate program completions for each line; second, we extract execution signals by executing these candidates against test cases; and finally, we incorporate these signals into the prompt during generation. By maintaining consistent signals across tokens within the same line and refreshing signals at line boundaries, our approach provides coherent guidance while preserving syntactic structure. Moreover, the method naturally supports native parallelism at the task level in which multiple agents operate in parallel, exploring diverse reasoning paths and collectively generating a broad set of candidate solutions. Our experiments across diverse coding tasks demonstrate that EG-CFG significantly improves code generation performance compared to standard approaches, achieving state-of-the-art results across various levels of complexity, from foundational problems to challenging competitive programming tasks. Our code is available at: https://github.com/boazlavon/eg_cfg