 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier-Guided Captioning Across Modalities
Jan 03, 2025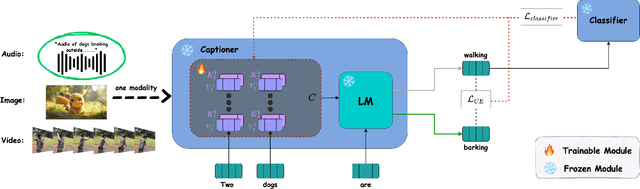
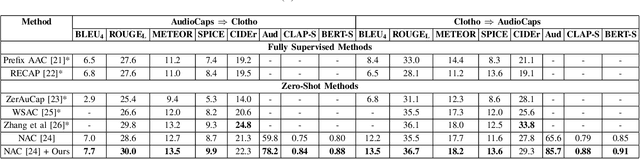
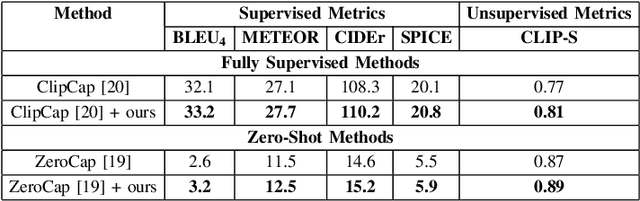
Most current captioning systems use language models trained on data from specific settings, such as image-based captioning via Amazon Mechanical Turk, limiting their ability to generalize to other modality distributions and contexts. This limitation hinders performance in tasks like audio or video captioning, where different semantic cues are needed. Addressing this challenge is crucial for creating more adaptable and versatile captioning frameworks applicable across diverse real-world contexts. In this work, we introduce a method to adapt captioning networks to the semantics of alternative settings, such as capturing audibility in audio captioning, where it is crucial to describe sounds and their sources. Our framework consists of two main components: (i) a frozen captioning system incorporating a language model (LM), and (ii) a text classifier that guides the captioning system. The classifier is trained on a dataset automatically generated by GPT-4, using tailored prompts specifically designed to enhance key aspects of the generated captions. Importantly, the framework operates solely during inference, eliminating the need for further training of the underlying captioning model. We evaluate the framework on various models and modalities, with a focus on audio captioning, and report promising results. Notably, when combined with an existing zero-shot audio captioning system, our framework improves its quality and sets state-of-the-art performance in zero-shot audio captioning.
Zero-Shot Audio Captioning via Audibility Guidance
Sep 07, 2023



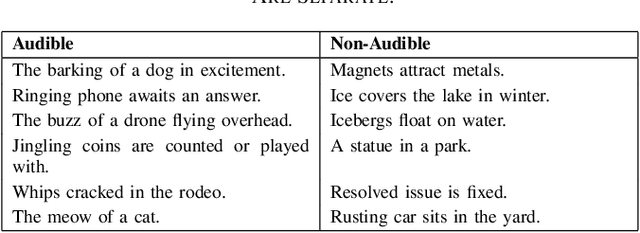
The task of audio captioning is similar in essence to tasks such as image and video captioning. However, it has received much less attention. We propose three desiderata for captioning audio -- (i) fluency of the generated text, (ii) faithfulness of the generated text to the input audio, and the somewhat related (iii) audibility, which is the quality of being able to be perceived based only on audio. Our method is a zero-shot method, i.e., we do not learn to perform captioning. Instead, captioning occurs as an inference process that involves three networks that correspond to the three desired qualities: (i) A Large Language Model, in our case, for reasons of convenience, GPT-2, (ii) A model that provides a matching score between an audio file and a text, for which we use a multimodal matching network called ImageBind, and (iii) A text classifier, trained using a dataset we collected automatically by instructing GPT-4 with prompts designed to direct the generation of both audible and inaudible sentences. We present our results on the AudioCap dataset, demonstrating that audibility guidance significantly enhances performance compared to the baseline, which lacks this objective.
Box-based Refinement for Weakly Supervised and Unsupervised Localization Tasks
Sep 07, 2023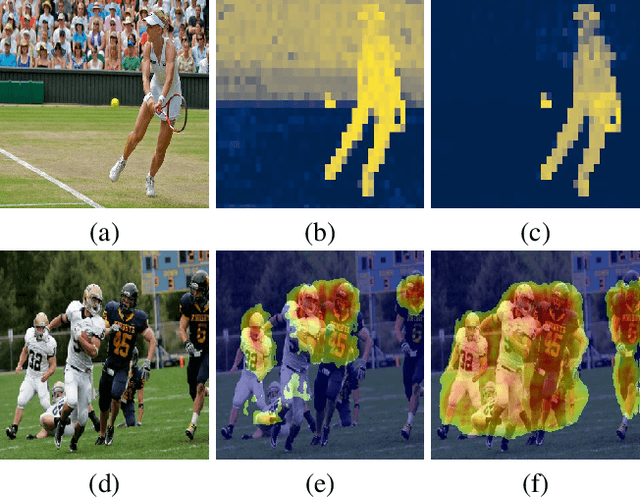



It has been established that training a box-based detector network can enhance the localization performance of weakly supervised and unsupervised methods. Moreover, we extend this understanding by demonstrating that these detectors can be utilized to improve the original network, paving the way for further advancements. To accomplish this, we train the detectors on top of the network output instead of the image data and apply suitable loss backpropagation. Our findings reveal a significant improvement in phrase grounding for the ``what is where by looking'' task, as well as various methods of unsupervised object discovery. Our code is available at https://github.com/eyalgomel/box-based-refinement.
Annotator Consensus Prediction for Medical Image Segmentation with Diffusion Models
Jun 15, 2023



A major challenge in the segmentation of medical images is the large inter- and intra-observer variability in annotations provided by multiple experts. To address this challenge, we propose a novel method for multi-expert prediction using diffusion models. Our method leverages the diffusion-based approach to incorporate information from multiple annotations and fuse it into a unified segmentation map that reflects the consensus of multiple experts. We evaluate the performance of our method on several datasets of medical segmentation annotated by multiple experts and compare it with state-of-the-art methods. Our results demonstrate the effectiveness and robustness of the proposed method. Our code is publicly available at https://github.com/tomeramit/Annotator-Consensus-Prediction.
AutoSAM: Adapting SAM to Medical Images by Overloading the Prompt Encoder
Jun 10, 2023



The recently introduced Segment Anything Model (SAM) combines a clever architecture and large quantities of training data to obtain remarkable image segmentation capabilities. However, it fails to reproduce such results for Out-Of-Distribution (OOD) domains such as medical images. Moreover, while SAM is conditioned on either a mask or a set of points, it may be desirable to have a fully automatic solution. In this work, we replace SAM's conditioning with an encoder that operates on the same input image. By adding this encoder and without further fine-tuning SAM, we obtain state-of-the-art results on multiple medical images and video benchmarks. This new encoder is trained via gradients provided by a frozen SAM. For inspecting the knowledge within it, and providing a lightweight segmentation solution, we also learn to decode it into a mask by a shallow deconvolution network.
What is Where by Looking: Weakly-Supervised Open-World Phrase-Grounding without Text Inputs
Jun 27, 2022



Given an input image, and nothing else, our method returns the bounding boxes of objects in the image and phrases that describe the objects. This is achieved within an open world paradigm, in which the objects in the input image may not have been encountered during the training of the localization mechanism. Moreover, training takes place in a weakly supervised setting, where no bounding boxes are provided. To achieve this, our method combines two pre-trained networks: the CLIP image-to-text matching score and the BLIP image captioning tool. Training takes place on COCO images and their captions and is based on CLIP. Then, during inference, BLIP is used to generate a hypothesis regarding various regions of the current image. Our work generalizes weakly supervised segmentation and phrase grounding and is shown empirically to outperform the state of the art in both domains. It also shows very convincing results in the novel task of weakly-supervised open-world purely visual phrase-grounding presented in our work. For example, on the datasets used for benchmarking phrase-grounding, our method results in a very modest degradation in comparison to methods that employ human captions as an additional input. Our code is available at https://github.com/talshaharabany/what-is-where-by-looking and a live demo can be found at https://replicate.com/talshaharabany/what-is-where-by-looking.
End-to-End Segmentation via Patch-wise Polygons Prediction
Dec 05, 2021
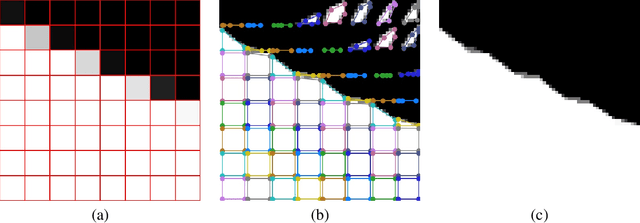
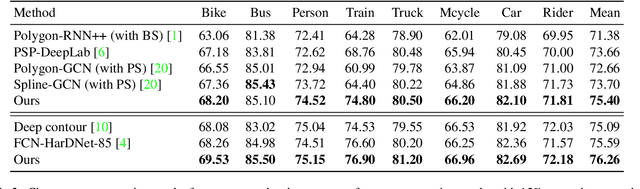
The leading segmentation methods represent the output map as a pixel grid. We study an alternative representation in which the object edges are modeled, per image patch, as a polygon with $k$ vertices that is coupled with per-patch label probabilities. The vertices are optimized by employing a differentiable neural renderer to create a raster image. The delineated region is then compared with the ground truth segmentation. Our method obtains multiple state-of-the-art results: 76.26\% mIoU on the Cityscapes validation, 90.92\% IoU on the Vaihingen building segmentation benchmark, 66.82\% IoU for the MoNU microscopy dataset, and 90.91\% for the bird benchmark CUB. Our code for training and reproducing these results is attached as supplementary.
Learning a Weight Map for Weakly-Supervised Localization
Nov 28, 2021



In the weakly supervised localization setting, supervision is given as an image-level label. We propose to employ an image classifier $f$ and to train a generative network $g$ that outputs, given the input image, a per-pixel weight map that indicates the location of the object within the image. Network $g$ is trained by minimizing the discrepancy between the output of the classifier $f$ on the original image and its output given the same image weighted by the output of $g$. The scheme requires a regularization term that ensures that $g$ does not provide a uniform weight, and an early stopping criterion in order to prevent $g$ from over-segmenting the image. Our results indicate that the method outperforms existing localization methods by a sizable margin on the challenging fine-grained classification datasets, as well as a generic image recognition dataset. Additionally, the obtained weight map is also state-of-the-art in weakly supervised segmentation in fine-grained categorization datasets.
Explainability Guided Multi-Site COVID-19 CT Classification
Mar 25, 2021



Radiologist examination of chest CT is an effective way for screening COVID-19 cases. In this work, we overcome three challenges in the automation of this process: (i) the limited number of supervised positive cases, (ii) the lack of region-based supervision, and (iii) the variability across acquisition sites. These challenges are met by incorporating a recent augmentation solution called SnapMix, by a new patch embedding technique, and by performing a test-time stability analysis. The three techniques are complementary and are all based on utilizing the heatmaps produced by the Class Activation Mapping (CAM) explainability method. Compared to the current state of the art, we obtain an increase of five percent in the F1 score on a site with a relatively high number of cases, and a gap twice as large for a site with much fewer training images.
End to End Trainable Active Contours via Differentiable Rendering
Dec 01, 2019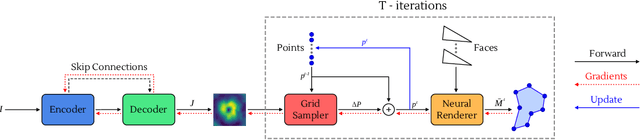
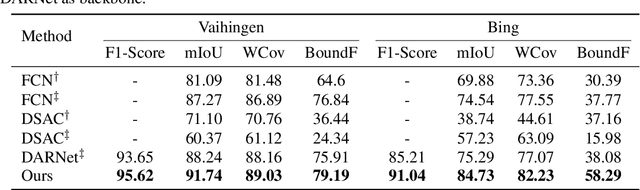

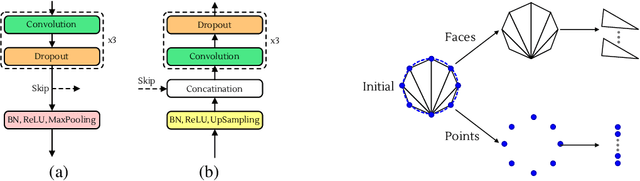
We present an image segmentation method that iteratively evolves a polygon. At each iteration, the vertices of the polygon are displaced based on the local value of a 2D shift map that is inferred from the input image via an encoder-decoder architecture. The main training loss that is used is the difference between the polygon shape and the ground truth segmentation mask. The network employs a neural renderer to create the polygon from its vertices, making the process fully differentiable. We demonstrate that our method outperforms the state of the art segmentation networks and deep active contour solutions in a variety of benchmarks, including medical imaging and aerial images. Our code is available at https://github.com/shirgur/ACDRNet.