 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuppressing VLM Hallucinations with Spectral Representation Filtering
Nov 15, 2025



Vision-language models (VLMs) frequently produce hallucinations in the form of descriptions of objects, attributes, or relations that do not exist in the image due to over-reliance on language priors and imprecise cross-modal grounding. We introduce Spectral Representation Filtering (SRF), a lightweight, training-free method to suppress such hallucinations by analyzing and correcting the covariance structure of the model's representations. SRF identifies low-rank hallucination modes through eigendecomposition of the covariance of the differences between features collected for truthful and hallucinatory captions, revealing structured biases in the feature space. A soft spectral filter then attenuates these modes in the feed-forward projection weights of deeper vLLM layers, equalizing feature variance while preserving semantic fidelity. Unlike decoding or retraining-based approaches, SRF operates entirely post-hoc, incurs zero inference overhead, and requires no architectural modifications. Across three families of VLMs (LLaVA-1.5, MiniGPT-4, and mPLUG-Owl2), SRF consistently reduces hallucination rates on MSCOCO, POPE-VQA, and other visual tasks benchmarks, achieving state-of-the-art faithfulness without degrading caption quality.
Mitigating Copy Bias in In-Context Learning through Neuron Pruning
Oct 02, 2024Large language models (LLMs) have demonstrated impressive few-shot in-context learning (ICL) abilities. Still, we show that they are sometimes prone to a `copying bias', where they copy answers from provided examples instead of learning the underlying patterns. In this work, we propose a novel and simple method to mitigate such copying bias. First, we create a synthetic task and use the Integrated Gradients method to identify neurons that prioritize copying over generalization. We demonstrate that pruning these neurons consistently improves performance across a diverse set of ICL tasks. We also show that our method is applicable across various LLM architectures, including Transformers and State-Space Models, without requiring modifications. In our analysis, we adopt a task-recognition perspective on ICL and examine task vectors (Hendel et al., 2023) induced by the model. We find that pruning enhances the quality of these vectors, suggesting that the pruned neurons previously hindered effective task recognition.
A Unified Implicit Attention Formulation for Gated-Linear Recurrent Sequence Models
May 26, 2024

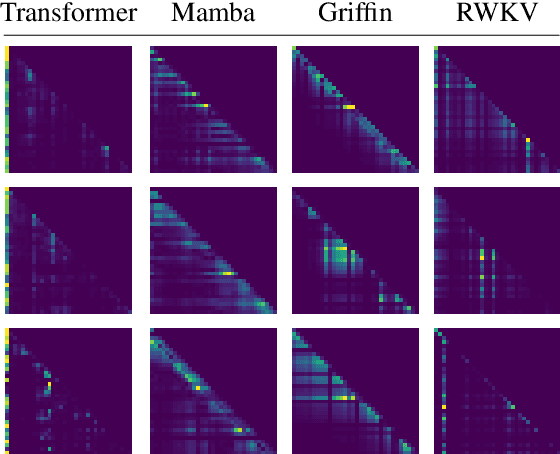

Recent advances in efficient sequence modeling have led to attention-free layers, such as Mamba, RWKV, and various gated RNNs, all featuring sub-quadratic complexity in sequence length and excellent scaling properties, enabling the construction of a new type of foundation models. In this paper, we present a unified view of these models, formulating such layers as implicit causal self-attention layers. The formulation includes most of their sub-components and is not limited to a specific part of the architecture. The framework compares the underlying mechanisms on similar grounds for different layers and provides a direct means for applying explainability methods. Our experiments show that our attention matrices and attribution method outperform an alternative and a more limited formulation that was recently proposed for Mamba. For the other architectures for which our method is the first to provide such a view, our method is effective and competitive in the relevant metrics compared to the results obtained by state-of-the-art transformer explainability methods. Our code is publicly available.
The Hidden Attention of Mamba Models
Mar 03, 2024



The Mamba layer offers an efficient selective state space model (SSM) that is highly effective in modeling multiple domains including NLP, long-range sequences processing, and computer vision. Selective SSMs are viewed as dual models, in which one trains in parallel on the entire sequence via IO-aware parallel scan, and deploys in an autoregressive manner. We add a third view and show that such models can be viewed as attention-driven models. This new perspective enables us to compare the underlying mechanisms to that of the self-attention layers in transformers and allows us to peer inside the inner workings of the Mamba model with explainability methods. Our code is publicly available.
Degree-based stratification of nodes in Graph Neural Networks
Dec 16, 2023Despite much research, Graph Neural Networks (GNNs) still do not display the favorable scaling properties of other deep neural networks such as Convolutional Neural Networks and Transformers. Previous work has identified issues such as oversmoothing of the latent representation and have suggested solutions such as skip connections and sophisticated normalization schemes. Here, we propose a different approach that is based on a stratification of the graph nodes. We provide motivation that the nodes in a graph can be stratified into those with a low degree and those with a high degree and that the two groups are likely to behave differently. Based on this motivation, we modify the Graph Neural Network (GNN) architecture so that the weight matrices are learned, separately, for the nodes in each group. This simple-to-implement modification seems to improve performance across datasets and GNN methods. To verify that this increase in performance is not only due to the added capacity, we also perform the same modification for random splits of the nodes, which does not lead to any improvement.
Centered Self-Attention Layers
Jun 02, 2023

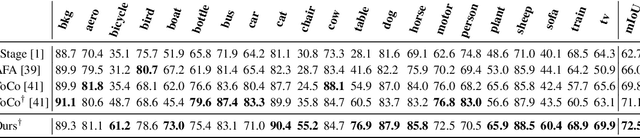
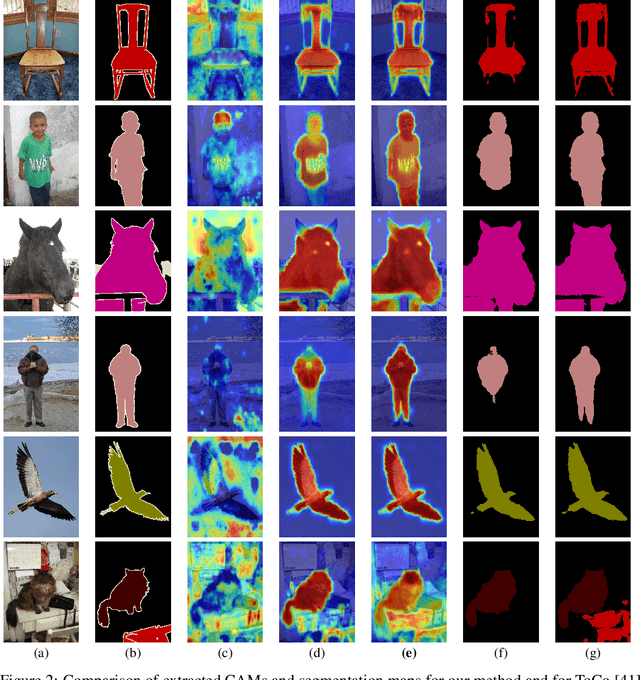
The self-attention mechanism in transformers and the message-passing mechanism in graph neural networks are repeatedly applied within deep learning architectures. We show that this application inevitably leads to oversmoothing, i.e., to similar representations at the deeper layers for different tokens in transformers and different nodes in graph neural networks. Based on our analysis, we present a correction term to the aggregating operator of these mechanisms. Empirically, this simple term eliminates much of the oversmoothing problem in visual transformers, obtaining performance in weakly supervised segmentation that surpasses elaborate baseline methods that introduce multiple auxiliary networks and training phrases. In graph neural networks, the correction term enables the training of very deep architectures more effectively than many recent solutions to the same problem.
XAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022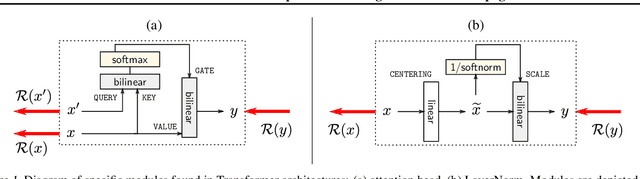
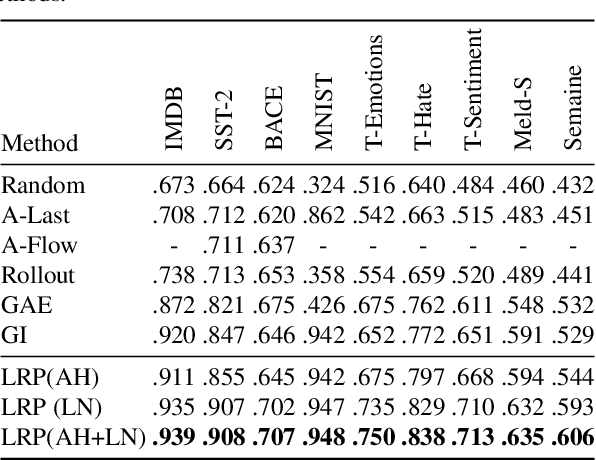
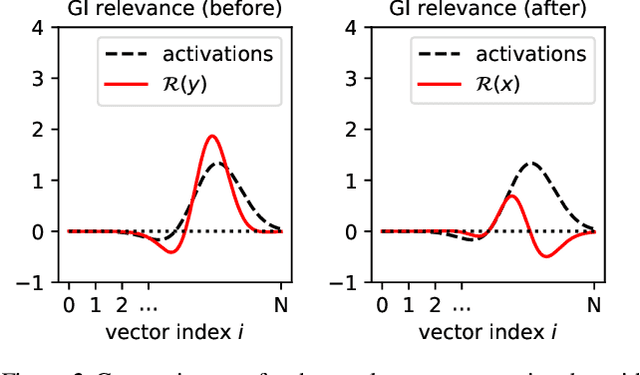
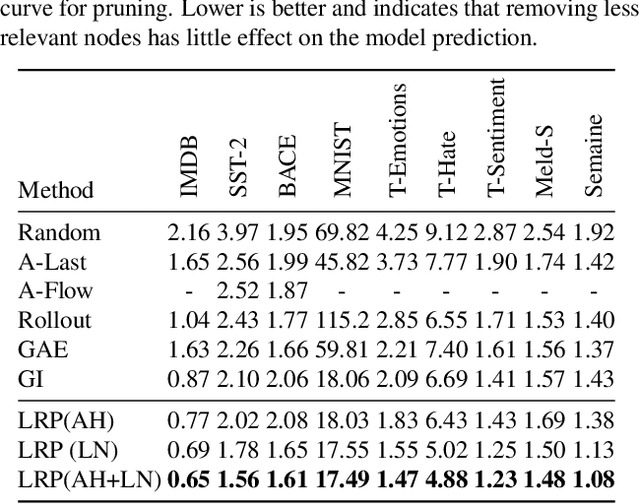
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.
Video and Text Matching with Conditioned Embeddings
Oct 21, 2021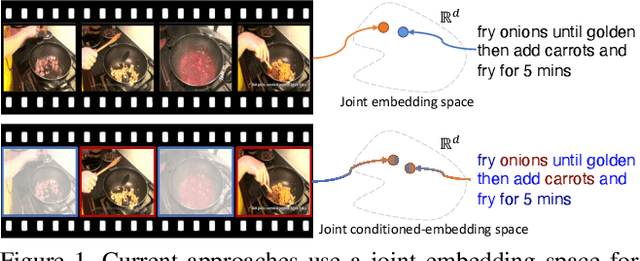
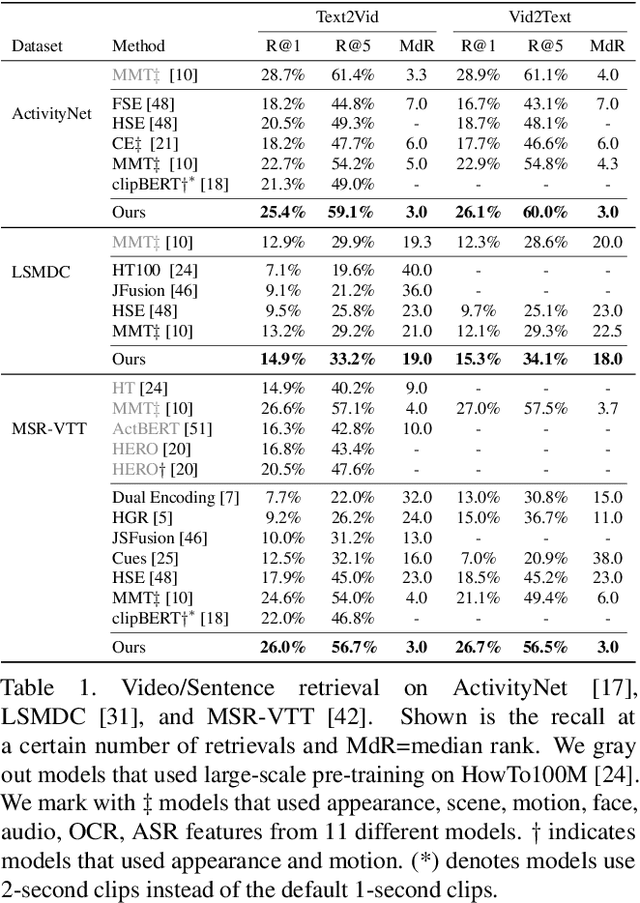
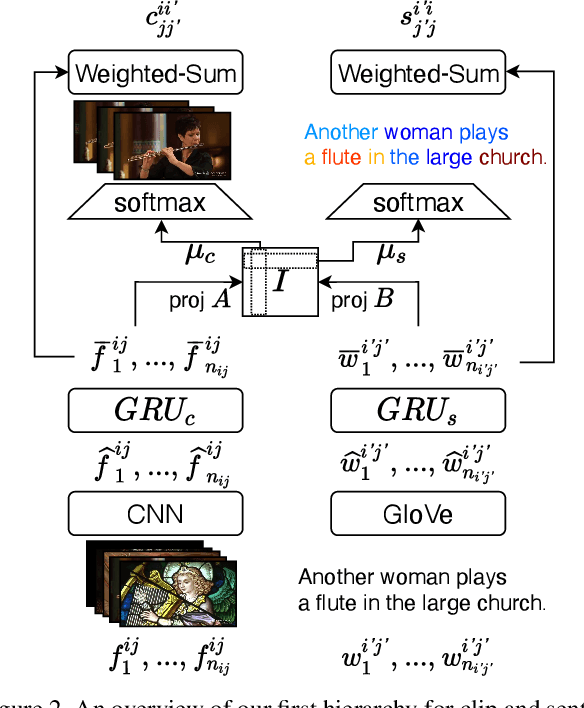

We present a method for matching a text sentence from a given corpus to a given video clip and vice versa. Traditionally video and text matching is done by learning a shared embedding space and the encoding of one modality is independent of the other. In this work, we encode the dataset data in a way that takes into account the query's relevant information. The power of the method is demonstrated to arise from pooling the interaction data between words and frames. Since the encoding of the video clip depends on the sentence compared to it, the representation needs to be recomputed for each potential match. To this end, we propose an efficient shallow neural network. Its training employs a hierarchical triplet loss that is extendable to paragraph/video matching. The method is simple, provides explainability, and achieves state-of-the-art results for both sentence-clip and video-text by a sizable margin across five different datasets: ActivityNet, DiDeMo, YouCook2, MSR-VTT, and LSMDC. We also show that our conditioned representation can be transferred to video-guided machine translation, where we improved the current results on VATEX. Source code is available at https://github.com/AmeenAli/VideoMatch.
Explainability Guided Multi-Site COVID-19 CT Classification
Mar 25, 2021



Radiologist examination of chest CT is an effective way for screening COVID-19 cases. In this work, we overcome three challenges in the automation of this process: (i) the limited number of supervised positive cases, (ii) the lack of region-based supervision, and (iii) the variability across acquisition sites. These challenges are met by incorporating a recent augmentation solution called SnapMix, by a new patch embedding technique, and by performing a test-time stability analysis. The three techniques are complementary and are all based on utilizing the heatmaps produced by the Class Activation Mapping (CAM) explainability method. Compared to the current state of the art, we obtain an increase of five percent in the F1 score on a site with a relatively high number of cases, and a gap twice as large for a site with much fewer training images.
Intersection Regularization for Extracting Semantic Attributes
Mar 22, 2021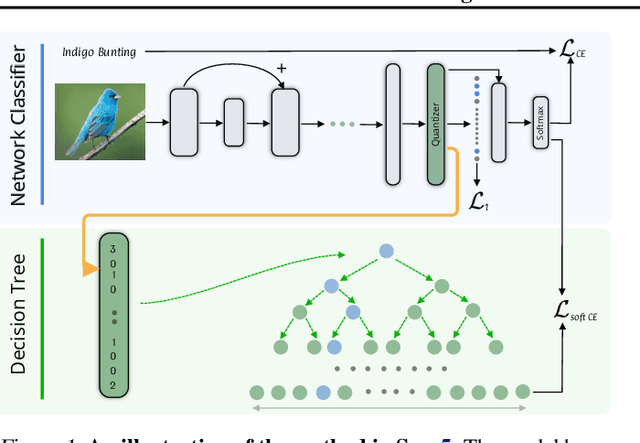
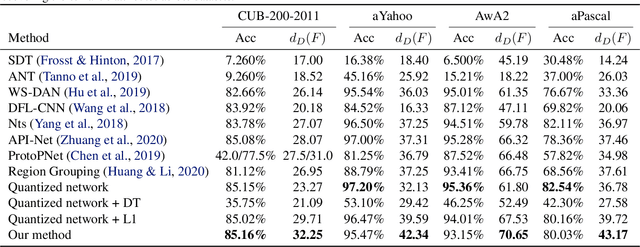

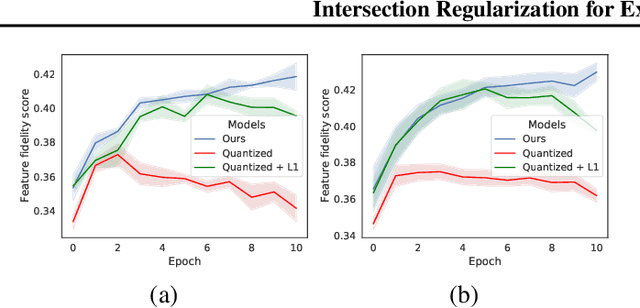
We consider the problem of supervised classification, such that the features that the network extracts match an unseen set of semantic attributes, without any additional supervision. For example, when learning to classify images of birds into species, we would like to observe the emergence of features that zoologists use to classify birds. We propose training a neural network with discrete top-level activations, which is followed by a multi-layered perceptron (MLP) and a parallel decision tree. We present a theoretical analysis as well as a practical method for learning in the intersection of two hypothesis classes. Since real-world features are often sparse, a randomized sparsity regularization is also applied. Our results on multiple benchmarks show an improved ability to extract a set of features that are highly correlated with the set of unseen attributes.