 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Bubble: Asynchronous Pipeline Parallel Training with Bounded Weight Inconsistency
Jun 05, 2026Pipeline parallelism is essential for training large neural networks, but existing schedules trade off throughput, memory, and optimization consistency. Synchronous pipelines preserve forward/backward weight consistency but suffer from bubbles; asynchronous pipelines remove bubbles but introduce weight-version mismatch, typically requiring weight stashing, prediction, or correction mechanisms. We introduce PACI (Pipeline Asynchronous training with Controlled Inconsistency), a bubble-free asynchronous pipeline method that bounds forward/backward version drift without weight stashing, prediction, additional parameter copies, or global synchronization. The key idea is to use local gradient accumulation as a version-control mechanism: by slowing parameter-version evolution relative to pipeline delay, PACI limits the number of optimizer updates crossed by any micro-batch while preserving steady-state utilization. In GPT-style language-model pretraining, PACI matches the stability and final perplexity of synchronous 1F1B-flush, retains the same peak memory footprint, achieves fully utilized pipeline throughput, and improves training time-to-accuracy by up to $1.69\times$ over the fastest flush baseline. These results show that forward/backward inconsistency need not be eliminated: when explicitly bounded, it can be safely traded for substantial efficiency gains.
Structured Diffusion Bridges: Inductive Bias for Denoising Diffusion Bridges
May 06, 2026Modality translation is inherently under-constrained, as multiple cross-modal mappings may yield the same marginals. Recent work has shown that diffusion bridges are effective for this task. However, most existing approaches rely on fully paired datasets, thereby imposing a single data-driven constraint. We propose a diffusion-bridge framework that characterizes the space of admissible solutions and restricts it via alignment constraints, treating paired supervision as an optional heuristic rather than a prerequisite. We validate our method on synthetic and real modality translation benchmarks across unpaired, semi-paired, and paired regimes, showing consistent performance across supervision levels. Notably, \textbf{it achieves near fully-paired quality with a substantial relaxation in pairing requirements, and remaining applicable in the unpaired regime}. These results highlight diffusion bridges as a flexible foundation for modality translation beyond fully paired data.
Cross-Instance Gaussian Splatting Registration via Geometry-Aware Feature-Guided Alignment
Mar 23, 2026We present Gaussian Splatting Alignment (GSA), a novel method for aligning two independent 3D Gaussian Splatting (3DGS) models via a similarity transformation (rotation, translation, and scale), even when they are of different objects in the same category (e.g., different cars). In contrast, existing methods can only align 3DGS models of the same object (e.g., the same car) and often must be given true scale as input, while we estimate it successfully. GSA leverages viewpoint-guided spherical map features to obtain robust correspondences and introduces a two-step optimization framework that aligns 3DGS models while keeping them fixed. First, we apply an iterative feature-guided absolute orientation solver as our coarse registration, which is robust to poor initialization (e.g., 180 degrees misalignment or a 10x scale gap). Next, we use a fine registration step that enforces multi-view feature consistency, inspired by inverse radiance-field formulations. The first step already achieves state-of-the-art performance, and the second further improves results. In the same-object case, GSA outperforms prior works, often by a large margin, even when the other methods are given the true scale. In the harder case of different objects in the same category, GSA vastly surpasses them, providing the first effective solution for category-level 3DGS registration and unlocking new applications. Project webpage: https://bgu-cs-vil.github.io/GSA-project/
HiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
Mar 19, 2026Long-form video question answering requires reasoning over extended temporal contexts, making frame selection critical for large vision-language models (LVLMs) bound by finite context windows. Existing methods face a sharp trade-off: similarity-based selectors are fast but collapse compositional queries into a single dense vector, losing sub-event ordering and cross-modal bindings; agent-based methods recover this structure through iterative LVLM inference, but at prohibitive cost. We introduce HiMu, a training-free framework that bridges this gap. A single text-only LLM call decomposes the query into a hierarchical logic tree whose leaves are atomic predicates, each routed to a lightweight expert spanning vision (CLIP, open-vocabulary detection, OCR) and audio (ASR, CLAP). The resulting signals are normalized, temporally smoothed to align different modalities, and composed bottom-up through fuzzy-logic operators that enforce temporal sequencing and adjacency, producing a continuous satisfaction curve. Evaluations on Video-MME, LongVideoBench and HERBench-Lite show that HiMu advances the efficiency-accuracy Pareto front: at 16 frames with Qwen3-VL 8B it outperforms all competing selectors, and with GPT-4o it surpasses agentic systems operating at 32-512 frames while requiring roughly 10x fewer FLOPs.
Look Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
Mar 14, 2026Vision-language models (VLMs) typically process images at a native high-resolution, forcing a trade-off between accuracy and computational efficiency: high-resolution inputs capture fine details but incur significant computational costs, while low-resolution inputs advocate for efficiency, they potentially miss critical visual information, like small text. We present AwaRes, a spatial-on-demand framework that resolves this accuracy-efficiency trade-off by operating on a low-resolution global view and using tool-calling to retrieve only high-resolution segments needed for a given query. We construct supervised data automatically: a judge compares low- vs.\ high-resolution answers to label whether cropping is needed, and an oracle grounding model localizes the evidence for the correct answer, which we map to a discrete crop set to form multi-turn tool-use trajectories. We train our framework with cold-start SFT followed by multi-turn GRPO with a composite reward that combines semantic answer correctness with explicit crop-cost penalties. Project page: https://nimrodshabtay.github.io/AwaRes
Step-Wise Refusal Dynamics in Autoregressive and Diffusion Language Models
Feb 01, 2026Diffusion language models (DLMs) have recently emerged as a promising alternative to autoregressive (AR) models, offering parallel decoding and controllable sampling dynamics while achieving competitive generation quality at scale. Despite this progress, the role of sampling mechanisms in shaping refusal behavior and jailbreak robustness remains poorly understood. In this work, we present a fundamental analytical framework for step-wise refusal dynamics, enabling comparison between AR and diffusion sampling. Our analysis reveals that the sampling strategy itself plays a central role in safety behavior, as a factor distinct from the underlying learned representations. Motivated by this analysis, we introduce the Step-Wise Refusal Internal Dynamics (SRI) signal, which supports interpretability and improved safety for both AR and DLMs. We demonstrate that the geometric structure of SRI captures internal recovery dynamics, and identifies anomalous behavior in harmful generations as cases of \emph{incomplete internal recovery} that are not observable at the text level. This structure enables lightweight inference-time detectors that generalize to unseen attacks while matching or outperforming existing defenses with over $100\times$ lower inference overhead.
PREGEN: Uncovering Latent Thoughts in Composed Video Retrieval
Jan 20, 2026Composed Video Retrieval (CoVR) aims to retrieve a video based on a query video and a modifying text. Current CoVR methods fail to fully exploit modern Vision-Language Models (VLMs), either using outdated architectures or requiring computationally expensive fine-tuning and slow caption generation. We introduce PREGEN (PRE GENeration extraction), an efficient and powerful CoVR framework that overcomes these limitations. Our approach uniquely pairs a frozen, pre-trained VLM with a lightweight encoding model, eliminating the need for any VLM fine-tuning. We feed the query video and modifying text into the VLM and extract the hidden state of the final token from each layer. A simple encoder is then trained on these pooled representations, creating a semantically rich and compact embedding for retrieval. PREGEN significantly advances the state of the art, surpassing all prior methods on standard CoVR benchmarks with substantial gains in Recall@1 of +27.23 and +69.59. Our method demonstrates robustness across different VLM backbones and exhibits strong zero-shot generalization to more complex textual modifications, highlighting its effectiveness and semantic capabilities.
HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering
Dec 16, 2025



Video Large Language Models (Video-LLMs) are rapidly improving, yet current Video Question Answering (VideoQA) benchmarks often allow questions to be answered from a single salient cue, under-testing reasoning that must aggregate multiple, temporally separated visual evidence. We present HERBench, a VideoQA benchmark purpose-built to assess multi-evidence integration across time. Each question requires aggregating at least three non-overlapping evidential cues across distinct video segments, so neither language priors nor a single snapshot can suffice. HERBench comprises 26K five-way multiple-choice questions organized into twelve compositional tasks that probe identity binding, cross-entity relations, temporal ordering, co-occurrence verification, and counting. To make evidential demand measurable, we introduce the Minimum Required Frame-Set (MRFS), the smallest number of frames a model must fuse to answer correctly, and show that HERBench imposes substantially higher demand than prior datasets (mean MRFS 5.5 vs. 2.6-4.2). Evaluating 13 state-of-the-art Video-LLMs on HERBench reveals pervasive failures: accuracies of 31-42% are only slightly above the 20% random-guess baseline. We disentangle this failure into two critical bottlenecks: (1) a retrieval deficit, where frame selectors overlook key evidence, and (2) a fusion deficit, where models fail to integrate information even when all necessary evidence is provided. By making cross-time evidence both unavoidable and quantifiable, HERBench establishes a principled target for advancing robust, compositional video understanding.
Revisiting Node Affinity Prediction in Temporal Graphs
Oct 08, 2025Node affinity prediction is a common task that is widely used in temporal graph learning with applications in social and financial networks, recommender systems, and more. Recent works have addressed this task by adapting state-of-the-art dynamic link property prediction models to node affinity prediction. However, simple heuristics, such as Persistent Forecast or Moving Average, outperform these models. In this work, we analyze the challenges in training current Temporal Graph Neural Networks for node affinity prediction and suggest appropriate solutions. Combining the solutions, we develop NAViS - Node Affinity prediction model using Virtual State, by exploiting the equivalence between heuristics and state space models. While promising, training NAViS is non-trivial. Therefore, we further introduce a novel loss function for node affinity prediction. We evaluate NAViS on TGB and show that it outperforms the state-of-the-art, including heuristics. Our source code is available at https://github.com/orfeld415/NAVIS
FLASH: Flexible Learning of Adaptive Sampling from History in Temporal Graph Neural Networks
Apr 09, 2025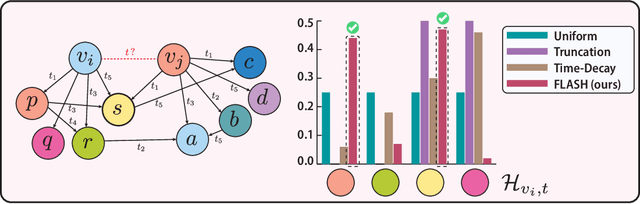

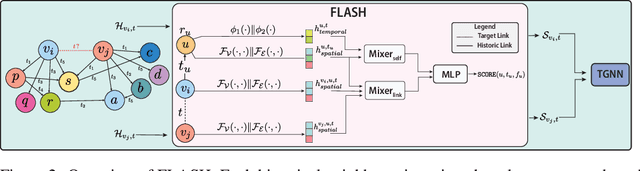

Aggregating temporal signals from historic interactions is a key step in future link prediction on dynamic graphs. However, incorporating long histories is resource-intensive. Hence, temporal graph neural networks (TGNNs) often rely on historical neighbors sampling heuristics such as uniform sampling or recent neighbors selection. These heuristics are static and fail to adapt to the underlying graph structure. We introduce FLASH, a learnable and graph-adaptive neighborhood selection mechanism that generalizes existing heuristics. FLASH integrates seamlessly into TGNNs and is trained end-to-end using a self-supervised ranking loss. We provide theoretical evidence that commonly used heuristics hinders TGNNs performance, motivating our design. Extensive experiments across multiple benchmarks demonstrate consistent and significant performance improvements for TGNNs equipped with FLASH.