 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Prompt Tuning: Advancing In-Context Learning with Adversarial Methods
Oct 22, 2024Fine-tuning Large Language Models (LLMs) typically involves updating at least a few billions of parameters. A more parameter-efficient approach is Prompt Tuning (PT), which updates only a few learnable tokens, and differently, In-Context Learning (ICL) adapts the model to a new task by simply including examples in the input without any training. When applying optimization-based methods, such as fine-tuning and PT for few-shot learning, the model is specifically adapted to the small set of training examples, whereas ICL leaves the model unchanged. This distinction makes traditional learning methods more prone to overfitting; in contrast, ICL is less sensitive to the few-shot scenario. While ICL is not prone to overfitting, it does not fully extract the information that exists in the training examples. This work introduces Context-aware Prompt Tuning (CPT), a method inspired by ICL, PT, and adversarial attacks. We build on the ICL strategy of concatenating examples before the input, but we extend this by PT-like learning, refining the context embedding through iterative optimization to extract deeper insights from the training examples. We carefully modify specific context tokens, considering the unique structure of input and output formats. Inspired by adversarial attacks, we adjust the input based on the labels present in the context, focusing on minimizing, rather than maximizing, the loss. Moreover, we apply a projected gradient descent algorithm to keep token embeddings close to their original values, under the assumption that the user-provided data is inherently valuable. Our method has been shown to achieve superior accuracy across multiple classification tasks using various LLM models.
Conceptual Learning via Embedding Approximations for Reinforcing Interpretability and Transparency
Jun 13, 2024



Concept bottleneck models (CBMs) have emerged as critical tools in domains where interpretability is paramount. These models rely on predefined textual descriptions, referred to as concepts, to inform their decision-making process and offer more accurate reasoning. As a result, the selection of concepts used in the model is of utmost significance. This study proposes \underline{\textbf{C}}onceptual \underline{\textbf{L}}earning via \underline{\textbf{E}}mbedding \underline{\textbf{A}}pproximations for \underline{\textbf{R}}einforcing Interpretability and Transparency, abbreviated as CLEAR, a framework for constructing a CBM for image classification. Using score matching and Langevin sampling, we approximate the embedding of concepts within the latent space of a vision-language model (VLM) by learning the scores associated with the joint distribution of images and concepts. A concept selection process is then employed to optimize the similarity between the learned embeddings and the predefined ones. The derived bottleneck offers insights into the CBM's decision-making process, enabling more comprehensive interpretations. Our approach was evaluated through extensive experiments and achieved state-of-the-art performance on various benchmarks. The code for our experiments is available at https://github.com/clearProject/CLEAR/tree/main
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


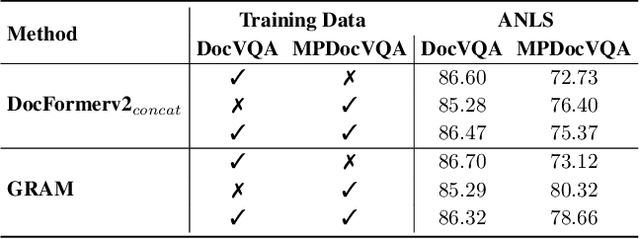
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.
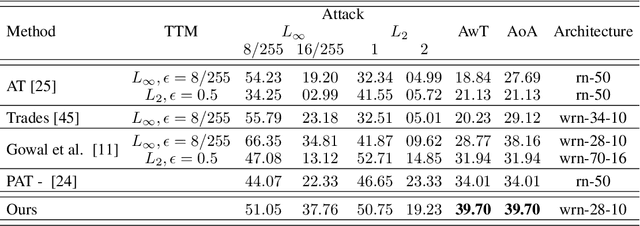
Classifier Robustness Enhancement Via Test-Time Transformation
Mar 27, 2023



It has been recently discovered that adversarially trained classifiers exhibit an intriguing property, referred to as perceptually aligned gradients (PAG). PAG implies that the gradients of such classifiers possess a meaningful structure, aligned with human perception. Adversarial training is currently the best-known way to achieve classification robustness under adversarial attacks. The PAG property, however, has yet to be leveraged for further improving classifier robustness. In this work, we introduce Classifier Robustness Enhancement Via Test-Time Transformation (TETRA) -- a novel defense method that utilizes PAG, enhancing the performance of trained robust classifiers. Our method operates in two phases. First, it modifies the input image via a designated targeted adversarial attack into each of the dataset's classes. Then, it classifies the input image based on the distance to each of the modified instances, with the assumption that the shortest distance relates to the true class. We show that the proposed method achieves state-of-the-art results and validate our claim through extensive experiments on a variety of defense methods, classifier architectures, and datasets. We also empirically demonstrate that TETRA can boost the accuracy of any differentiable adversarial training classifier across a variety of attacks, including ones unseen at training. Specifically, applying TETRA leads to substantial improvement of up to $+23\%$, $+20\%$, and $+26\%$ on CIFAR10, CIFAR100, and ImageNet, respectively.
Threat Model-Agnostic Adversarial Defense using Diffusion Models
Jul 17, 2022
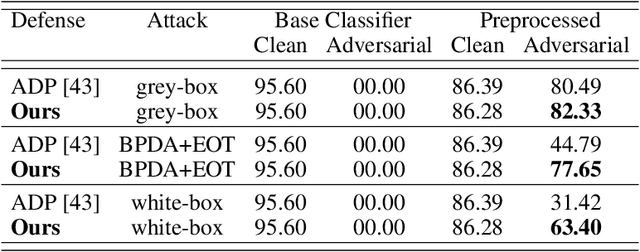

Deep Neural Networks (DNNs) are highly sensitive to imperceptible malicious perturbations, known as adversarial attacks. Following the discovery of this vulnerability in real-world imaging and vision applications, the associated safety concerns have attracted vast research attention, and many defense techniques have been developed. Most of these defense methods rely on adversarial training (AT) -- training the classification network on images perturbed according to a specific threat model, which defines the magnitude of the allowed modification. Although AT leads to promising results, training on a specific threat model fails to generalize to other types of perturbations. A different approach utilizes a preprocessing step to remove the adversarial perturbation from the attacked image. In this work, we follow the latter path and aim to develop a technique that leads to robust classifiers across various realizations of threat models. To this end, we harness the recent advances in stochastic generative modeling, and means to leverage these for sampling from conditional distributions. Our defense relies on an addition of Gaussian i.i.d noise to the attacked image, followed by a pretrained diffusion process -- an architecture that performs a stochastic iterative process over a denoising network, yielding a high perceptual quality denoised outcome. The obtained robustness with this stochastic preprocessing step is validated through extensive experiments on the CIFAR-10 dataset, showing that our method outperforms the leading defense methods under various threat models.