 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDODO: Discrete OCR Diffusion Models
Feb 18, 2026Optical Character Recognition (OCR) is a fundamental task for digitizing information, serving as a critical bridge between visual data and textual understanding. While modern Vision-Language Models (VLM) have achieved high accuracy in this domain, they predominantly rely on autoregressive decoding, which becomes computationally expensive and slow for long documents as it requires a sequential forward pass for every generated token. We identify a key opportunity to overcome this bottleneck: unlike open-ended generation, OCR is a highly deterministic task where the visual input strictly dictates a unique output sequence, theoretically enabling efficient, parallel decoding via diffusion models. However, we show that existing masked diffusion models fail to harness this potential; those introduce structural instabilities that are benign in flexible tasks, like captioning, but catastrophic for the rigid, exact-match requirements of OCR. To bridge this gap, we introduce DODO, the first VLM to utilize block discrete diffusion and unlock its speedup potential for OCR. By decomposing generation into blocks, DODO mitigates the synchronization errors of global diffusion. Empirically, our method achieves near state-of-the-art accuracy while enabling up to 3x faster inference compared to autoregressive baselines.
DNN-based 3D Cloud Retrieval for Variable Solar Illumination and Multiview Spaceborne Imaging
Nov 07, 2024



Climate studies often rely on remotely sensed images to retrieve two-dimensional maps of cloud properties. To advance volumetric analysis, we focus on recovering the three-dimensional (3D) heterogeneous extinction coefficient field of shallow clouds using multiview remote sensing data. Climate research requires large-scale worldwide statistics. To enable scalable data processing, previous deep neural networks (DNNs) can infer at spaceborne remote sensing downlink rates. However, prior methods are limited to a fixed solar illumination direction. In this work, we introduce the first scalable DNN-based system for 3D cloud retrieval that accommodates varying camera poses and solar directions. By integrating multiview cloud intensity images with camera poses and solar direction data, we achieve greater flexibility in recovery. Training of the DNN is performed by a novel two-stage scheme to address the high number of degrees of freedom in this problem. Our approach shows substantial improvements over previous state-of-the-art, particularly in handling variations in the sun's zenith angle.
Learned 3D volumetric recovery of clouds and its uncertainty for climate analysis
Mar 09, 2024



Significant uncertainty in climate prediction and cloud physics is tied to observational gaps relating to shallow scattered clouds. Addressing these challenges requires remote sensing of their three-dimensional (3D) heterogeneous volumetric scattering content. This calls for passive scattering computed tomography (CT). We design a learning-based model (ProbCT) to achieve CT of such clouds, based on noisy multi-view spaceborne images. ProbCT infers - for the first time - the posterior probability distribution of the heterogeneous extinction coefficient, per 3D location. This yields arbitrary valuable statistics, e.g., the 3D field of the most probable extinction and its uncertainty. ProbCT uses a neural-field representation, making essentially real-time inference. ProbCT undergoes supervised training by a new labeled multi-class database of physics-based volumetric fields of clouds and their corresponding images. To improve out-of-distribution inference, we incorporate self-supervised learning through differential rendering. We demonstrate the approach in simulations and on real-world data, and indicate the relevance of 3D recovery and uncertainty to precipitation and renewable energy.
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


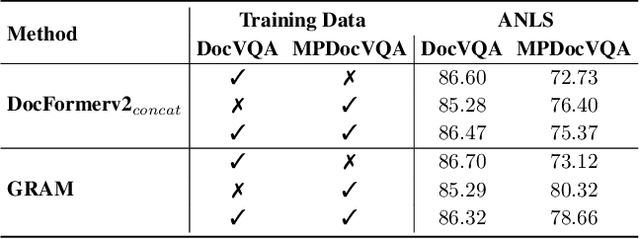
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.
Towards A Most Probable Recovery in Optical Imaging
Dec 06, 2022



Light is a complex-valued field. The intensity and phase of the field are affected by imaged objects. However, imaging sensors measure only real-valued non-negative intensities. This results in a nonlinear relation between the measurements and the unknown imaged objects. Moreover, the sensor readouts are corrupted by Poissonian-distributed photon noise. In this work, we seek the most probable object (or clear image), given noisy measurements, that is, maximizing the a-posteriori probability of the sought variables. Hence, we generalize annealed Langevin dynamics, tackling fundamental challenges in optical imaging, including phase recovery and Poisson (photon) denoising. We leverage deep neural networks, not for explicit recovery of the imaged object, but as an approximate gradient for a prior term. We show results on empirical data, acquired by a real experiment. We further show results of simulations.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022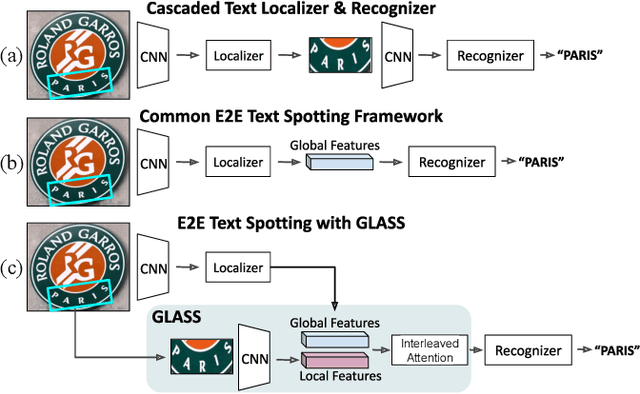
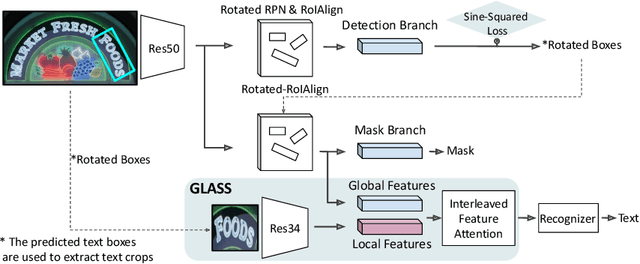
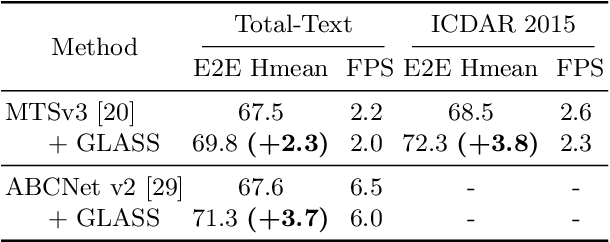
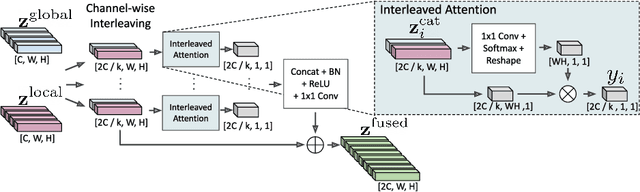
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
Spatiotemporal tomography based on scattered multiangular signals and its application for resolving evolving clouds using moving platforms
Dec 06, 2020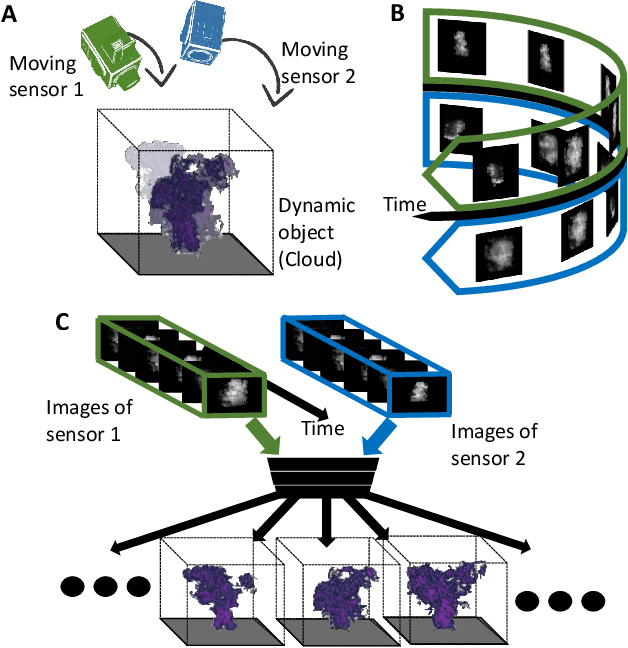
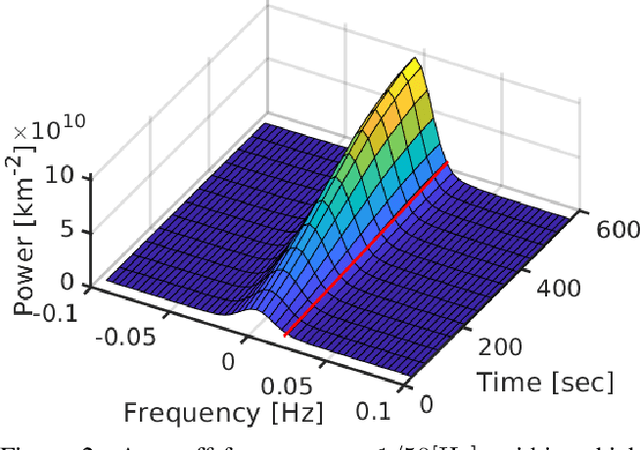
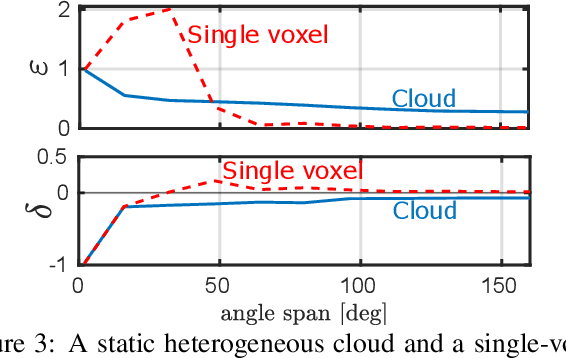
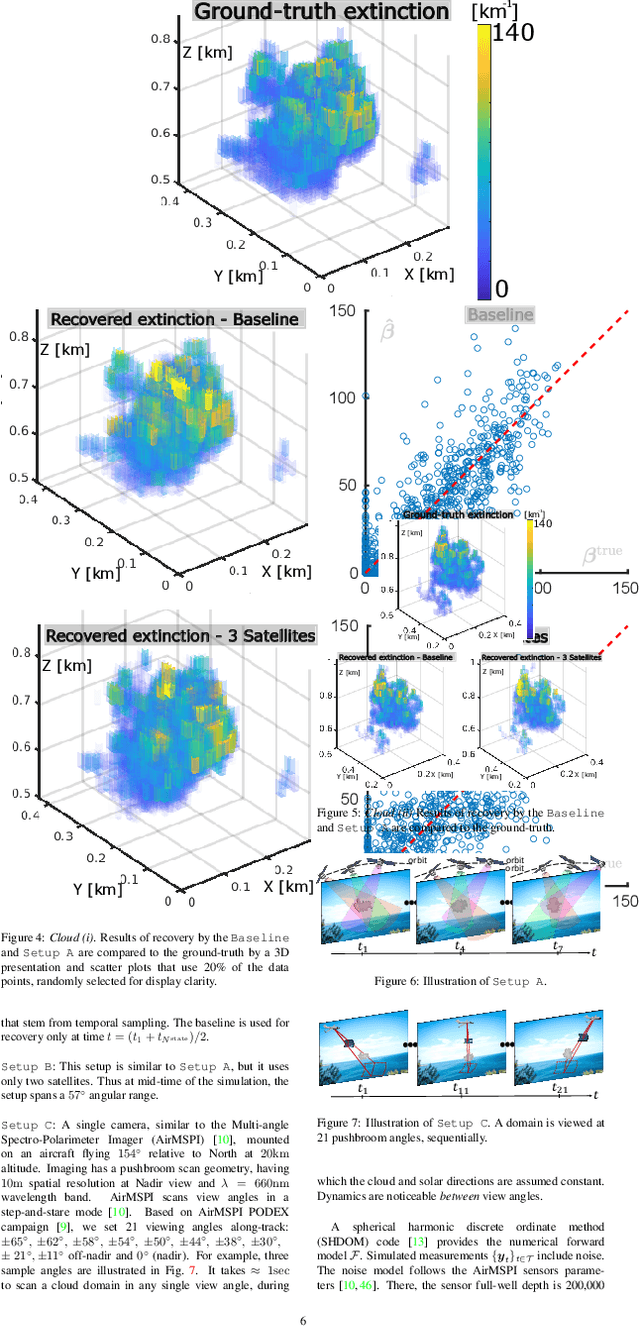
We derive computed tomography (CT) of a time-varying volumetric translucent object, using a small number of moving cameras. We particularly focus on passive scattering tomography, which is a non-linear problem. We demonstrate the approach on dynamic clouds, as clouds have a major effect on Earth's climate. State of the art scattering CT assumes a static object. Existing 4D CT methods rely on a linear image formation model and often on significant priors. In this paper, the angular and temporal sampling rates needed for a proper recovery are discussed. If these rates are used, the paper leads to a representation of the time-varying object, which simplifies 4D CT tomography. The task is achieved using gradient-based optimization. We demonstrate this in physics-based simulations and in an experiment that had yielded real-world data.