 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDODO: Discrete OCR Diffusion Models
Feb 18, 2026Optical Character Recognition (OCR) is a fundamental task for digitizing information, serving as a critical bridge between visual data and textual understanding. While modern Vision-Language Models (VLM) have achieved high accuracy in this domain, they predominantly rely on autoregressive decoding, which becomes computationally expensive and slow for long documents as it requires a sequential forward pass for every generated token. We identify a key opportunity to overcome this bottleneck: unlike open-ended generation, OCR is a highly deterministic task where the visual input strictly dictates a unique output sequence, theoretically enabling efficient, parallel decoding via diffusion models. However, we show that existing masked diffusion models fail to harness this potential; those introduce structural instabilities that are benign in flexible tasks, like captioning, but catastrophic for the rigid, exact-match requirements of OCR. To bridge this gap, we introduce DODO, the first VLM to utilize block discrete diffusion and unlock its speedup potential for OCR. By decomposing generation into blocks, DODO mitigates the synchronization errors of global diffusion. Empirically, our method achieves near state-of-the-art accuracy while enabling up to 3x faster inference compared to autoregressive baselines.
VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
Jul 17, 2024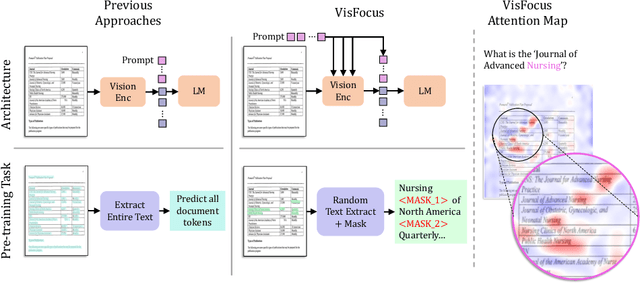
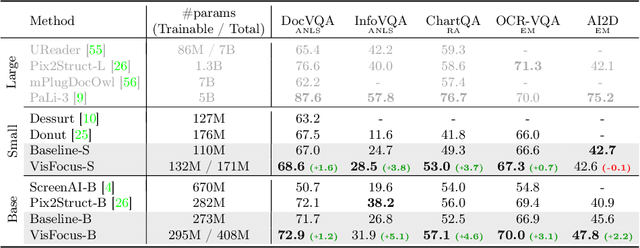
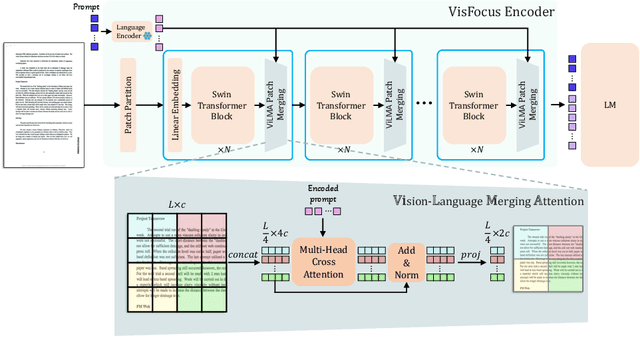

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models. The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches, or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches. Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder's capacity by coupling it directly with the language prompt. To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities. Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


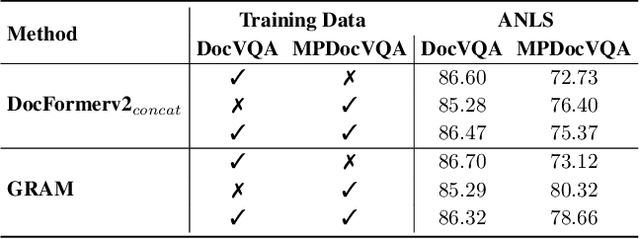
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022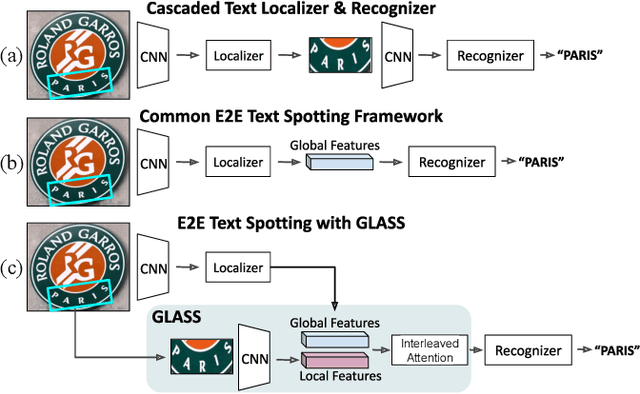
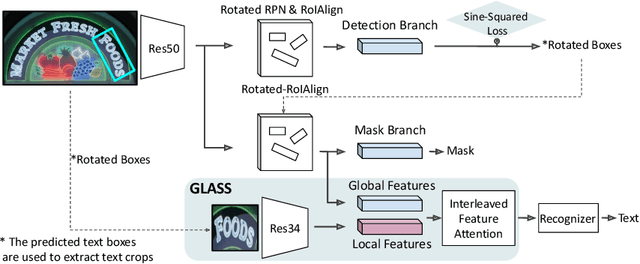
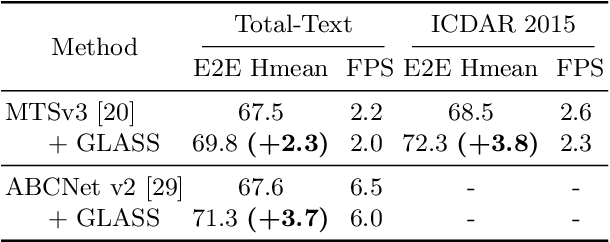
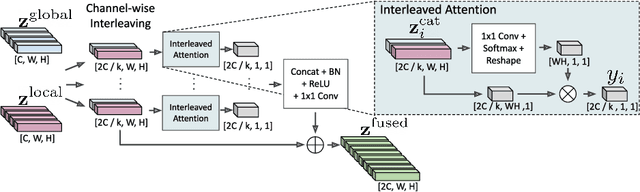
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
On Calibration of Scene-Text Recognition Models
Dec 23, 2020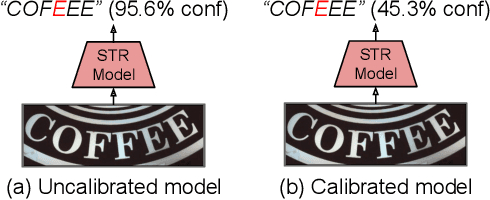
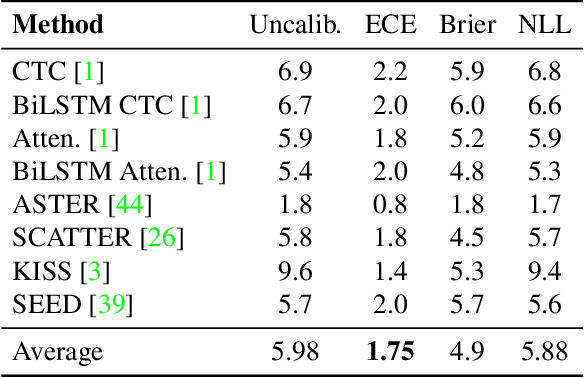
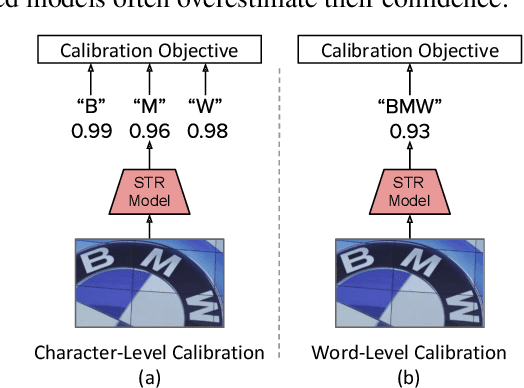
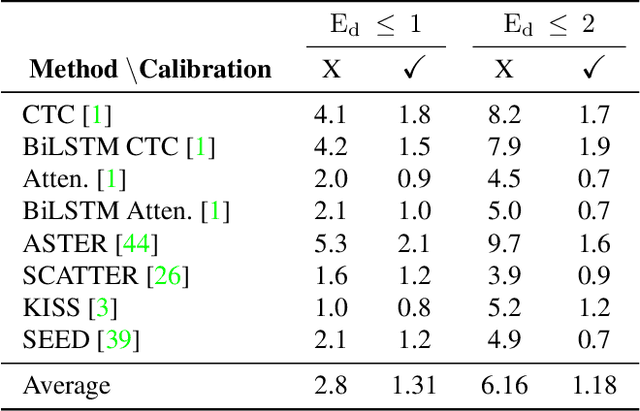
In this work, we study the problem of word-level confidence calibration for scene-text recognition (STR). Although the topic of confidence calibration has been an active research area for the last several decades, the case of structured and sequence prediction calibration has been scarcely explored. We analyze several recent STR methods and show that they are consistently overconfident. We then focus on the calibration of STR models on the word rather than the character level. In particular, we demonstrate that for attention based decoders, calibration of individual character predictions increases word-level calibration error compared to an uncalibrated model. In addition, we apply existing calibration methodologies as well as new sequence-based extensions to numerous STR models, demonstrating reduced calibration error by up to a factor of nearly 7. Finally, we show consistently improved accuracy results by applying our proposed sequence calibration method as a preprocessing step to beam-search.
Sequence-to-Sequence Contrastive Learning for Text Recognition
Dec 20, 2020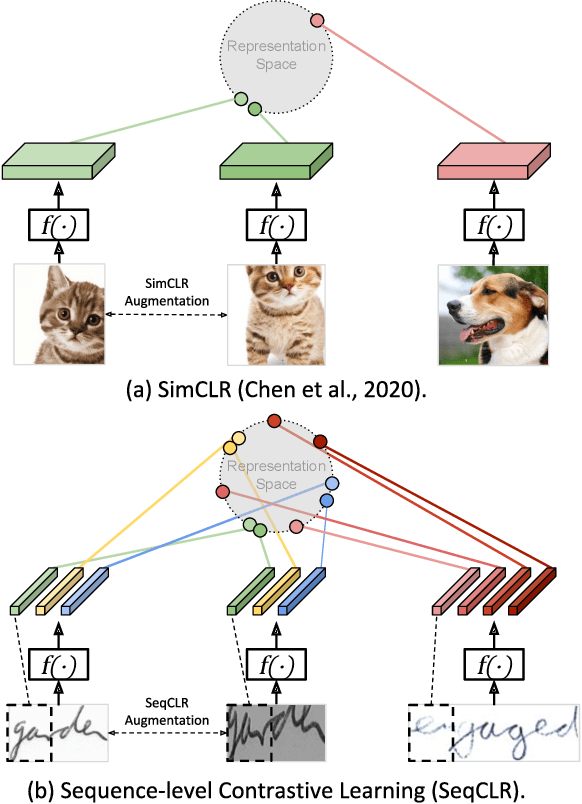
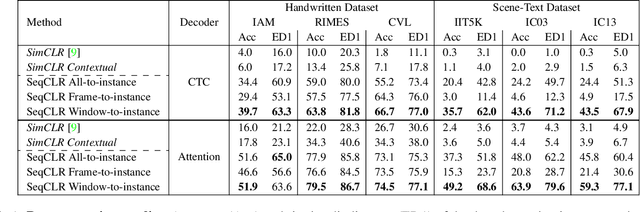
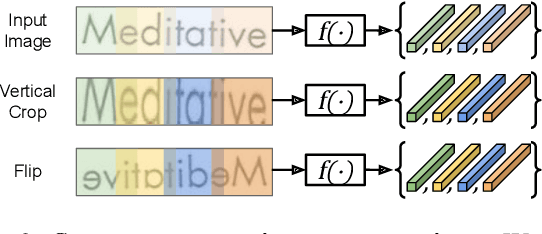
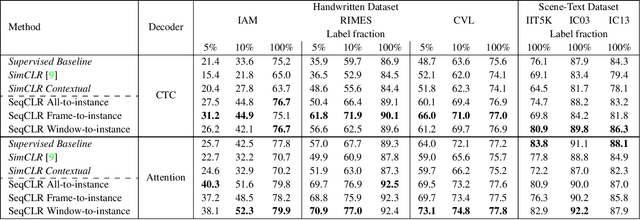
We propose a framework for sequence-to-sequence contrastive learning (SeqCLR) of visual representations, which we apply to text recognition. To account for the sequence-to-sequence structure, each feature map is divided into different instances over which the contrastive loss is computed. This operation enables us to contrast in a sub-word level, where from each image we extract several positive pairs and multiple negative examples. To yield effective visual representations for text recognition, we further suggest novel augmentation heuristics, different encoder architectures and custom projection heads. Experiments on handwritten text and on scene text show that when a text decoder is trained on the learned representations, our method outperforms non-sequential contrastive methods. In addition, when the amount of supervision is reduced, SeqCLR significantly improves performance compared with supervised training, and when fine-tuned with 100% of the labels, our method achieves state-of-the-art results on standard handwritten text recognition benchmarks.
SCATTER: Selective Context Attentional Scene Text Recognizer
Mar 25, 2020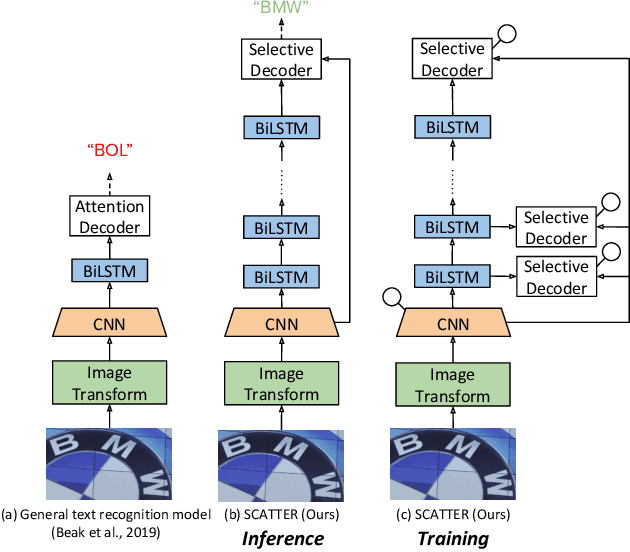
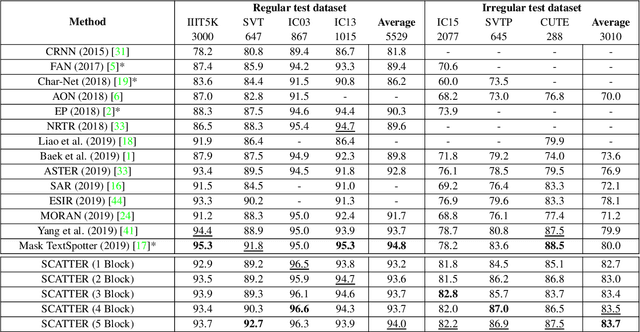
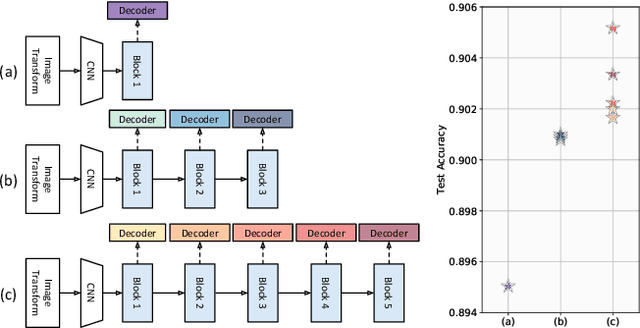
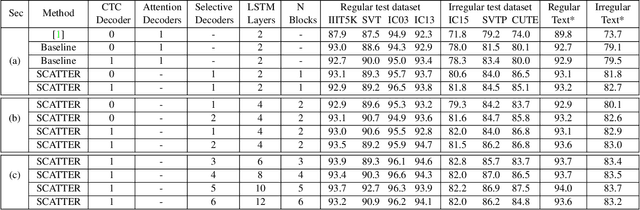
Scene Text Recognition (STR), the task of recognizing text against complex image backgrounds, is an active area of research. Current state-of-the-art (SOTA) methods still struggle to recognize text written in arbitrary shapes. In this paper, we introduce a novel architecture for STR, named Selective Context ATtentional Text Recognizer (SCATTER). SCATTER utilizes a stacked block architecture with intermediate supervision during training, that paves the way to successfully train a deep BiLSTM encoder, thus improving the encoding of contextual dependencies. Decoding is done using a two-step 1D attention mechanism. The first attention step re-weights visual features from a CNN backbone together with contextual features computed by a BiLSTM layer. The second attention step, similar to previous papers, treats the features as a sequence and attends to the intra-sequence relationships. Experiments show that the proposed approach surpasses SOTA performance on irregular text recognition benchmarks by 3.7\% on average.
Sparsity-Based Super Resolution for SEM Images
Aug 29, 2017

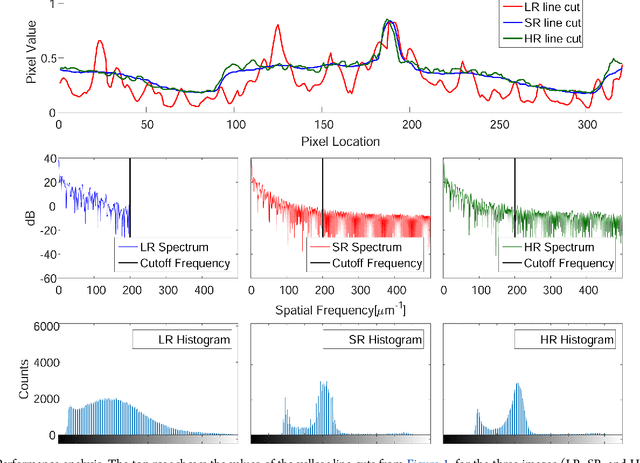
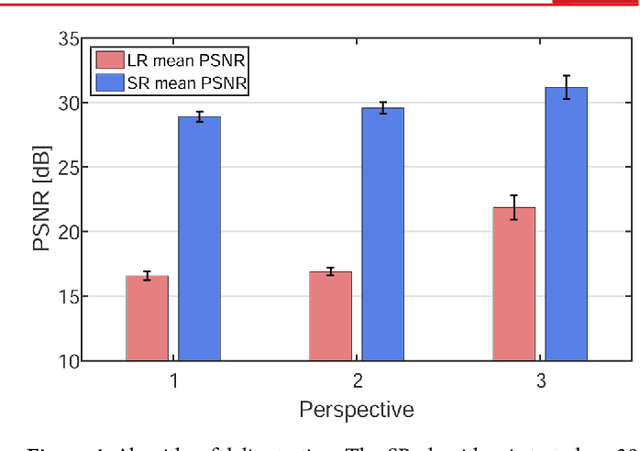
The scanning electron microscope (SEM) produces an image of a sample by scanning it with a focused beam of electrons. The electrons interact with the atoms in the sample, which emit secondary electrons that contain information about the surface topography and composition. The sample is scanned by the electron beam point by point, until an image of the surface is formed. Since its invention in 1942, SEMs have become paramount in the discovery and understanding of the nanometer world, and today it is extensively used for both research and in industry. In principle, SEMs can achieve resolution better than one nanometer. However, for many applications, working at sub-nanometer resolution implies an exceedingly large number of scanning points. For exactly this reason, the SEM diagnostics of microelectronic chips is performed either at high resolution (HR) over a small area or at low resolution (LR) while capturing a larger portion of the chip. Here, we employ sparse coding and dictionary learning to algorithmically enhance LR SEM images of microelectronic chips up to the level of the HR images acquired by slow SEM scans, while considerably reducing the noise. Our methodology consists of two steps: an offline stage of learning a joint dictionary from a sequence of LR and HR images of the same region in the chip, followed by a fast-online super-resolution step where the resolution of a new LR image is enhanced. We provide several examples with typical chips used in the microelectronics industry, as well as a statistical study on arbitrary images with characteristic structural features. Conceptually, our method works well when the images have similar characteristics. This work demonstrates that employing sparsity concepts can greatly improve the performance of SEM, thereby considerably increasing the scanning throughput without compromising on analysis quality and resolution.