 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder-Canopy Terrain Reconstruction in Dense Forests Using RGB Imaging and Neural 3D Reconstruction
Jan 30, 2026Mapping the terrain and understory hidden beneath dense forest canopies is of great interest for numerous applications such as search and rescue, trail mapping, forest inventory tasks, and more. Existing solutions rely on specialized sensors: either heavy, costly airborne LiDAR, or Airborne Optical Sectioning (AOS), which uses thermal synthetic aperture photography and is tailored for person detection. We introduce a novel approach for the reconstruction of canopy-free, photorealistic ground views using only conventional RGB images. Our solution is based on the celebrated Neural Radiance Fields (NeRF), a recent 3D reconstruction method. Additionally, we include specific image capture considerations, which dictate the needed illumination to successfully expose the scene beneath the canopy. To better cope with the poorly lit understory, we employ a low light loss. Finally, we propose two complementary approaches to remove occluding canopy elements by controlling per-ray integration procedure. To validate the value of our approach, we present two possible downstream tasks. For the task of search and rescue (SAR), we demonstrate that our method enables person detection which achieves promising results compared to thermal AOS (using only RGB images). Additionally, we show the potential of our approach for forest inventory tasks like tree counting. These results position our approach as a cost-effective, high-resolution alternative to specialized sensors for SAR, trail mapping, and forest-inventory tasks.
Can You Read Me Now? Content Aware Rectification using Angle Supervision
Aug 05, 2020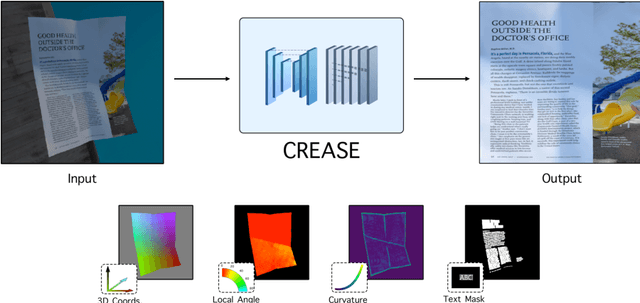

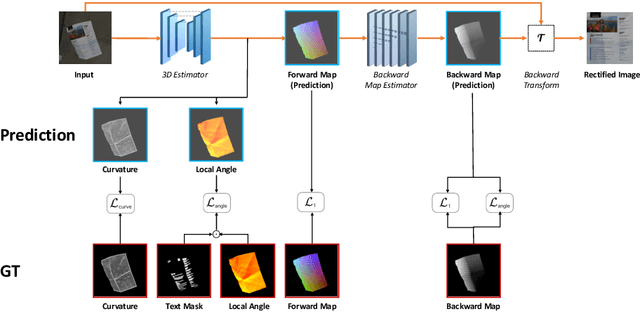

The ubiquity of smartphone cameras has led to more and more documents being captured by cameras rather than scanned. Unlike flatbed scanners, photographed documents are often folded and crumpled, resulting in large local variance in text structure. The problem of document rectification is fundamental to the Optical Character Recognition (OCR) process on documents, and its ability to overcome geometric distortions significantly affects recognition accuracy. Despite the great progress in recent OCR systems, most still rely on a pre-process that ensures the text lines are straight and axis aligned. Recent works have tackled the problem of rectifying document images taken in-the-wild using various supervision signals and alignment means. However, they focused on global features that can be extracted from the document's boundaries, ignoring various signals that could be obtained from the document's content. We present CREASE: Content Aware Rectification using Angle Supervision, the first learned method for document rectification that relies on the document's content, the location of the words and specifically their orientation, as hints to assist in the rectification process. We utilize a novel pixel-wise angle regression approach and a curvature estimation side-task for optimizing our rectification model. Our method surpasses previous approaches in terms of OCR accuracy, geometric error and visual similarity.
SCATTER: Selective Context Attentional Scene Text Recognizer
Mar 25, 2020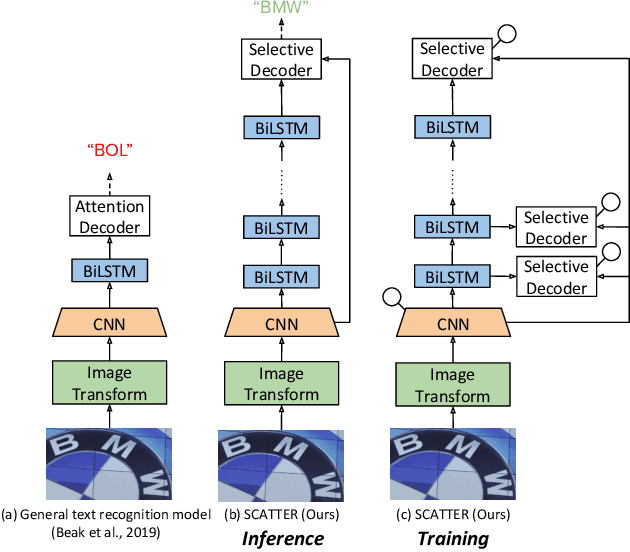
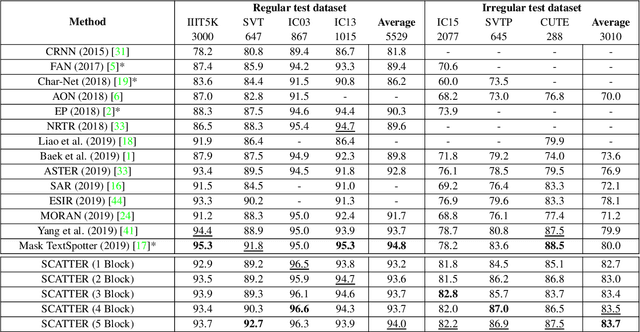
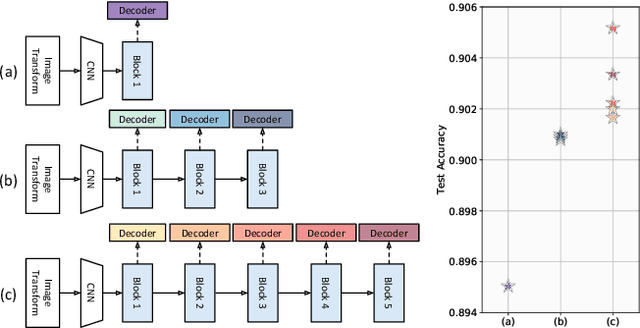
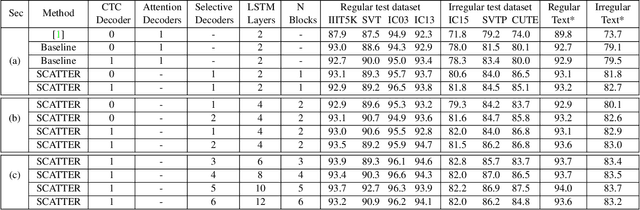
Scene Text Recognition (STR), the task of recognizing text against complex image backgrounds, is an active area of research. Current state-of-the-art (SOTA) methods still struggle to recognize text written in arbitrary shapes. In this paper, we introduce a novel architecture for STR, named Selective Context ATtentional Text Recognizer (SCATTER). SCATTER utilizes a stacked block architecture with intermediate supervision during training, that paves the way to successfully train a deep BiLSTM encoder, thus improving the encoding of contextual dependencies. Decoding is done using a two-step 1D attention mechanism. The first attention step re-weights visual features from a CNN backbone together with contextual features computed by a BiLSTM layer. The second attention step, similar to previous papers, treats the features as a sequence and attends to the intra-sequence relationships. Experiments show that the proposed approach surpasses SOTA performance on irregular text recognition benchmarks by 3.7\% on average.
ScrabbleGAN: Semi-Supervised Varying Length Handwritten Text Generation
Mar 23, 2020
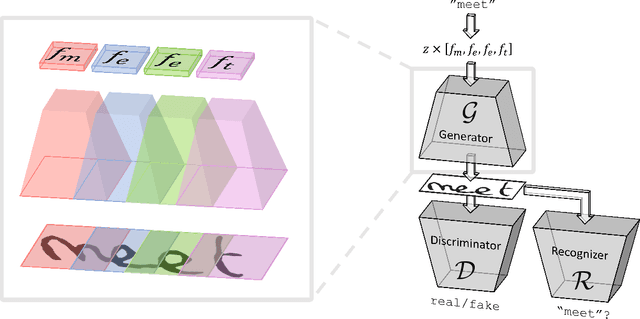
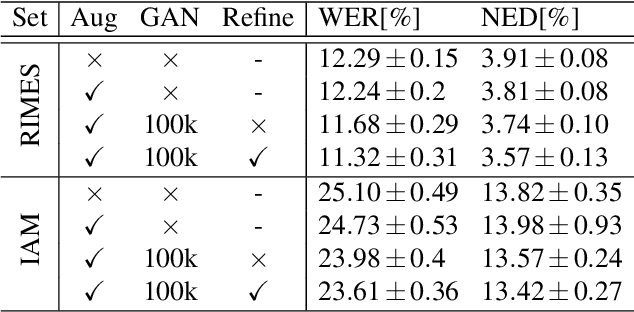

Optical character recognition (OCR) systems performance have improved significantly in the deep learning era. This is especially true for handwritten text recognition (HTR), where each author has a unique style, unlike printed text, where the variation is smaller by design. That said, deep learning based HTR is limited, as in every other task, by the number of training examples. Gathering data is a challenging and costly task, and even more so, the labeling task that follows, of which we focus here. One possible approach to reduce the burden of data annotation is semi-supervised learning. Semi supervised methods use, in addition to labeled data, some unlabeled samples to improve performance, compared to fully supervised ones. Consequently, such methods may adapt to unseen images during test time. We present ScrabbleGAN, a semi-supervised approach to synthesize handwritten text images that are versatile both in style and lexicon. ScrabbleGAN relies on a novel generative model which can generate images of words with an arbitrary length. We show how to operate our approach in a semi-supervised manner, enjoying the aforementioned benefits such as performance boost over state of the art supervised HTR. Furthermore, our generator can manipulate the resulting text style. This allows us to change, for instance, whether the text is cursive, or how thin is the pen stroke.
Shape retrieval of non-rigid 3d human models
Mar 01, 2020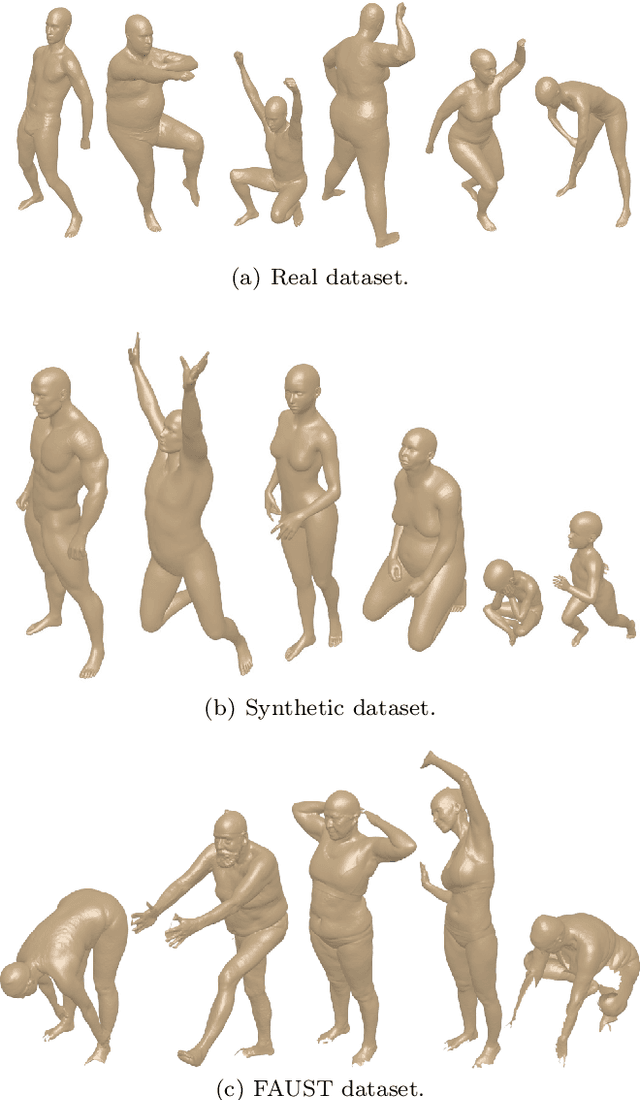
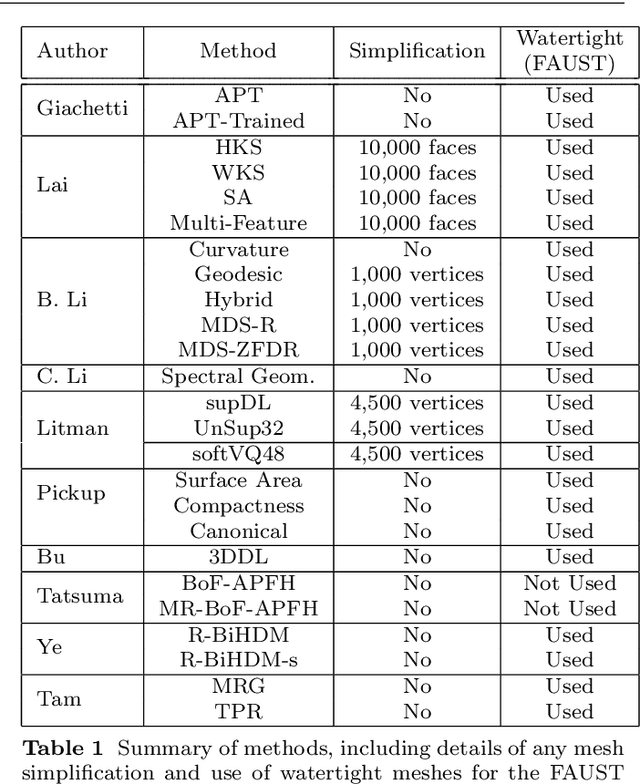
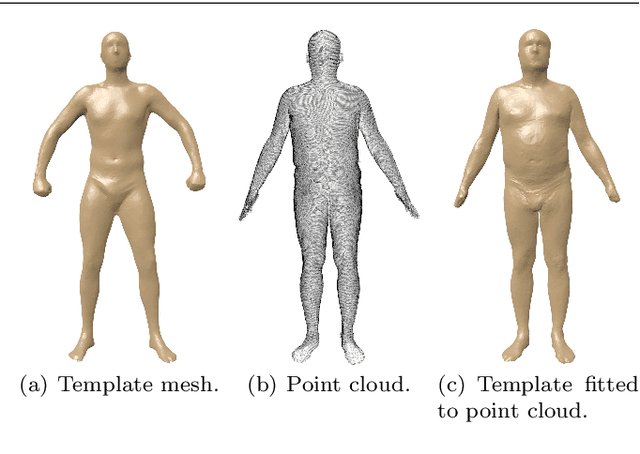
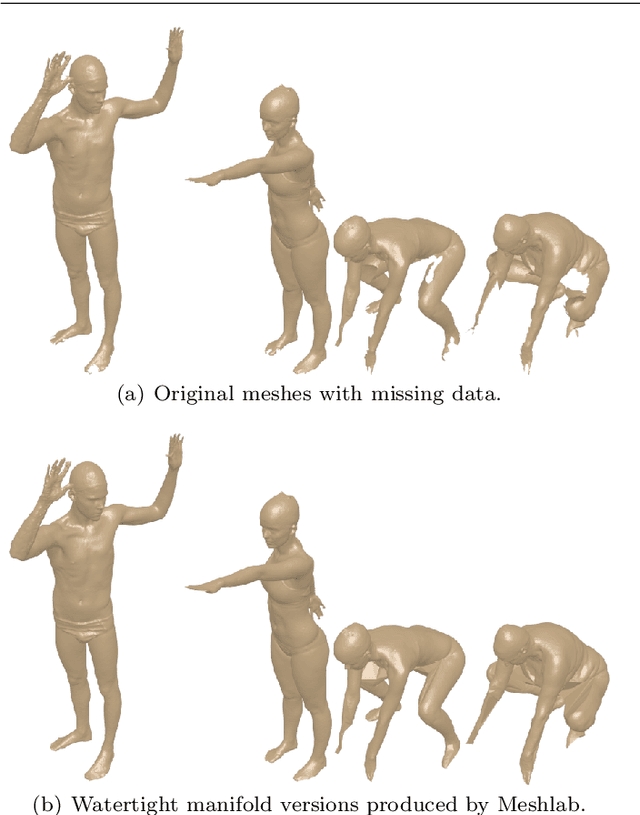
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
Latent RANSAC
Jun 03, 2018
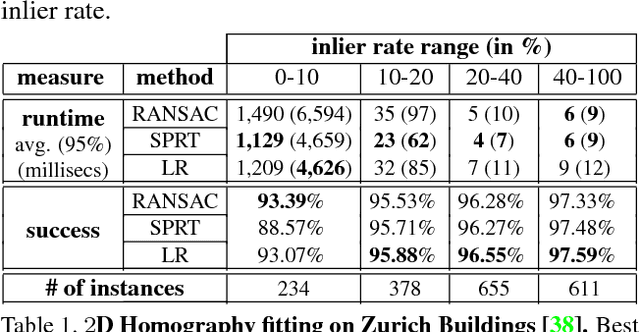
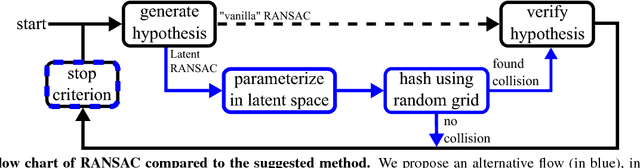
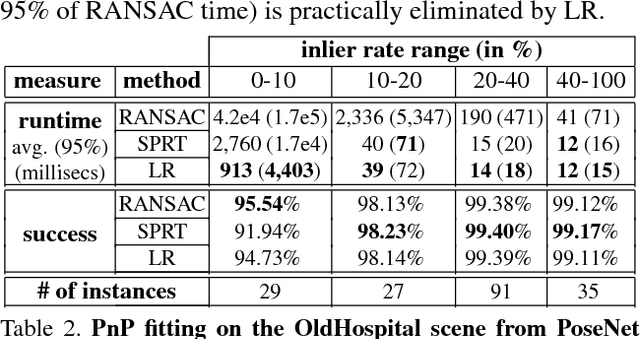
We present a method that can evaluate a RANSAC hypothesis in constant time, i.e. independent of the size of the data. A key observation here is that correct hypotheses are tightly clustered together in the latent parameter domain. In a manner similar to the generalized Hough transform we seek to find this cluster, only that we need as few as two votes for a successful detection. Rapidly locating such pairs of similar hypotheses is made possible by adapting the recent "Random Grids" range-search technique. We only perform the usual (costly) hypothesis verification stage upon the discovery of a close pair of hypotheses. We show that this event rarely happens for incorrect hypotheses, enabling a significant speedup of the RANSAC pipeline. The suggested approach is applied and tested on three robust estimation problems: camera localization, 3D rigid alignment and 2D-homography estimation. We perform rigorous testing on both synthetic and real datasets, demonstrating an improvement in efficiency without a compromise in accuracy. Furthermore, we achieve state-of-the-art 3D alignment results on the challenging "Redwood" loop-closure challenge.
Product Manifold Filter: Non-Rigid Shape Correspondence via Kernel Density Estimation in the Product Space
Apr 07, 2017
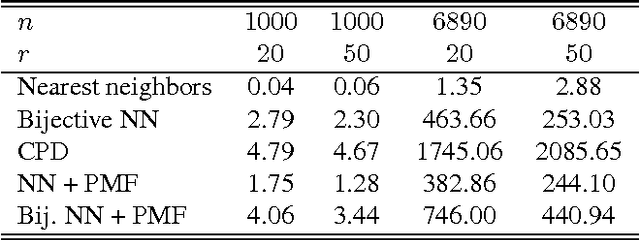

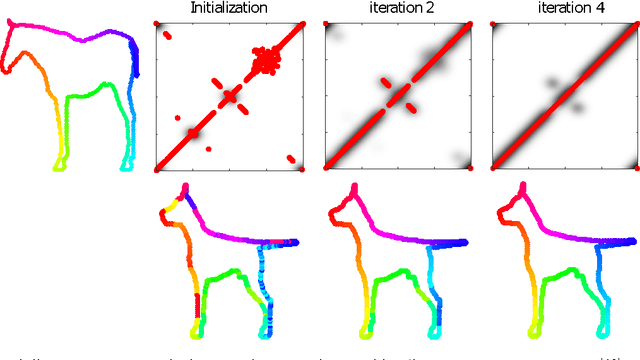
Many algorithms for the computation of correspondences between deformable shapes rely on some variant of nearest neighbor matching in a descriptor space. Such are, for example, various point-wise correspondence recovery algorithms used as a post-processing stage in the functional correspondence framework. Such frequently used techniques implicitly make restrictive assumptions (e.g., near-isometry) on the considered shapes and in practice suffer from lack of accuracy and result in poor surjectivity. We propose an alternative recovery technique capable of guaranteeing a bijective correspondence and producing significantly higher accuracy and smoothness. Unlike other methods our approach does not depend on the assumption that the analyzed shapes are isometric. We derive the proposed method from the statistical framework of kernel density estimation and demonstrate its performance on several challenging deformable 3D shape matching datasets.
Bayesian Inference of Bijective Non-Rigid Shape Correspondence
Jul 12, 2016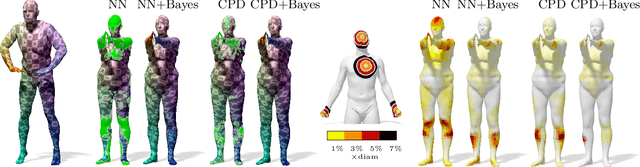
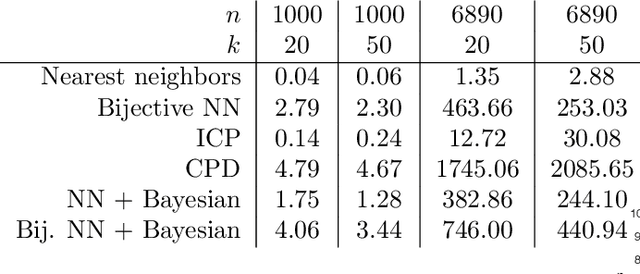
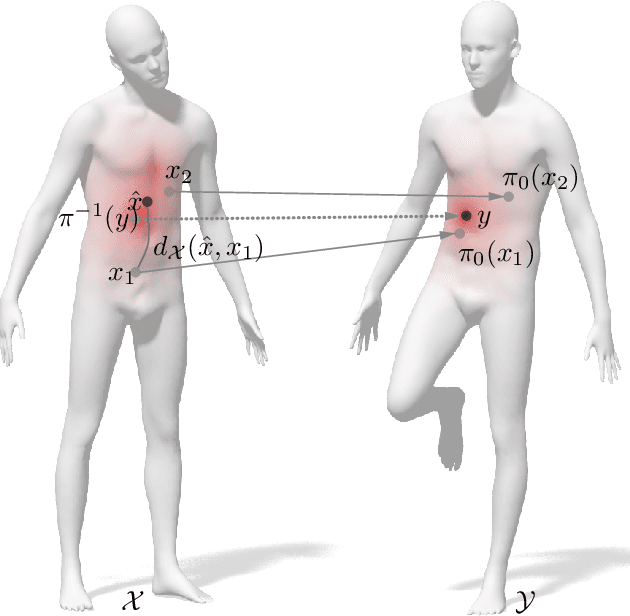
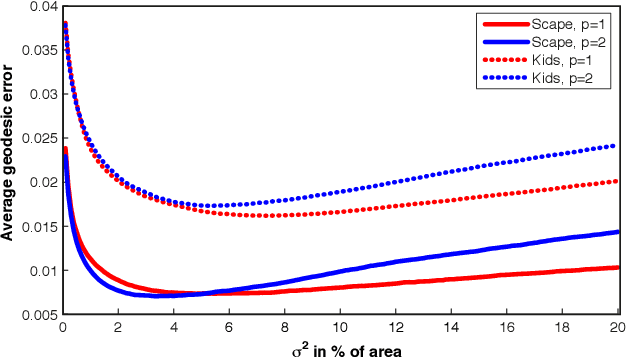
Many algorithms for the computation of correspondences between deformable shapes rely on some variant of nearest neighbor matching in a descriptor space. Such are, for example, various point-wise correspondence recovery algorithms used as a postprocessing stage in the functional correspondence framework. In this paper, we show that such frequently used techniques in practice suffer from lack of accuracy and result in poor surjectivity. We propose an alternative recovery technique guaranteeing a bijective correspondence and producing significantly higher accuracy. We derive the proposed method from a statistical framework of Bayesian inference and demonstrate its performance on several challenging deformable 3D shape matching datasets.
Diffusion-geometric maximally stable component detection in deformable shapes
Dec 17, 2010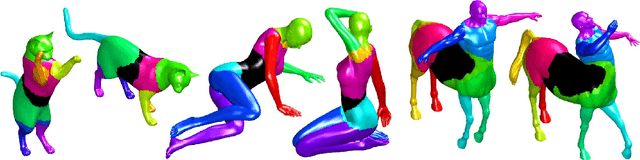
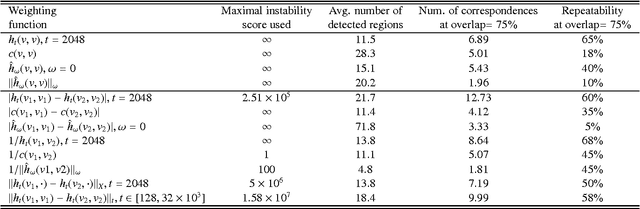
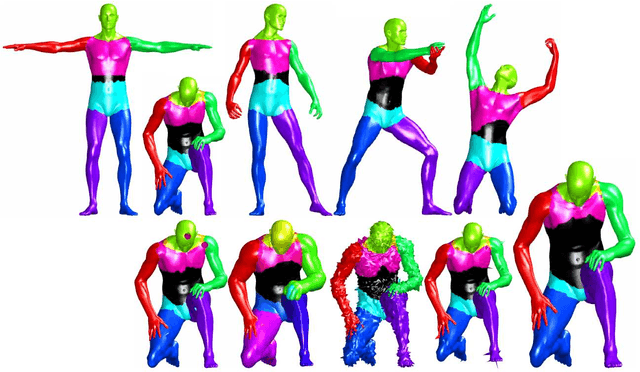
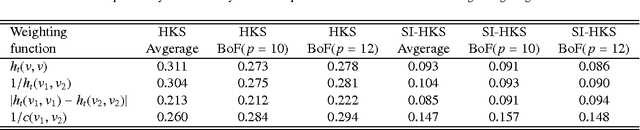
Maximally stable component detection is a very popular method for feature analysis in images, mainly due to its low computation cost and high repeatability. With the recent advance of feature-based methods in geometric shape analysis, there is significant interest in finding analogous approaches in the 3D world. In this paper, we formulate a diffusion-geometric framework for stable component detection in non-rigid 3D shapes, which can be used for geometric feature detection and description. A quantitative evaluation of our method on the SHREC'10 feature detection benchmark shows its potential as a source of high-quality features.