 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgekdehumor at semeval-2020 task 7: a neural network model for detecting funniness in dataset humicroedit
May 11, 2021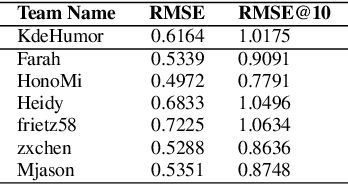


This paper describes our contribution to SemEval-2020 Task 7: Assessing Humor in Edited News Headlines. Here we present a method based on a deep neural network. In recent years, quite some attention has been devoted to humor production and perception. Our team KdeHumor employs recurrent neural network models including Bi-Directional LSTMs (BiLSTMs). Moreover, we utilize the state-of-the-art pre-trained sentence embedding techniques. We analyze the performance of our method and demonstrate the contribution of each component of our architecture.
Integrating extracted information from bert and multiple embedding methods with the deep neural network for humour detection
May 11, 2021

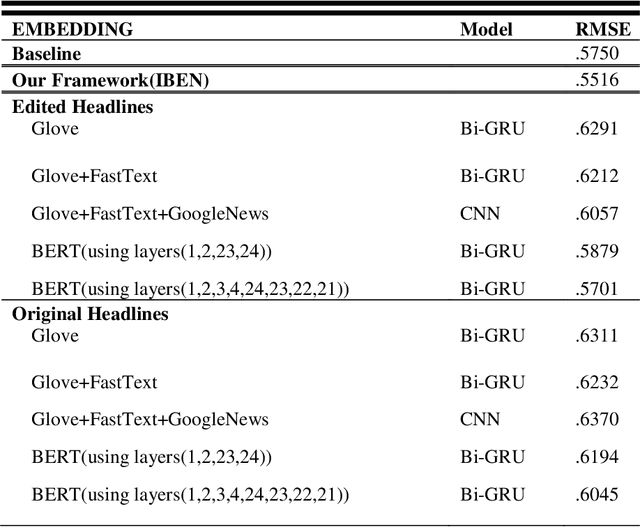
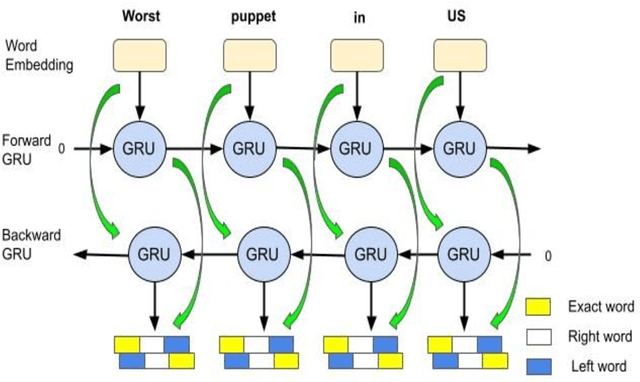
Humour detection from sentences has been an interesting and challenging task in the last few years. In attempts to highlight humour detection, most research was conducted using traditional approaches of embedding, e.g., Word2Vec or Glove. Recently BERT sentence embedding has also been used for this task. In this paper, we propose a framework for humour detection in short texts taken from news headlines. Our proposed framework (IBEN) attempts to extract information from written text via the use of different layers of BERT. After several trials, weights were assigned to different layers of the BERT model. The extracted information was then sent to a Bi-GRU neural network as an embedding matrix. We utilized the properties of some external embedding models. A multi-kernel convolution in our neural network was also employed to extract higher-level sentence representations. This framework performed very well on the task of humour detection.
Shape retrieval of non-rigid 3d human models
Mar 01, 2020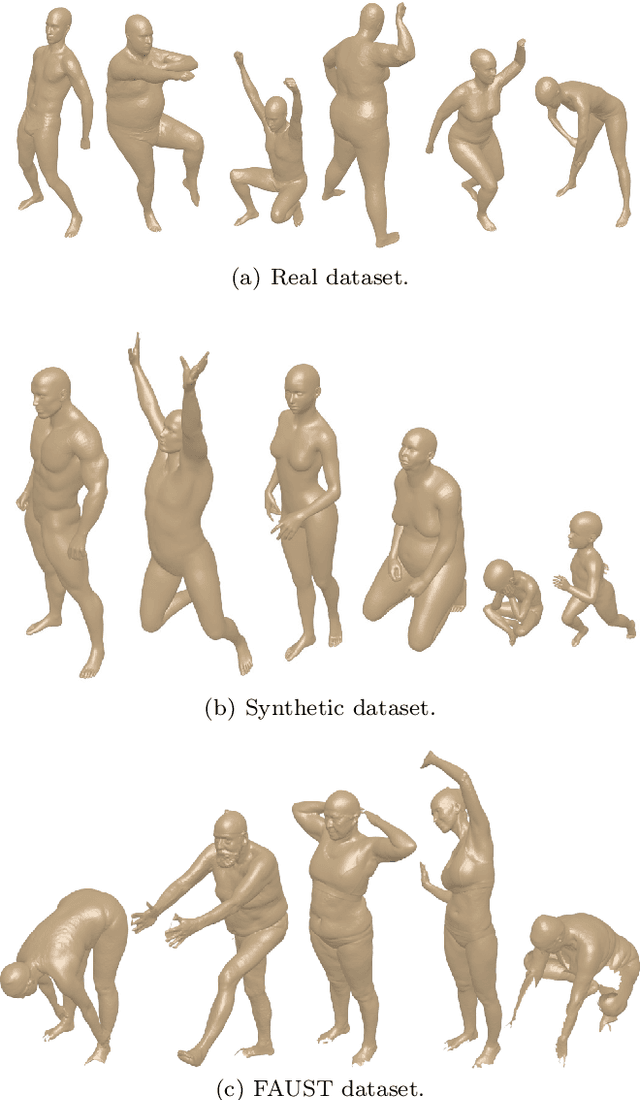
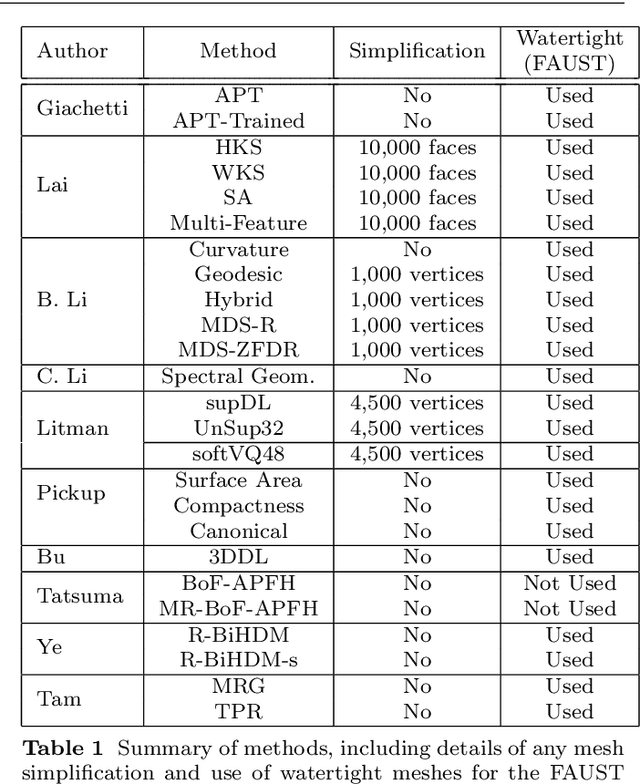
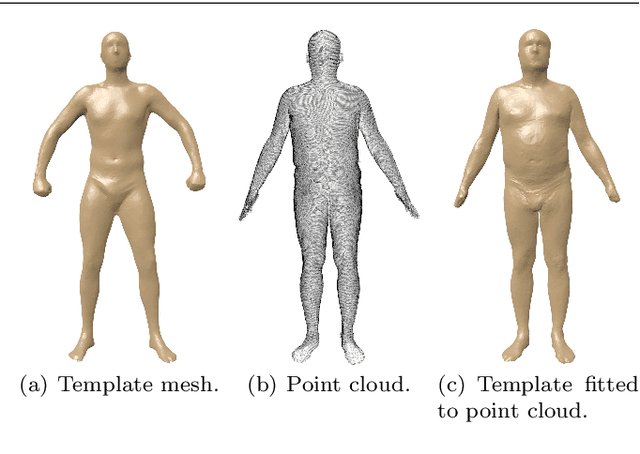
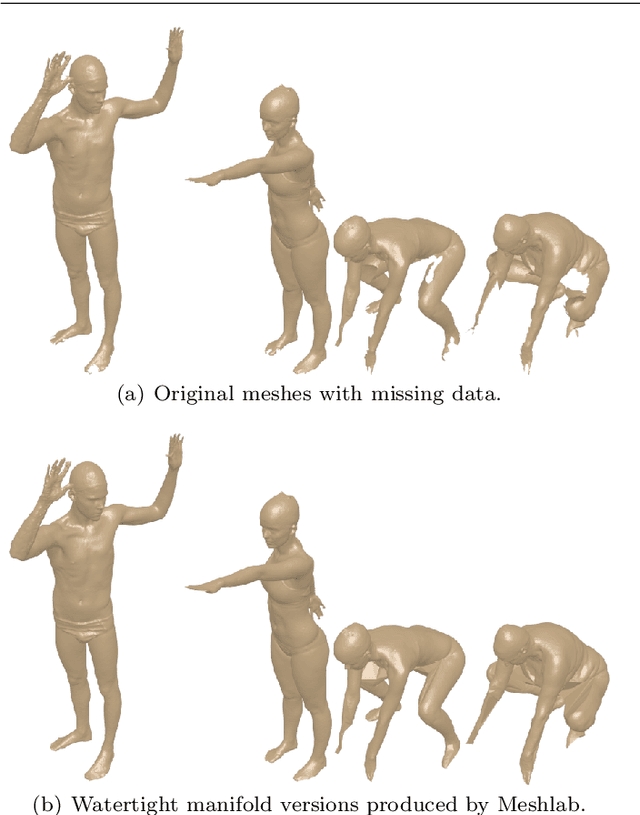
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
An Efficient Metric of Automatic Weight Generation for Properties in Instance Matching Technique
Feb 12, 2015
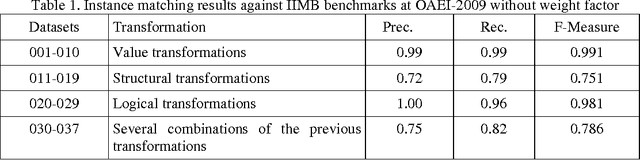
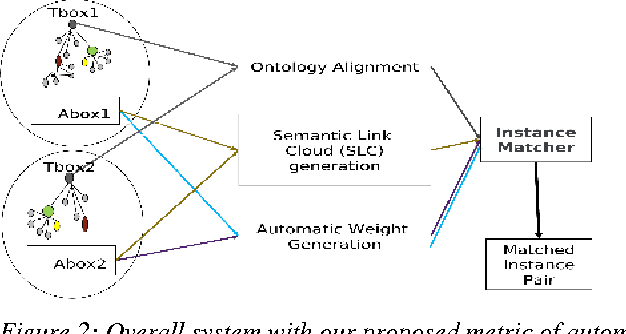
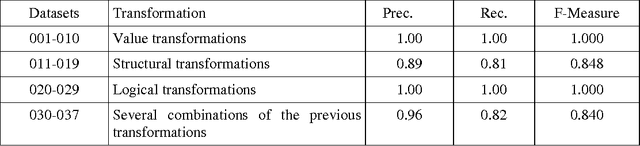
The proliferation of heterogeneous data sources of semantic knowledge base intensifies the need of an automatic instance matching technique. However, the efficiency of instance matching is often influenced by the weight of a property associated to instances. Automatic weight generation is a non-trivial, however an important task in instance matching technique. Therefore, identifying an appropriate metric for generating weight for a property automatically is nevertheless a formidable task. In this paper, we investigate an approach of generating weights automatically by considering hypotheses: (1) the weight of a property is directly proportional to the ratio of the number of its distinct values to the number of instances contain the property, and (2) the weight is also proportional to the ratio of the number of distinct values of a property to the number of instances in a training dataset. The basic intuition behind the use of our approach is the classical theory of information content that infrequent words are more informative than frequent ones. Our mathematical model derives a metric for generating property weights automatically, which is applied in instance matching system to produce re-conciliated instances efficiently. Our experiments and evaluations show the effectiveness of our proposed metric of automatic weight generation for properties in an instance matching technique.
* 17 pages, 5 figures, 3 tables, pp. 1-17, publication year 2015, journal publication, vol. 6 number 1