 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActMVS: Active Scene Reconstruction with Monocular Multi-View Stereo
May 31, 2026Active scene reconstruction enables robots/UAVs to autonomously plan trajectories and reconstruct environments without costly manual data acquisition. Unlike passive methods, active reconstruction requires real-time construction of high-confidence occupancy maps for collision-free navigation. Existing approaches rely on depth sensors for occupancy map updates, increasing platform cost and weight. To advance spatial intelligence, we aim for a vision-only monocular solution. However, current monocular scene reconstruction methods operate offline and fail to deliver globally consistent dense depth at the frame rates required for robots/UAVs navigation. To bridge this gap, we introduce ActMVS, the first framework for monocular active reconstruction. Our framework integrates a view factor graph construction for informed Multi-View Stereo depth prediction, along with a global depth optimization, to enable the online generation of high-quality, globally consistent dense depth maps. This enables monocular robots/UAVs to maintain reliable occupancy maps for safe trajectory planning during reconstruction. Experiments on Replica datasets demonstrate performance competitive with RGB-D methods. Our code and data are available at https://github.com/TrickyGo/ActMVS.
Machine Learning-Assisted High-Dimensional Matrix Estimation
Mar 30, 2026Efficient estimation of high-dimensional matrices-including covariance and precision matrices-is a cornerstone of modern multivariate statistics. Most existing studies have focused primarily on the theoretical properties of the estimators (e.g., consistency and sparsity), while largely overlooking the computational challenges inherent in high-dimensional settings. Motivated by recent advances in learning-based optimization method-which integrate data-driven structures with classical optimization algorithms-we explore high-dimensional matrix estimation assisted by machine learning. Specifically, for the optimization problem of high-dimensional matrix estimation, we first present a solution procedure based on the Linearized Alternating Direction Method of Multipliers (LADMM). We then introduce learnable parameters and model the proximal operators in the iterative scheme with neural networks, thereby improving estimation accuracy and accelerating convergence. Theoretically, we first prove the convergence of LADMM, and then establish the convergence, convergence rate, and monotonicity of its reparameterized counterpart; importantly, we show that the reparameterized LADMM enjoys a faster convergence rate. Notably, the proposed reparameterization theory and methodology are applicable to the estimation of both high-dimensional covariance and precision matrices. We validate the effectiveness of our method by comparing it with several classical optimization algorithms across different structures and dimensions of high-dimensional matrices.
Sharper Generalization Bounds for Transformer
Mar 23, 2026This paper studies generalization error bounds for Transformer models. Based on the offset Rademacher complexity, we derive sharper generalization bounds for different Transformer architectures, including single-layer single-head, single-layer multi-head, and multi-layer Transformers. We first express the excess risk of Transformers in terms of the offset Rademacher complexity. By exploiting its connection with the empirical covering numbers of the corresponding hypothesis spaces, we obtain excess risk bounds that achieve optimal convergence rates up to constant factors. We then derive refined excess risk bounds by upper bounding the covering numbers of Transformer hypothesis spaces using matrix ranks and matrix norms, leading to precise, architecture-dependent generalization bounds. Finally, we relax the boundedness assumption on feature mappings and extend our theoretical results to settings with unbounded (sub-Gaussian) features and heavy-tailed distributions.
Beyond Patches: Global-aware Autoregressive Model for Multimodal Few-Shot Font Generation
Jan 04, 2026Manual font design is an intricate process that transforms a stylistic visual concept into a coherent glyph set. This challenge persists in automated Few-shot Font Generation (FFG), where models often struggle to preserve both the structural integrity and stylistic fidelity from limited references. While autoregressive (AR) models have demonstrated impressive generative capabilities, their application to FFG is constrained by conventional patch-level tokenization, which neglects global dependencies crucial for coherent font synthesis. Moreover, existing FFG methods remain within the image-to-image paradigm, relying solely on visual references and overlooking the role of language in conveying stylistic intent during font design. To address these limitations, we propose GAR-Font, a novel AR framework for multimodal few-shot font generation. GAR-Font introduces a global-aware tokenizer that effectively captures both local structures and global stylistic patterns, a multimodal style encoder offering flexible style control through a lightweight language-style adapter without requiring intensive multimodal pretraining, and a post-refinement pipeline that further enhances structural fidelity and style coherence. Extensive experiments show that GAR-Font outperforms existing FFG methods, excelling in maintaining global style faithfulness and achieving higher-quality results with textual stylistic guidance.
UTDesign: A Unified Framework for Stylized Text Editing and Generation in Graphic Design Images
Dec 23, 2025AI-assisted graphic design has emerged as a powerful tool for automating the creation and editing of design elements such as posters, banners, and advertisements. While diffusion-based text-to-image models have demonstrated strong capabilities in visual content generation, their text rendering performance, particularly for small-scale typography and non-Latin scripts, remains limited. In this paper, we propose UTDesign, a unified framework for high-precision stylized text editing and conditional text generation in design images, supporting both English and Chinese scripts. Our framework introduces a novel DiT-based text style transfer model trained from scratch on a synthetic dataset, capable of generating transparent RGBA text foregrounds that preserve the style of reference glyphs. We further extend this model into a conditional text generation framework by training a multi-modal condition encoder on a curated dataset with detailed text annotations, enabling accurate, style-consistent text synthesis conditioned on background images, prompts, and layout specifications. Finally, we integrate our approach into a fully automated text-to-design (T2D) pipeline by incorporating pre-trained text-to-image (T2I) models and an MLLM-based layout planner. Extensive experiments demonstrate that UTDesign achieves state-of-the-art performance among open-source methods in terms of stylistic consistency and text accuracy, and also exhibits unique advantages compared to proprietary commercial approaches. Code and data for this paper are available at https://github.com/ZYM-PKU/UTDesign.
IndoorUAV: Benchmarking Vision-Language UAV Navigation in Continuous Indoor Environments
Dec 22, 2025Vision-Language Navigation (VLN) enables agents to navigate in complex environments by following natural language instructions grounded in visual observations. Although most existing work has focused on ground-based robots or outdoor Unmanned Aerial Vehicles (UAVs), indoor UAV-based VLN remains underexplored, despite its relevance to real-world applications such as inspection, delivery, and search-and-rescue in confined spaces. To bridge this gap, we introduce \textbf{IndoorUAV}, a novel benchmark and method specifically tailored for VLN with indoor UAVs. We begin by curating over 1,000 diverse and structurally rich 3D indoor scenes from the Habitat simulator. Within these environments, we simulate realistic UAV flight dynamics to collect diverse 3D navigation trajectories manually, further enriched through data augmentation techniques. Furthermore, we design an automated annotation pipeline to generate natural language instructions of varying granularity for each trajectory. This process yields over 16,000 high-quality trajectories, comprising the \textbf{IndoorUAV-VLN} subset, which focuses on long-horizon VLN. To support short-horizon planning, we segment long trajectories into sub-trajectories by selecting semantically salient keyframes and regenerating concise instructions, forming the \textbf{IndoorUAV-VLA} subset. Finally, we introduce \textbf{IndoorUAV-Agent}, a novel navigation model designed for our benchmark, leveraging task decomposition and multimodal reasoning. We hope IndoorUAV serves as a valuable resource to advance research on vision-language embodied AI in the indoor aerial navigation domain.
MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning
Jun 12, 2025In this paper, we introduce knowledge image generation as a new task, alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation Benchmark (MMMG) to probe the reasoning capability of image generation models. Knowledge images have been central to human civilization and to the mechanisms of human learning--a fact underscored by dual-coding theory and the picture-superiority effect. Generating such images is challenging, demanding multimodal reasoning that fuses world knowledge with pixel-level grounding into clear explanatory visuals. To enable comprehensive evaluation, MMMG offers 4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines, 6 educational levels, and diverse knowledge formats such as charts, diagrams, and mind maps. To eliminate confounding complexity during evaluation, we adopt a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a target image's core entities and their dependencies. We further introduce MMMG-Score to evaluate generated knowledge images. This metric combines factual fidelity, measured by graph-edit distance between KGs, with visual clarity assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image generation models expose serious reasoning deficits--low entity fidelity, weak relations, and clutter--with GPT-4o achieving an MMMG-Score of only 50.20, underscoring the benchmark's difficulty. To spur further progress, we release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that combines a reasoning LLM with diffusion models and is trained on 16,000 curated knowledge image-prompt pairs.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


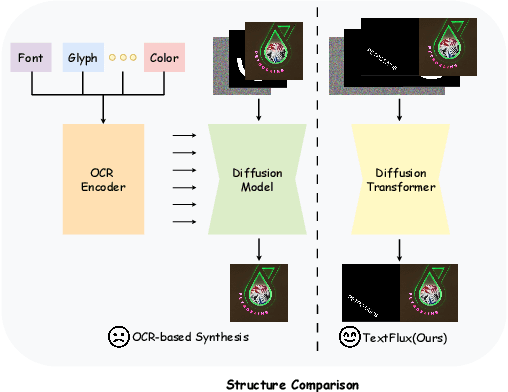
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Creating Your Editable 3D Photorealistic Avatar with Tetrahedron-constrained Gaussian Splatting
Apr 29, 2025



Personalized 3D avatar editing holds significant promise due to its user-friendliness and availability to applications such as AR/VR and virtual try-ons. Previous studies have explored the feasibility of 3D editing, but often struggle to generate visually pleasing results, possibly due to the unstable representation learning under mixed optimization of geometry and texture in complicated reconstructed scenarios. In this paper, we aim to provide an accessible solution for ordinary users to create their editable 3D avatars with precise region localization, geometric adaptability, and photorealistic renderings. To tackle this challenge, we introduce a meticulously designed framework that decouples the editing process into local spatial adaptation and realistic appearance learning, utilizing a hybrid Tetrahedron-constrained Gaussian Splatting (TetGS) as the underlying representation. TetGS combines the controllable explicit structure of tetrahedral grids with the high-precision rendering capabilities of 3D Gaussian Splatting and is optimized in a progressive manner comprising three stages: 3D avatar instantiation from real-world monocular videos to provide accurate priors for TetGS initialization; localized spatial adaptation with explicitly partitioned tetrahedrons to guide the redistribution of Gaussian kernels; and geometry-based appearance generation with a coarse-to-fine activation strategy. Both qualitative and quantitative experiments demonstrate the effectiveness and superiority of our approach in generating photorealistic 3D editable avatars.
CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Mar 09, 2025
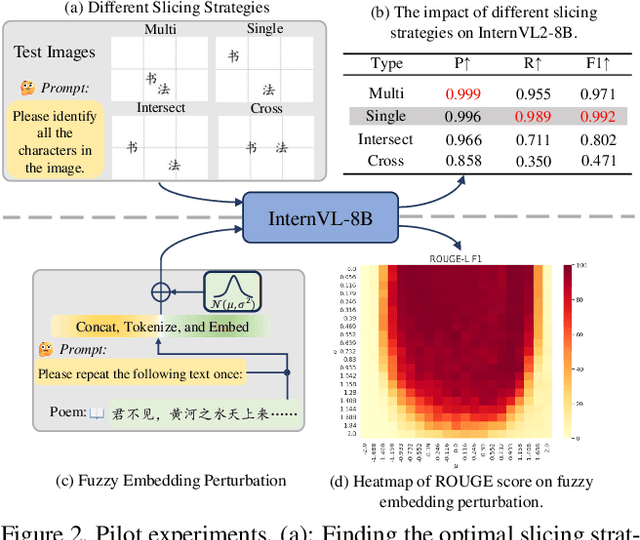
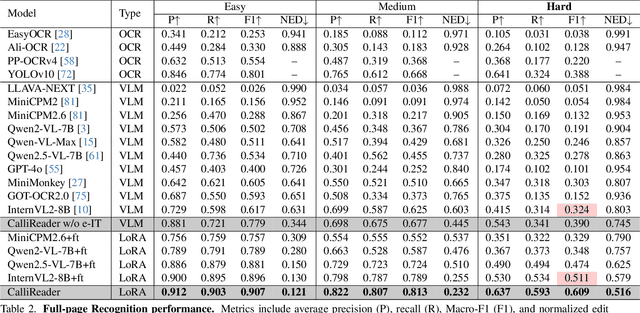
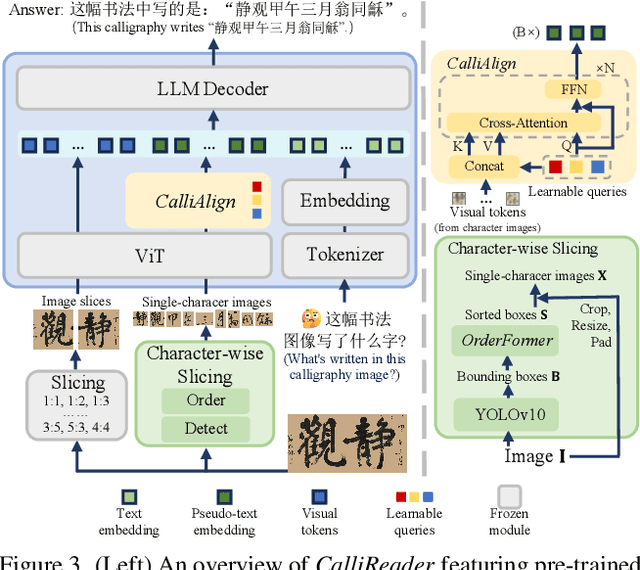
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader's \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader's efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.