 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Paper and Code

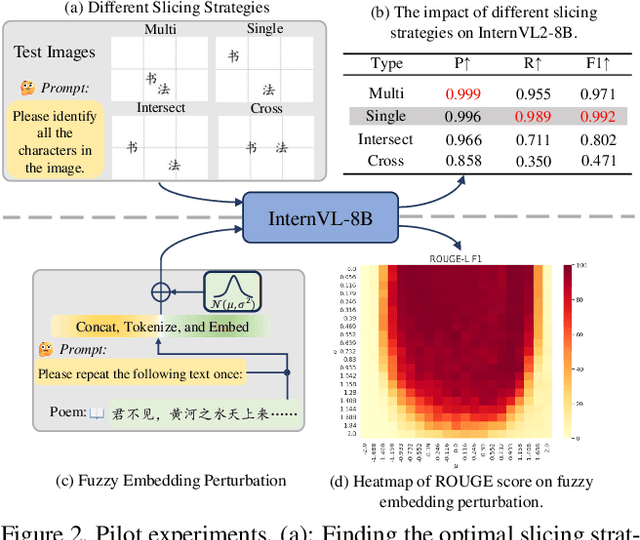
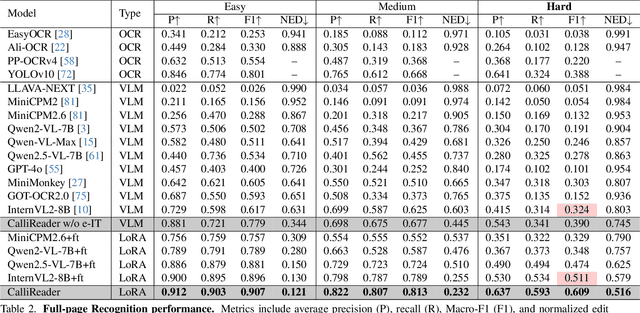
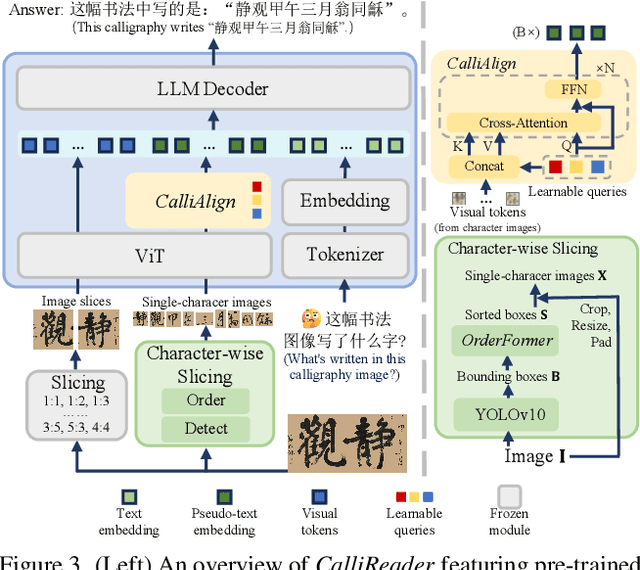
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader's \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader's efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.