 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving VQA Reliability: A Dual-Assessment Approach with Self-Reflection and Cross-Model Verification
Dec 16, 2025Vision-language models (VLMs) have demonstrated significant potential in Visual Question Answering (VQA). However, the susceptibility of VLMs to hallucinations can lead to overconfident yet incorrect answers, severely undermining answer reliability. To address this, we propose Dual-Assessment for VLM Reliability (DAVR), a novel framework that integrates Self-Reflection and Cross-Model Verification for comprehensive uncertainty estimation. The DAVR framework features a dual-pathway architecture: one pathway leverages dual selector modules to assess response reliability by fusing VLM latent features with QA embeddings, while the other deploys external reference models for factual cross-checking to mitigate hallucinations. Evaluated in the Reliable VQA Challenge at ICCV-CLVL 2025, DAVR achieves a leading $Φ_{100}$ score of 39.64 and a 100-AUC of 97.22, securing first place and demonstrating its effectiveness in enhancing the trustworthiness of VLM responses.
Diving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Sep 17, 2025
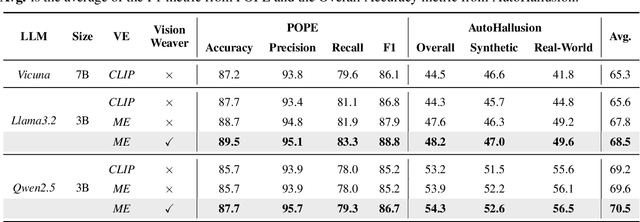
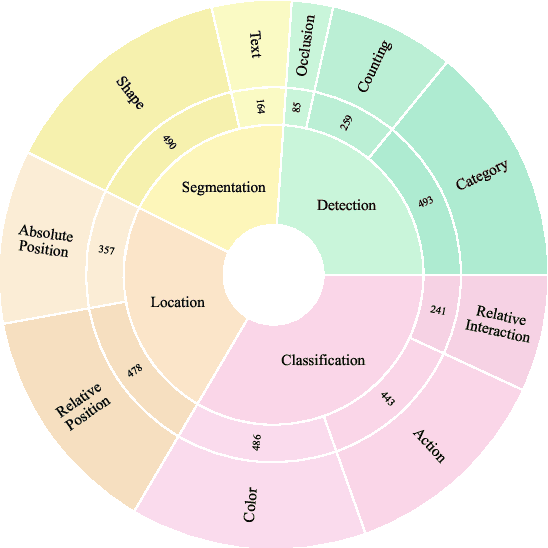
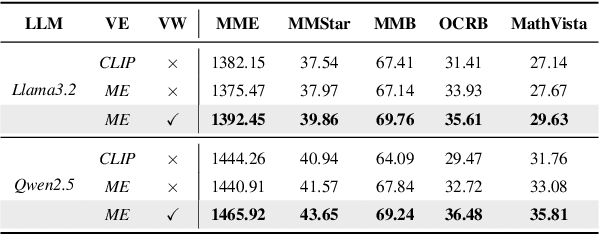
Object hallucination in Large Vision-Language Models (LVLMs) significantly impedes their real-world applicability. As the primary component for accurately interpreting visual information, the choice of visual encoder is pivotal. We hypothesize that the diverse training paradigms employed by different visual encoders instill them with distinct inductive biases, which leads to their diverse hallucination performances. Existing benchmarks typically focus on coarse-grained hallucination detection and fail to capture the diverse hallucinations elaborated in our hypothesis. To systematically analyze these effects, we introduce VHBench-10, a comprehensive benchmark with approximately 10,000 samples for evaluating LVLMs across ten fine-grained hallucination categories. Our evaluations confirm encoders exhibit unique hallucination characteristics. Building on these insights and the suboptimality of simple feature fusion, we propose VisionWeaver, a novel Context-Aware Routing Network. It employs global visual features to generate routing signals, dynamically aggregating visual features from multiple specialized experts. Comprehensive experiments confirm the effectiveness of VisionWeaver in significantly reducing hallucinations and improving overall model performance.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


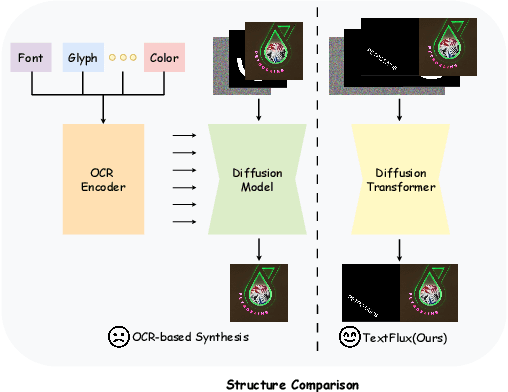
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
MX-Font++: Mixture of Heterogeneous Aggregation Experts for Few-shot Font Generation
Mar 04, 2025Few-shot Font Generation (FFG) aims to create new font libraries using limited reference glyphs, with crucial applications in digital accessibility and equity for low-resource languages, especially in multilingual artificial intelligence systems. Although existing methods have shown promising performance, transitioning to unseen characters in low-resource languages remains a significant challenge, especially when font glyphs vary considerably across training sets. MX-Font considers the content of a character from the perspective of a local component, employing a Mixture of Experts (MoE) approach to adaptively extract the component for better transition. However, the lack of a robust feature extractor prevents them from adequately decoupling content and style, leading to sub-optimal generation results. To alleviate these problems, we propose Heterogeneous Aggregation Experts (HAE), a powerful feature extraction expert that helps decouple content and style downstream from being able to aggregate information in channel and spatial dimensions. Additionally, we propose a novel content-style homogeneity loss to enhance the untangling. Extensive experiments on several datasets demonstrate that our MX-Font++ yields superior visual results in FFG and effectively outperforms state-of-the-art methods. Code and data are available at https://github.com/stephensun11/MXFontpp.
Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and Frequency Domain Information
May 31, 2021
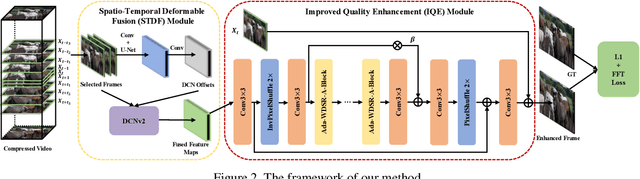
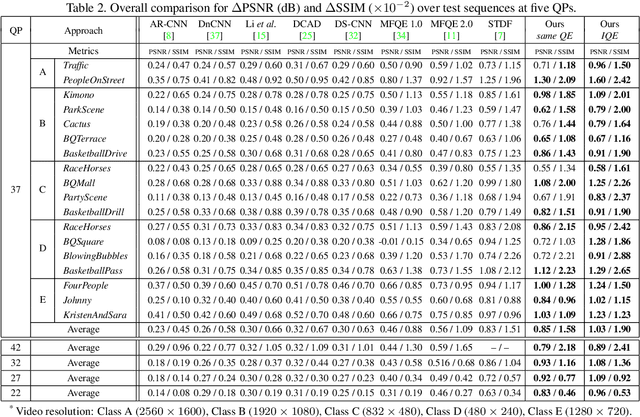
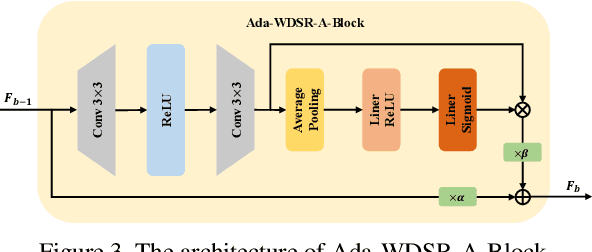
Many deep learning based video compression artifact removal algorithms have been proposed to recover high-quality videos from low-quality compressed videos. Recently, methods were proposed to mine spatiotemporal information via utilizing multiple neighboring frames as reference frames. However, these post-processing methods take advantage of adjacent frames directly, but neglect the information of the video itself, which can be exploited. In this paper, we propose an effective reference frame proposal strategy to boost the performance of the existing multi-frame approaches. Besides, we introduce a loss based on fast Fourier transformation~(FFT) to further improve the effectiveness of restoration. Experimental results show that our method achieves better fidelity and perceptual performance on MFQE 2.0 dataset than the state-of-the-art methods. And our method won Track 1 and Track 2, and was ranked the 2nd in Track 3 of NTIRE 2021 Quality enhancement of heavily compressed videos Challenge.
Dance Generation with Style Embedding: Learning and Transferring Latent Representations of Dance Styles
Apr 30, 2021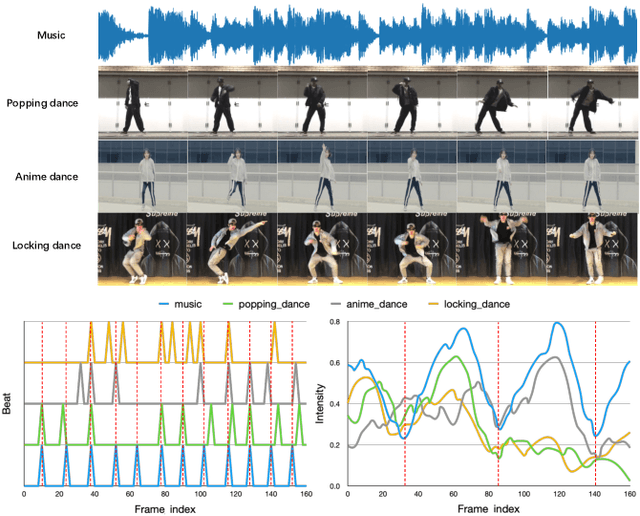
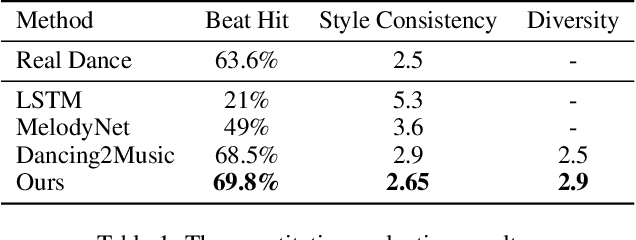
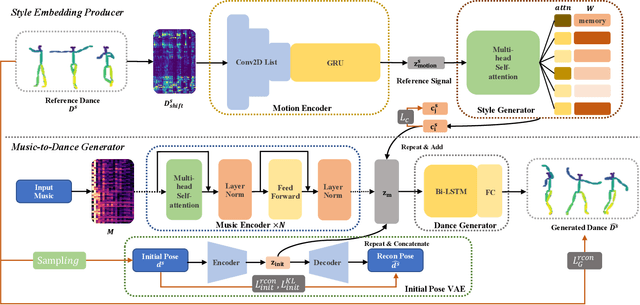
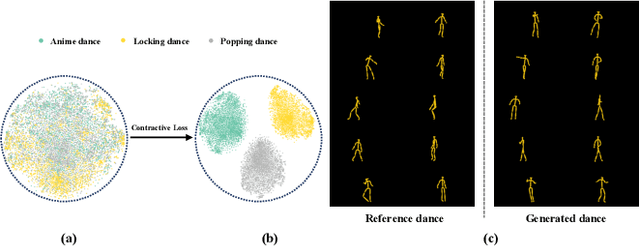
Choreography refers to creation of dance steps and motions for dances according to the latent knowledge in human mind, where the created dance motions are in general style-specific and consistent. So far, such latent style-specific knowledge about dance styles cannot be represented explicitly in human language and has not yet been learned in previous works on music-to-dance generation tasks. In this paper, we propose a novel music-to-dance synthesis framework with controllable style embeddings. These embeddings are learned representations of style-consistent kinematic abstraction of reference dance clips, which act as controllable factors to impose style constraints on dance generation in a latent manner. Thus, the dance styles can be transferred to dance motions by merely modifying the style embeddings. To support this study, we build a large music-to-dance dataset. The qualitative and quantitative evaluations demonstrate the advantage of our proposed framework, as well as the ability of synthesizing diverse styles of dances from identical music via style embeddings.
Non-Local ConvLSTM for Video Compression Artifact Reduction
Oct 27, 2019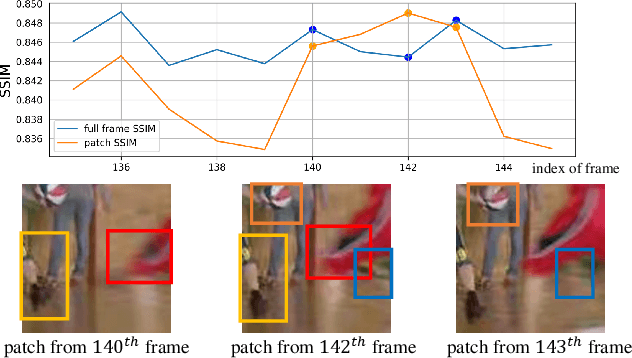
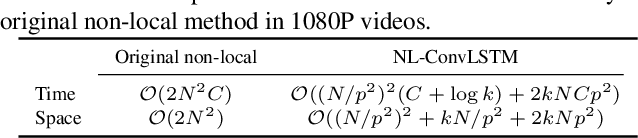
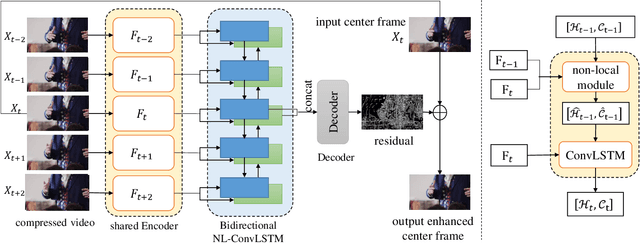

Video compression artifact reduction aims to recover high-quality videos from low-quality compressed videos. Most existing approaches use a single neighboring frame or a pair of neighboring frames (preceding and/or following the target frame) for this task. Furthermore, as frames of high quality overall may contain low-quality patches, and high-quality patches may exist in frames of low quality overall, current methods focusing on nearby peak-quality frames (PQFs) may miss high-quality details in low-quality frames. To remedy these shortcomings, in this paper we propose a novel end-to-end deep neural network called non-local ConvLSTM (NL-ConvLSTM in short) that exploits multiple consecutive frames. An approximate non-local strategy is introduced in NL-ConvLSTM to capture global motion patterns and trace the spatiotemporal dependency in a video sequence. This approximate strategy makes the non-local module work in a fast and low space-cost way. Our method uses the preceding and following frames of the target frame to generate a residual, from which a higher quality frame is reconstructed. Experiments on two datasets show that NL-ConvLSTM outperforms the existing methods.