 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEDOB: Semantic Image Editing by Disentangling Object and Background
Mar 23, 2023



Semantic image editing provides users with a flexible tool to modify a given image guided by a corresponding segmentation map. In this task, the features of the foreground objects and the backgrounds are quite different. However, all previous methods handle backgrounds and objects as a whole using a monolithic model. Consequently, they remain limited in processing content-rich images and suffer from generating unrealistic objects and texture-inconsistent backgrounds. To address this issue, we propose a novel paradigm, \textbf{S}emantic \textbf{I}mage \textbf{E}diting by \textbf{D}isentangling \textbf{O}bject and \textbf{B}ackground (\textbf{SIEDOB}), the core idea of which is to explicitly leverages several heterogeneous subnetworks for objects and backgrounds. First, SIEDOB disassembles the edited input into background regions and instance-level objects. Then, we feed them into the dedicated generators. Finally, all synthesized parts are embedded in their original locations and utilize a fusion network to obtain a harmonized result. Moreover, to produce high-quality edited images, we propose some innovative designs, including Semantic-Aware Self-Propagation Module, Boundary-Anchored Patch Discriminator, and Style-Diversity Object Generator, and integrate them into SIEDOB. We conduct extensive experiments on Cityscapes and ADE20K-Room datasets and exhibit that our method remarkably outperforms the baselines, especially in synthesizing realistic and diverse objects and texture-consistent backgrounds.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
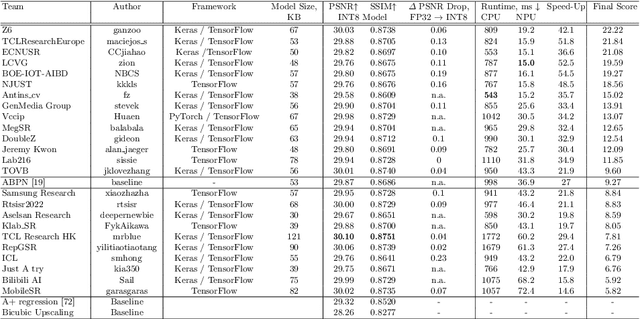
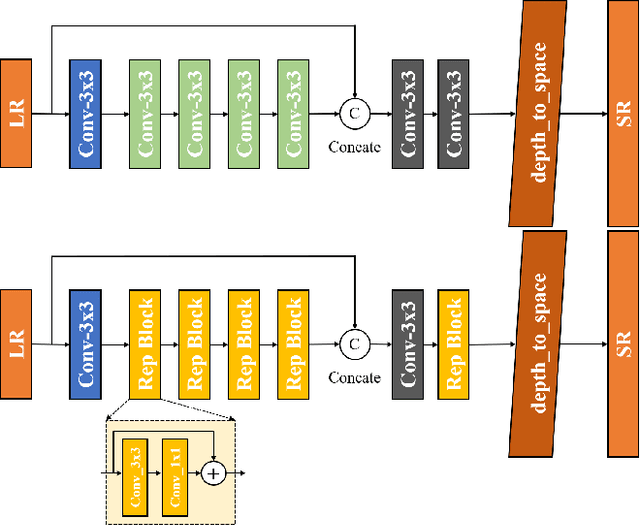
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022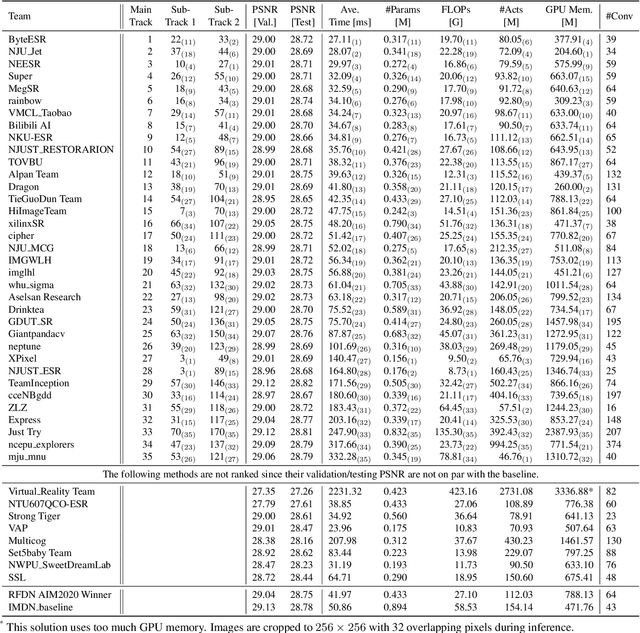
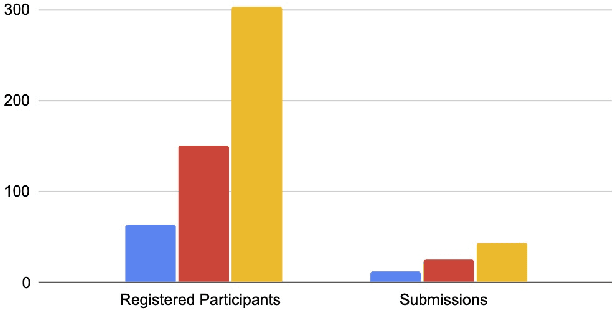
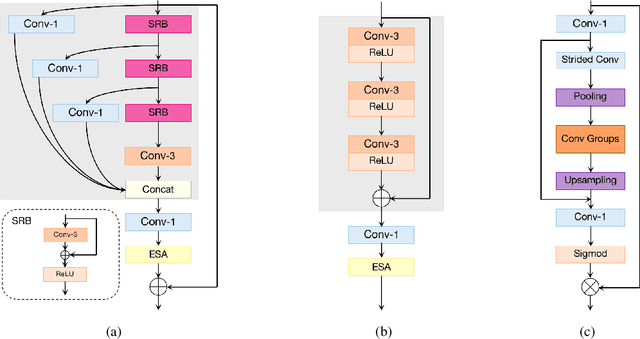
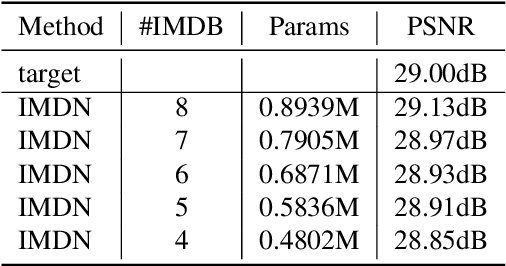
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Optimizing Ghost Imaging via Analysis and Design of Speckle Patterns
Mar 10, 2022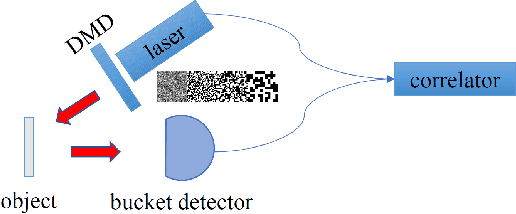



We study the influence rules of the speckle size of light source on ghost imaging, and propose a new type of speckle patterns to improve the quality of ghost imaging. The results show that the image quality will first increase and then decrease with the increase of the speckle size, and there is an optimal speckle size for a specific object. Moreover, by using the random distribution of speckle positions, a new type of displacement speckle patterns is designed, and the imaging quality is better than that of the random speckle patterns. These results are of great significances for finding the best speckle patterns suitable for detecting targets, which further promotes the practical applications of ghost imaging.
Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and Frequency Domain Information
May 31, 2021
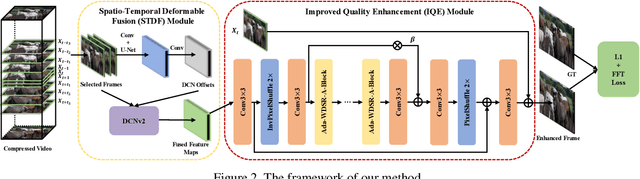
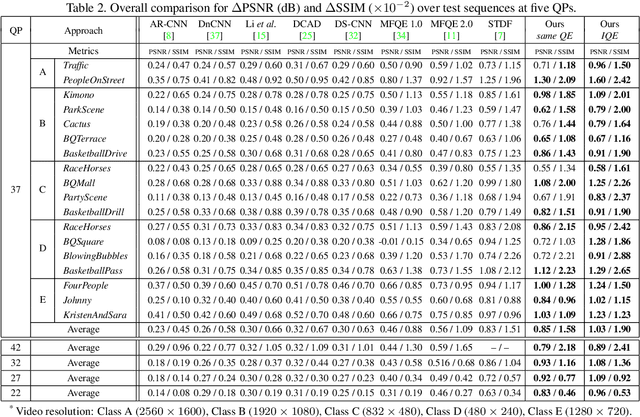
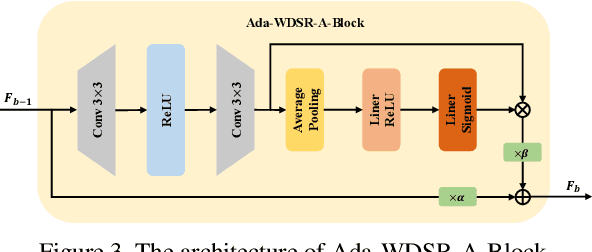
Many deep learning based video compression artifact removal algorithms have been proposed to recover high-quality videos from low-quality compressed videos. Recently, methods were proposed to mine spatiotemporal information via utilizing multiple neighboring frames as reference frames. However, these post-processing methods take advantage of adjacent frames directly, but neglect the information of the video itself, which can be exploited. In this paper, we propose an effective reference frame proposal strategy to boost the performance of the existing multi-frame approaches. Besides, we introduce a loss based on fast Fourier transformation~(FFT) to further improve the effectiveness of restoration. Experimental results show that our method achieves better fidelity and perceptual performance on MFQE 2.0 dataset than the state-of-the-art methods. And our method won Track 1 and Track 2, and was ranked the 2nd in Track 3 of NTIRE 2021 Quality enhancement of heavily compressed videos Challenge.
Video Anomaly Detection By The Duality Of Normality-Granted Optical Flow
May 10, 2021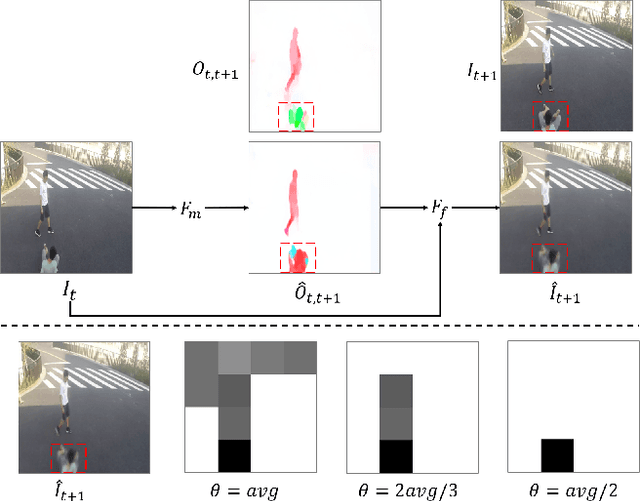
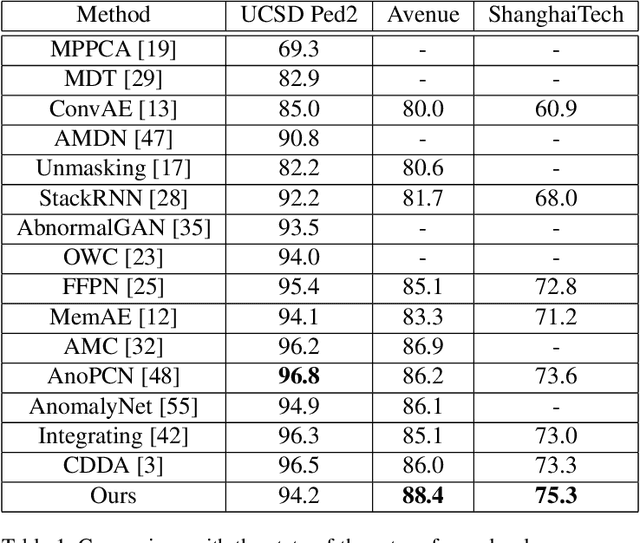
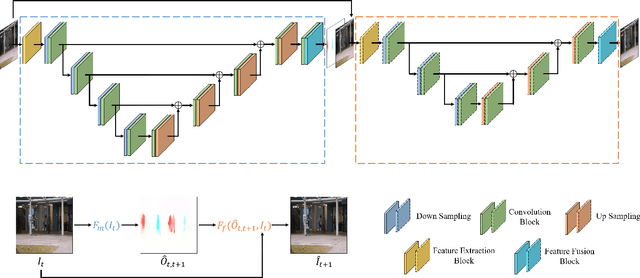
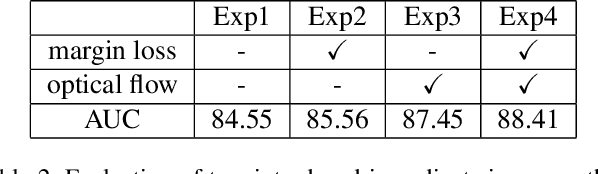
Video anomaly detection is a challenging task because of diverse abnormal events. To this task, methods based on reconstruction and prediction are wildly used in recent works, which are built on the assumption that learning on normal data, anomalies cannot be reconstructed or predicated as good as normal patterns, namely the anomaly result with more errors. In this paper, we propose to discriminate anomalies from normal ones by the duality of normality-granted optical flow, which is conducive to predict normal frames but adverse to abnormal frames. The normality-granted optical flow is predicted from a single frame, to keep the motion knowledge focused on normal patterns. Meanwhile, We extend the appearance-motion correspondence scheme from frame reconstruction to prediction, which not only helps to learn the knowledge about object appearances and correlated motion, but also meets the fact that motion is the transformation between appearances. We also introduce a margin loss to enhance the learning of frame prediction. Experiments on standard benchmark datasets demonstrate the impressive performance of our approach.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021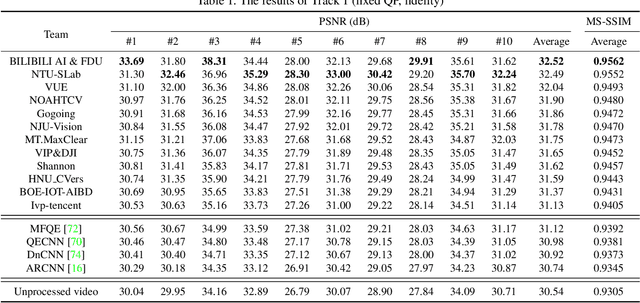
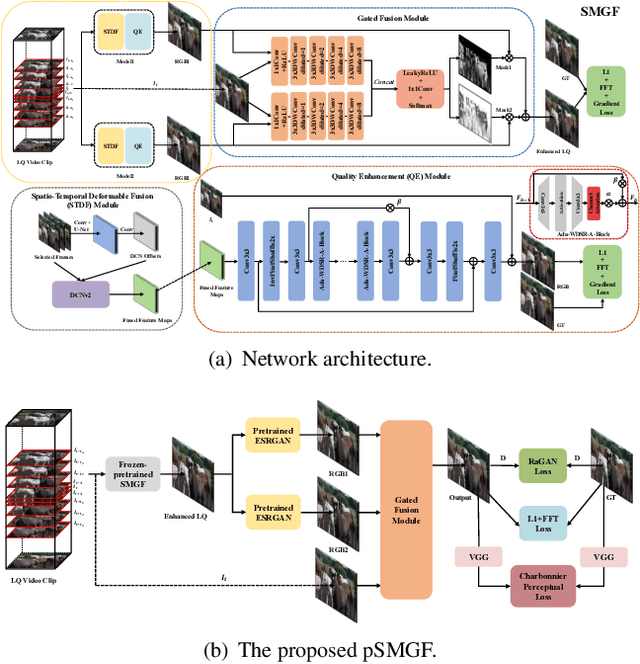
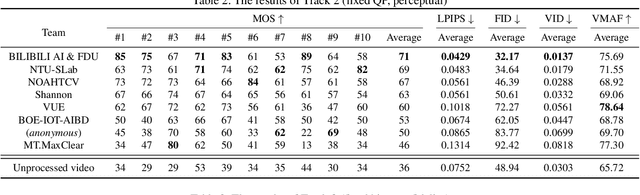
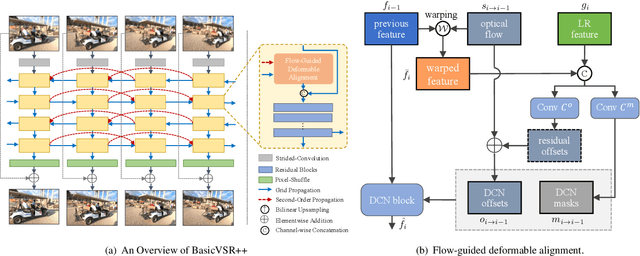
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Dance Generation with Style Embedding: Learning and Transferring Latent Representations of Dance Styles
Apr 30, 2021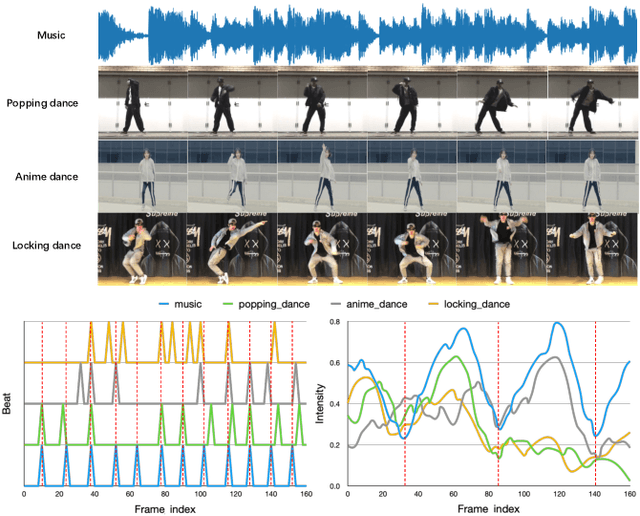
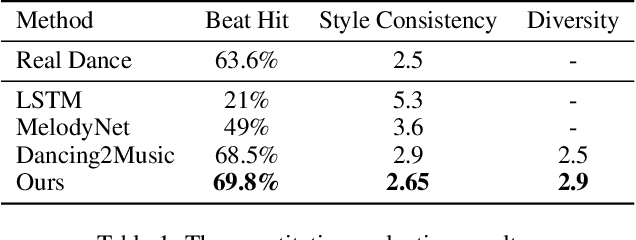
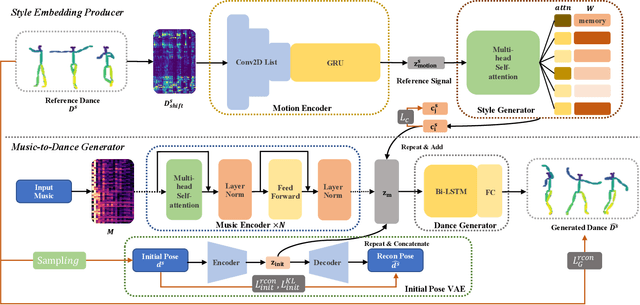
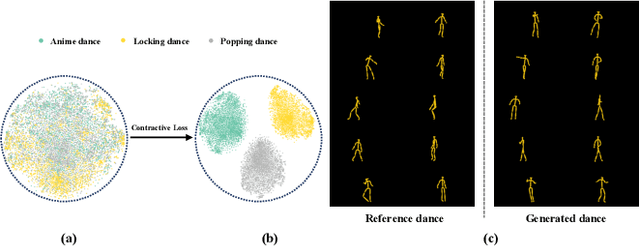
Choreography refers to creation of dance steps and motions for dances according to the latent knowledge in human mind, where the created dance motions are in general style-specific and consistent. So far, such latent style-specific knowledge about dance styles cannot be represented explicitly in human language and has not yet been learned in previous works on music-to-dance generation tasks. In this paper, we propose a novel music-to-dance synthesis framework with controllable style embeddings. These embeddings are learned representations of style-consistent kinematic abstraction of reference dance clips, which act as controllable factors to impose style constraints on dance generation in a latent manner. Thus, the dance styles can be transferred to dance motions by merely modifying the style embeddings. To support this study, we build a large music-to-dance dataset. The qualitative and quantitative evaluations demonstrate the advantage of our proposed framework, as well as the ability of synthesizing diverse styles of dances from identical music via style embeddings.
Anomaly Detection and Localization in Crowded Scenes by Motion-field Shape Description and Similarity-based Statistical Learning
May 27, 2018
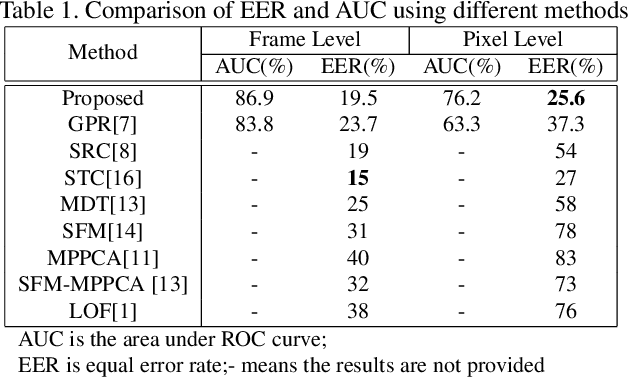


In crowded scenes, detection and localization of abnormal behaviors is challenging in that high-density people make object segmentation and tracking extremely difficult. We associate the optical flows of multiple frames to capture short-term trajectories and introduce the histogram-based shape descriptor referred to as shape contexts to describe such short-term trajectories. Furthermore, we propose a K-NN similarity-based statistical model to detect anomalies over time and space, which is an unsupervised one-class learning algorithm requiring no clustering nor any prior assumption. Firstly, we retrieve the K-NN samples from the training set in regard to the testing sample, and then use the similarities between every pair of the K-NN samples to construct a Gaussian model. Finally, the probabilities of the similarities from the testing sample to the K-NN samples under the Gaussian model are calculated in the form of a joint probability. Abnormal events can be detected by judging whether the joint probability is below predefined thresholds in terms of time and space, separately. Such a scheme can adapt to the whole scene, since the probability computed as such is not affected by motion distortions arising from perspective distortion. We conduct experiments on real-world surveillance videos, and the results demonstrate that the proposed method can reliably detect and locate the abnormal events in the video sequences, outperforming the state-of-the-art approaches.