 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeMar: Multi-Scale Autoregressive Modeling for Unconditional Time Series Generation
Jan 16, 2026Generative modeling offers a promising solution to data scarcity and privacy challenges in time series analysis. However, the structural complexity of time series, characterized by multi-scale temporal patterns and heterogeneous components, remains insufficiently addressed. In this work, we propose a structure-disentangled multiscale generation framework for time series. Our approach encodes sequences into discrete tokens at multiple temporal resolutions and performs autoregressive generation in a coarse-to-fine manner, thereby preserving hierarchical dependencies. To tackle structural heterogeneity, we introduce a dual-path VQ-VAE that disentangles trend and seasonal components, enabling the learning of semantically consistent latent representations. Additionally, we present a guidance-based reconstruction strategy, where coarse seasonal signals are utilized as priors to guide the reconstruction of fine-grained seasonal patterns. Experiments on six datasets show that our approach produces higher-quality time series than existing methods. Notably, our model achieves strong performance with a significantly reduced parameter count and exhibits superior capability in generating high-quality long-term sequences. Our implementation is available at https://anonymous.4open.science/r/TimeMAR-BC5B.
Authority Backdoor: A Certifiable Backdoor Mechanism for Authoring DNNs
Dec 11, 2025



Deep Neural Networks (DNNs), as valuable intellectual property, face unauthorized use. Existing protections, such as digital watermarking, are largely passive; they provide only post-hoc ownership verification and cannot actively prevent the illicit use of a stolen model. This work proposes a proactive protection scheme, dubbed ``Authority Backdoor," which embeds access constraints directly into the model. In particular, the scheme utilizes a backdoor learning framework to intrinsically lock a model's utility, such that it performs normally only in the presence of a specific trigger (e.g., a hardware fingerprint). But in its absence, the DNN's performance degrades to be useless. To further enhance the security of the proposed authority scheme, the certifiable robustness is integrated to prevent an adaptive attacker from removing the implanted backdoor. The resulting framework establishes a secure authority mechanism for DNNs, combining access control with certifiable robustness against adversarial attacks. Extensive experiments on diverse architectures and datasets validate the effectiveness and certifiable robustness of the proposed framework.
PerchMobi^3: A Multi-Modal Robot with Power-Reuse Quad-Fan Mechanism for Air-Ground-Wall Locomotion
Sep 16, 2025Achieving seamless integration of aerial flight, ground driving, and wall climbing within a single robotic platform remains a major challenge, as existing designs often rely on additional adhesion actuators that increase complexity, reduce efficiency, and compromise reliability. To address these limitations, we present PerchMobi^3, a quad-fan, negative-pressure, air-ground-wall robot that implements a propulsion-adhesion power-reuse mechanism. By repurposing four ducted fans to simultaneously provide aerial thrust and negative-pressure adhesion, and integrating them with four actively driven wheels, PerchMobi^3 eliminates dedicated pumps while maintaining a lightweight and compact design. To the best of our knowledge, this is the first quad-fan prototype to demonstrate functional power reuse for multi-modal locomotion. A modeling and control framework enables coordinated operation across ground, wall, and aerial domains with fan-assisted transitions. The feasibility of the design is validated through a comprehensive set of experiments covering ground driving, payload-assisted wall climbing, aerial flight, and cross-mode transitions, demonstrating robust adaptability across locomotion scenarios. These results highlight the potential of PerchMobi^3 as a novel design paradigm for multi-modal robotic mobility, paving the way for future extensions toward autonomous and application-oriented deployment.
Beyond Demographics: Enhancing Cultural Value Survey Simulation with Multi-Stage Personality-Driven Cognitive Reasoning
Aug 25, 2025



Introducing MARK, the Multi-stAge Reasoning frameworK for cultural value survey response simulation, designed to enhance the accuracy, steerability, and interpretability of large language models in this task. The system is inspired by the type dynamics theory in the MBTI psychological framework for personality research. It effectively predicts and utilizes human demographic information for simulation: life-situational stress analysis, group-level personality prediction, and self-weighted cognitive imitation. Experiments on the World Values Survey show that MARK outperforms existing baselines by 10% accuracy and reduces the divergence between model predictions and human preferences. This highlights the potential of our framework to improve zero-shot personalization and help social scientists interpret model predictions.
Rate-Distortion-Perception Theory for the Quadratic Wasserstein Space
Apr 24, 2025

We establish a single-letter characterization of the fundamental distortion-rate-perception tradeoff with limited common randomness under the squared error distortion measure and the squared Wasserstein-2 perception measure. Moreover, it is shown that this single-letter characterization can be explicitly evaluated for the Gaussian source. Various notions of universal representation are also clarified.
Diffusion-Based mmWave Radar Point Cloud Enhancement Driven by Range Images
Mar 04, 2025Millimeter-wave (mmWave) radar has attracted significant attention in robotics and autonomous driving. However, despite the perception stability in harsh environments, the point cloud generated by mmWave radar is relatively sparse while containing significant noise, which limits its further development. Traditional mmWave radar enhancement approaches often struggle to leverage the effectiveness of diffusion models in super-resolution, largely due to the unnatural range-azimuth heatmap (RAH) or bird's eye view (BEV) representation. To overcome this limitation, we propose a novel method that pioneers the application of fusing range images with image diffusion models, achieving accurate and dense mmWave radar point clouds that are similar to LiDAR. Benefitting from the projection that aligns with human observation, the range image representation of mmWave radar is close to natural images, allowing the knowledge from pre-trained image diffusion models to be effectively transferred, significantly improving the overall performance. Extensive evaluations on both public datasets and self-constructed datasets demonstrate that our approach provides substantial improvements, establishing a new state-of-the-art performance in generating truly three-dimensional LiDAR-like point clouds via mmWave radar.
ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Jan 12, 2025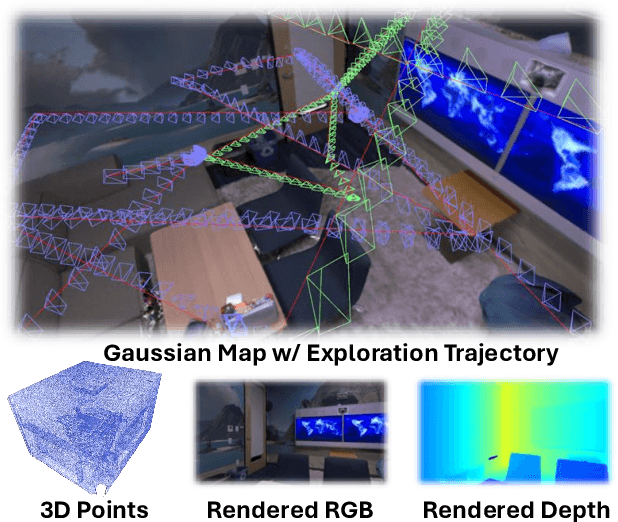
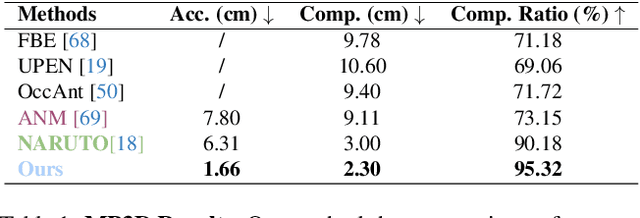

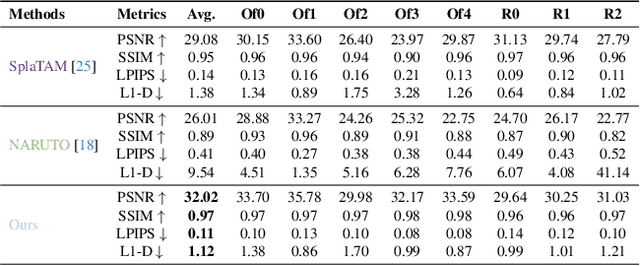
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER's effectiveness in active mapping tasks.
EFTViT: Efficient Federated Training of Vision Transformers with Masked Images on Resource-Constrained Edge Devices
Nov 30, 2024



Federated learning research has recently shifted from Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs) due to their superior capacity. ViTs training demands higher computational resources due to the lack of 2D inductive biases inherent in CNNs. However, efficient federated training of ViTs on resource-constrained edge devices remains unexplored in the community. In this paper, we propose EFTViT, a hierarchical federated framework that leverages masked images to enable efficient, full-parameter training on resource-constrained edge devices, offering substantial benefits for learning on heterogeneous data. In general, we patchify images and randomly mask a portion of the patches, observing that excluding them from training has minimal impact on performance while substantially reducing computation costs and enhancing data content privacy protection. Specifically, EFTViT comprises a series of lightweight local modules and a larger global module, updated independently on clients and the central server, respectively. The local modules are trained on masked image patches, while the global module is trained on intermediate patch features uploaded from the local client, balanced through a proposed median sampling strategy to erase client data distribution privacy. We analyze the computational complexity and privacy protection of EFTViT. Extensive experiments on popular benchmarks show that EFTViT achieves up to 28.17% accuracy improvement, reduces local training computational cost by up to 2.8$\times$, and cuts local training time by up to 4.4$\times$ compared to existing methods.
SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation
Apr 23, 2024



Existing Transformers for monocular 3D human shape and pose estimation typically have a quadratic computation and memory complexity with respect to the feature length, which hinders the exploitation of fine-grained information in high-resolution features that is beneficial for accurate reconstruction. In this work, we propose an SMPL-based Transformer framework (SMPLer) to address this issue. SMPLer incorporates two key ingredients: a decoupled attention operation and an SMPL-based target representation, which allow effective utilization of high-resolution features in the Transformer. In addition, based on these two designs, we also introduce several novel modules including a multi-scale attention and a joint-aware attention to further boost the reconstruction performance. Extensive experiments demonstrate the effectiveness of SMPLer against existing 3D human shape and pose estimation methods both quantitatively and qualitatively. Notably, the proposed algorithm achieves an MPJPE of 45.2 mm on the Human3.6M dataset, improving upon Mesh Graphormer by more than 10% with fewer than one-third of the parameters. Code and pretrained models are available at https://github.com/xuxy09/SMPLer.
* Published at TPAMI 2024
Motion-adaptive Separable Collaborative Filters for Blind Motion Deblurring
Apr 19, 2024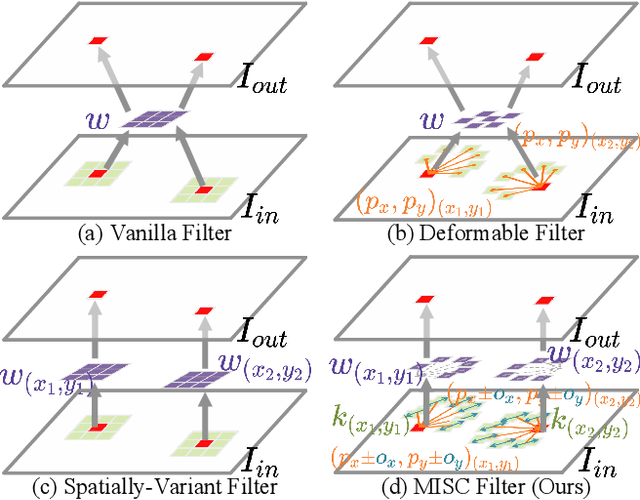
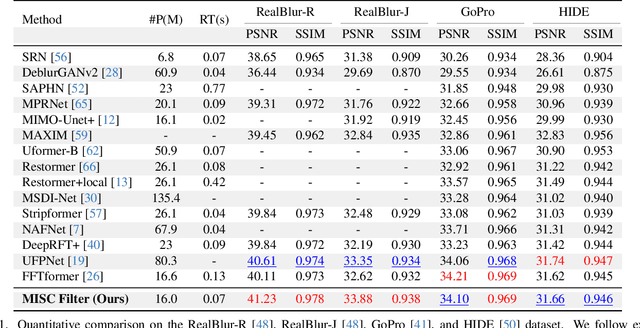
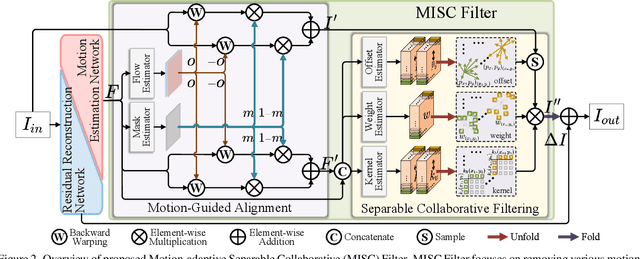
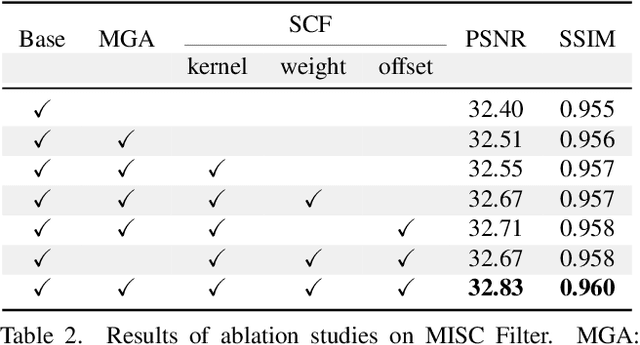
Eliminating image blur produced by various kinds of motion has been a challenging problem. Dominant approaches rely heavily on model capacity to remove blurring by reconstructing residual from blurry observation in feature space. These practices not only prevent the capture of spatially variable motion in the real world but also ignore the tailored handling of various motions in image space. In this paper, we propose a novel real-world deblurring filtering model called the Motion-adaptive Separable Collaborative (MISC) Filter. In particular, we use a motion estimation network to capture motion information from neighborhoods, thereby adaptively estimating spatially-variant motion flow, mask, kernels, weights, and offsets to obtain the MISC Filter. The MISC Filter first aligns the motion-induced blurring patterns to the motion middle along the predicted flow direction, and then collaboratively filters the aligned image through the predicted kernels, weights, and offsets to generate the output. This design can handle more generalized and complex motion in a spatially differentiated manner. Furthermore, we analyze the relationships between the motion estimation network and the residual reconstruction network. Extensive experiments on four widely used benchmarks demonstrate that our method provides an effective solution for real-world motion blur removal and achieves state-of-the-art performance. Code is available at https://github.com/ChengxuLiu/MISCFilter