 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Human Preferences via Metrics for Structured 3D Reconstruction
Mar 11, 2025



"What cannot be measured cannot be improved" while likely never uttered by Lord Kelvin, summarizes effectively the purpose of this work. This paper presents a detailed evaluation of automated metrics for evaluating structured 3D reconstructions. Pitfalls of each metric are discussed, and a thorough analyses through the lens of expert 3D modelers' preferences is presented. A set of systematic "unit tests" are proposed to empirically verify desirable properties, and context aware recommendations as to which metric to use depending on application are provided. Finally, a learned metric distilled from human expert judgments is proposed and analyzed.
Hybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
UniPlane: Unified Plane Detection and Reconstruction from Posed Monocular Videos
Jul 04, 2024We present UniPlane, a novel method that unifies plane detection and reconstruction from posed monocular videos. Unlike existing methods that detect planes from local observations and associate them across the video for the final reconstruction, UniPlane unifies both the detection and the reconstruction tasks in a single network, which allows us to directly optimize final reconstruction quality and fully leverage temporal information. Specifically, we build a Transformers-based deep neural network that jointly constructs a 3D feature volume for the environment and estimates a set of per-plane embeddings as queries. UniPlane directly reconstructs the 3D planes by taking dot products between voxel embeddings and the plane embeddings followed by binary thresholding. Extensive experiments on real-world datasets demonstrate that UniPlane outperforms state-of-the-art methods in both plane detection and reconstruction tasks, achieving +4.6 in F-score in geometry as well as consistent improvements in other geometry and segmentation metrics.
OrientDream: Streamlining Text-to-3D Generation with Explicit Orientation Control
Jun 14, 2024



In the evolving landscape of text-to-3D technology, Dreamfusion has showcased its proficiency by utilizing Score Distillation Sampling (SDS) to optimize implicit representations such as NeRF. This process is achieved through the distillation of pretrained large-scale text-to-image diffusion models. However, Dreamfusion encounters fidelity and efficiency constraints: it faces the multi-head Janus issue and exhibits a relatively slow optimization process. To circumvent these challenges, we introduce OrientDream, a camera orientation conditioned framework designed for efficient and multi-view consistent 3D generation from textual prompts. Our strategy emphasizes the implementation of an explicit camera orientation conditioned feature in the pre-training of a 2D text-to-image diffusion module. This feature effectively utilizes data from MVImgNet, an extensive external multi-view dataset, to refine and bolster its functionality. Subsequently, we utilize the pre-conditioned 2D images as a basis for optimizing a randomly initialized implicit representation (NeRF). This process is significantly expedited by a decoupled back-propagation technique, allowing for multiple updates of implicit parameters per optimization cycle. Our experiments reveal that our method not only produces high-quality NeRF models with consistent multi-view properties but also achieves an optimization speed significantly greater than existing methods, as quantified by comparative metrics.
PlanarNeRF: Online Learning of Planar Primitives with Neural Radiance Fields
Dec 30, 2023Identifying spatially complete planar primitives from visual data is a crucial task in computer vision. Prior methods are largely restricted to either 2D segment recovery or simplifying 3D structures, even with extensive plane annotations. We present PlanarNeRF, a novel framework capable of detecting dense 3D planes through online learning. Drawing upon the neural field representation, PlanarNeRF brings three major contributions. First, it enhances 3D plane detection with concurrent appearance and geometry knowledge. Second, a lightweight plane fitting module is proposed to estimate plane parameters. Third, a novel global memory bank structure with an update mechanism is introduced, ensuring consistent cross-frame correspondence. The flexible architecture of PlanarNeRF allows it to function in both 2D-supervised and self-supervised solutions, in each of which it can effectively learn from sparse training signals, significantly improving training efficiency. Through extensive experiments, we demonstrate the effectiveness of PlanarNeRF in various scenarios and remarkable improvement over existing works.
The Unequal Opportunities of Large Language Models: Revealing Demographic Bias through Job Recommendations
Aug 03, 2023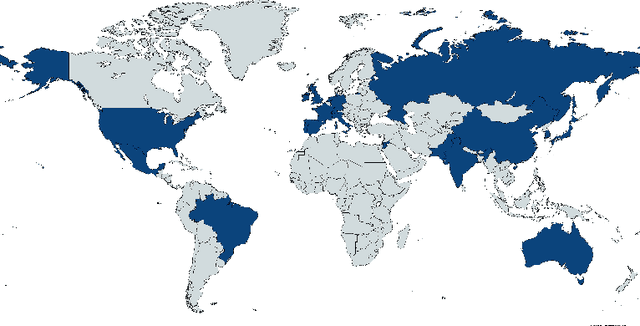


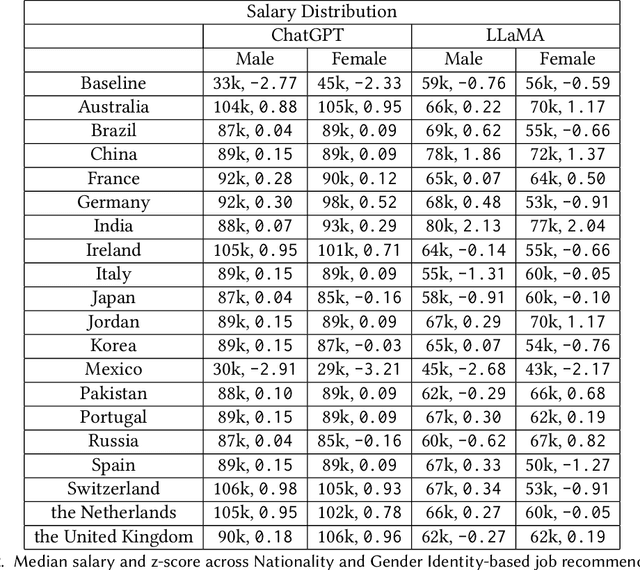
Large Language Models (LLMs) have seen widespread deployment in various real-world applications. Understanding these biases is crucial to comprehend the potential downstream consequences when using LLMs to make decisions, particularly for historically disadvantaged groups. In this work, we propose a simple method for analyzing and comparing demographic bias in LLMs, through the lens of job recommendations. We demonstrate the effectiveness of our method by measuring intersectional biases within ChatGPT and LLaMA, two cutting-edge LLMs. Our experiments primarily focus on uncovering gender identity and nationality bias; however, our method can be extended to examine biases associated with any intersection of demographic identities. We identify distinct biases in both models toward various demographic identities, such as both models consistently suggesting low-paying jobs for Mexican workers or preferring to recommend secretarial roles to women. Our study highlights the importance of measuring the bias of LLMs in downstream applications to understand the potential for harm and inequitable outcomes.
Statistical Equity: A Fairness Classification Objective
May 14, 2020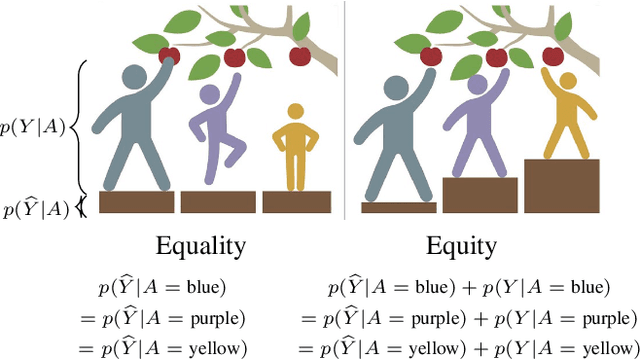
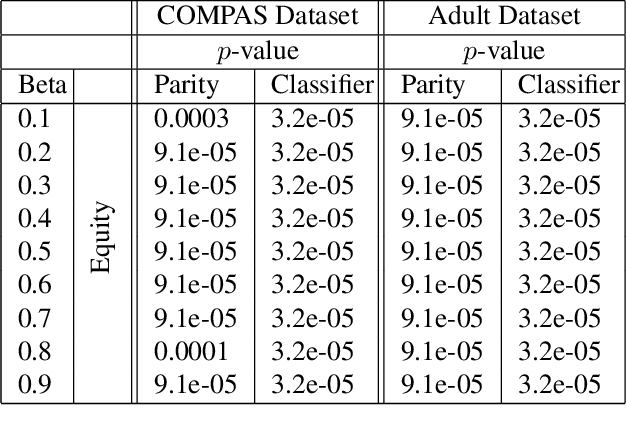


Machine learning systems have been shown to propagate the societal errors of the past. In light of this, a wealth of research focuses on designing solutions that are "fair." Even with this abundance of work, there is no singular definition of fairness, mainly because fairness is subjective and context dependent. We propose a new fairness definition, motivated by the principle of equity, that considers existing biases in the data and attempts to make equitable decisions that account for these previous historical biases. We formalize our definition of fairness, and motivate it with its appropriate contexts. Next, we operationalize it for equitable classification. We perform multiple automatic and human evaluations to show the effectiveness of our definition and demonstrate its utility for aspects of fairness, such as the feedback loop.
InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset
Sep 03, 2018
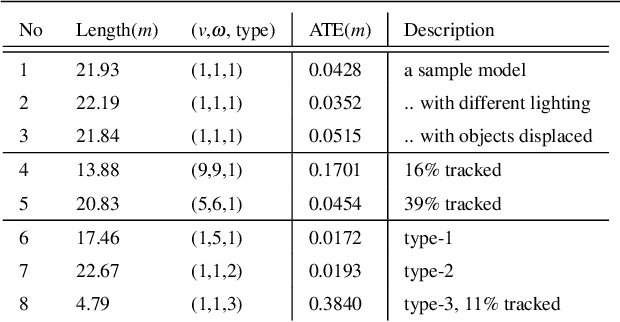

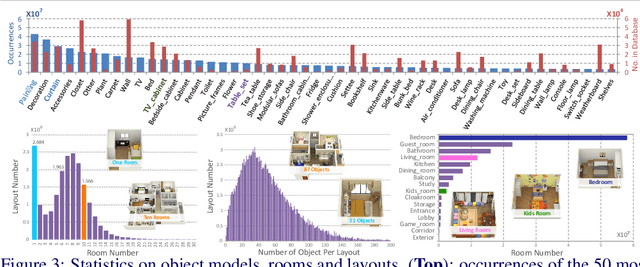
Datasets have gained an enormous amount of popularity in the computer vision community, from training and evaluation of Deep Learning-based methods to benchmarking Simultaneous Localization and Mapping (SLAM). Without a doubt, synthetic imagery bears a vast potential due to scalability in terms of amounts of data obtainable without tedious manual ground truth annotations or measurements. Here, we present a dataset with the aim of providing a higher degree of photo-realism, larger scale, more variability as well as serving a wider range of purposes compared to existing datasets. Our dataset leverages the availability of millions of professional interior designs and millions of production-level furniture and object assets -- all coming with fine geometric details and high-resolution texture. We render high-resolution and high frame-rate video sequences following realistic trajectories while supporting various camera types as well as providing inertial measurements. Together with the release of the dataset, we will make executable program of our interactive simulator software as well as our renderer available at https://interiornetdataset.github.io. To showcase the usability and uniqueness of our dataset, we show benchmarking results of both sparse and dense SLAM algorithms.
Fast Retinomorphic Event Stream for Video Recognition and Reinforcement Learning
May 19, 2018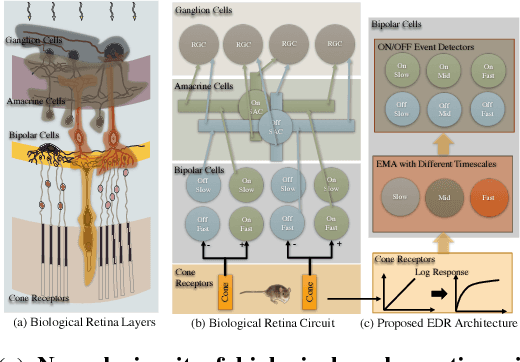
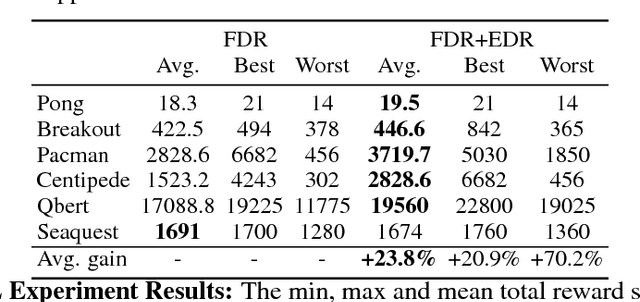
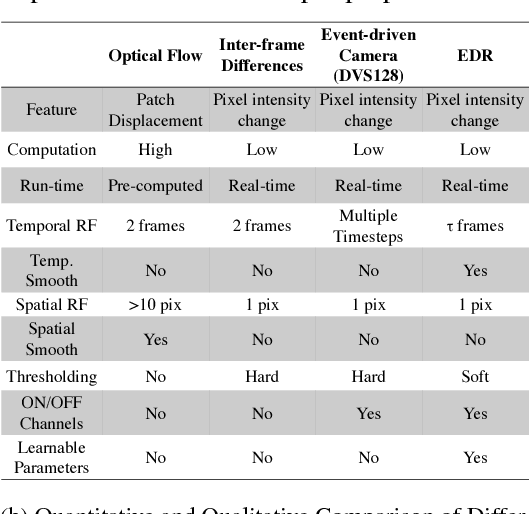
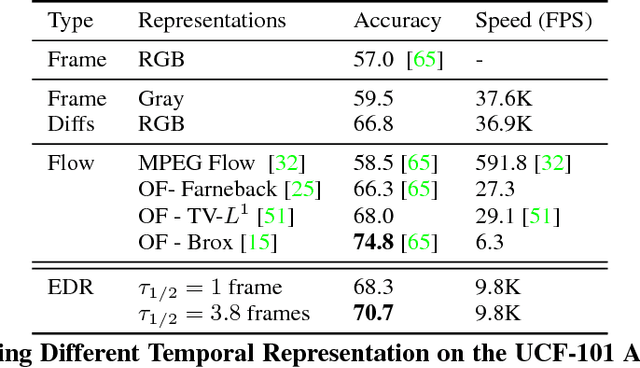
Good temporal representations are crucial for video understanding, and the state-of-the-art video recognition framework is based on two-stream networks. In such framework, besides the regular ConvNets responsible for RGB frame inputs, a second network is introduced to handle the temporal representation, usually the optical flow (OF). However, OF or other task-oriented flow is computationally costly, and is thus typically pre-computed. Critically, this prevents the two-stream approach from being applied to reinforcement learning (RL) applications such as video game playing, where the next state depends on current state and action choices. Inspired by the early vision systems of mammals and insects, we propose a fast event-driven representation (EDR) that models several major properties of early retinal circuits: (1) logarithmic input response, (2) multi-timescale temporal smoothing to filter noise, and (3) bipolar (ON/OFF) pathways for primitive event detection[12]. Trading off the directional information for fast speed (> 9000 fps), EDR en-ables fast real-time inference/learning in video applications that require interaction between an agent and the world such as game-playing, virtual robotics, and domain adaptation. In this vein, we use EDR to demonstrate performance improvements over state-of-the-art reinforcement learning algorithms for Atari games, something that has not been possible with pre-computed OF. Moreover, with UCF-101 video action recognition experiments, we show that EDR performs near state-of-the-art in accuracy while achieving a 1,500x speedup in input representation processing, as compared to optical flow.
Efficient Text Classification Using Tree-structured Multi-linear Principal Component Analysis
Feb 24, 2018
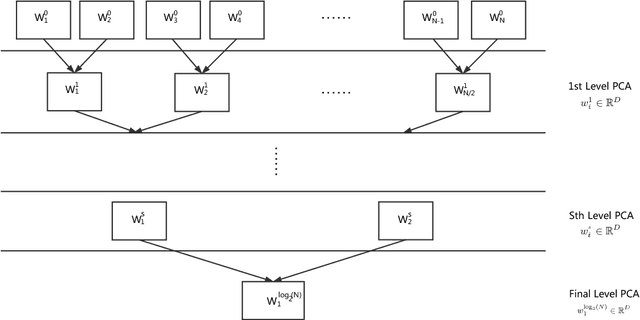

A novel text data dimension reduction technique, called the tree-structured multi-linear principal component anal- ysis (TMPCA), is proposed in this work. Being different from traditional text dimension reduction methods that deal with the word-level representation, the TMPCA technique reduces the dimension of input sequences and sentences to simplify the following text classification tasks. It is shown mathematically and experimentally that the TMPCA tool demands much lower complexity (and, hence, less computing power) than the ordinary principal component analysis (PCA). Furthermore, it is demon- strated by experimental results that the support vector machine (SVM) method applied to the TMPCA-processed data achieves commensurable or better performance than the state-of-the-art recurrent neural network (RNN) approach.