 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Human Preferences via Metrics for Structured 3D Reconstruction
Mar 11, 2025



"What cannot be measured cannot be improved" while likely never uttered by Lord Kelvin, summarizes effectively the purpose of this work. This paper presents a detailed evaluation of automated metrics for evaluating structured 3D reconstructions. Pitfalls of each metric are discussed, and a thorough analyses through the lens of expert 3D modelers' preferences is presented. A set of systematic "unit tests" are proposed to empirically verify desirable properties, and context aware recommendations as to which metric to use depending on application are provided. Finally, a learned metric distilled from human expert judgments is proposed and analyzed.
AffineGlue: Joint Matching and Robust Estimation
Jul 28, 2023



We propose AffineGlue, a method for joint two-view feature matching and robust estimation that reduces the combinatorial complexity of the problem by employing single-point minimal solvers. AffineGlue selects potential matches from one-to-many correspondences to estimate minimal models. Guided matching is then used to find matches consistent with the model, suffering less from the ambiguities of one-to-one matches. Moreover, we derive a new minimal solver for homography estimation, requiring only a single affine correspondence (AC) and a gravity prior. Furthermore, we train a neural network to reject ACs that are unlikely to lead to a good model. AffineGlue is superior to the SOTA on real-world datasets, even when assuming that the gravity direction points downwards. On PhotoTourism, the AUC@10{\deg} score is improved by 6.6 points compared to the SOTA. On ScanNet, AffineGlue makes SuperPoint and SuperGlue achieve similar accuracy as the detector-free LoFTR.
A Large Scale Homography Benchmark
Feb 20, 2023



We present a large-scale dataset of Planes in 3D, Pi3D, of roughly 1000 planes observed in 10 000 images from the 1DSfM dataset, and HEB, a large-scale homography estimation benchmark leveraging Pi3D. The applications of the Pi3D dataset are diverse, e.g. training or evaluating monocular depth, surface normal estimation and image matching algorithms. The HEB dataset consists of 226 260 homographies and includes roughly 4M correspondences. The homographies link images that often undergo significant viewpoint and illumination changes. As applications of HEB, we perform a rigorous evaluation of a wide range of robust estimators and deep learning-based correspondence filtering methods, establishing the current state-of-the-art in robust homography estimation. We also evaluate the uncertainty of the SIFT orientations and scales w.r.t. the ground truth coming from the underlying homographies and provide codes for comparing uncertainty of custom detectors. The dataset is available at \url{https://github.com/danini/homography-benchmark}.
Matching with AffNet based rectifications
Jul 29, 2022
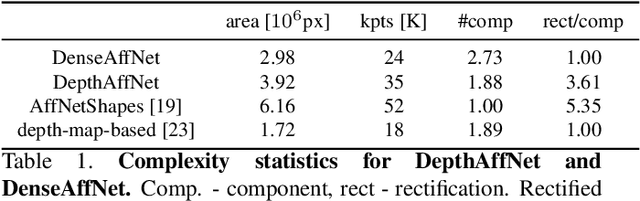
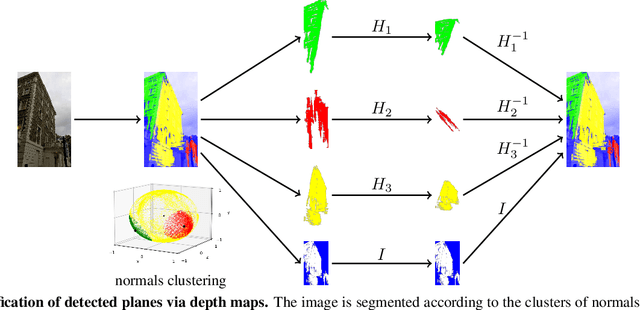

We consider the problem of two-view matching under significant viewpoint changes with view synthesis. We propose two novel methods, minimizing the view synthesis overhead. The first one, named DenseAffNet, uses dense affine shapes estimates from AffNet, which allows it to partition the image, rectifying each partition with just a single affine map. The second one, named DepthAffNet, combines information from depth maps and affine shapes estimates to produce different sets of rectifying affine maps for different image partitions. DenseAffNet is faster than the state-of-the-art and more accurate on generic scenes. DepthAffNet is on par with the state of the art on scenes containing large planes. The evaluation is performed on 3 public datasets - EVD Dataset, Strong ViewPoint Changes Dataset and IMC Phototourism Dataset.
OpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching
Apr 19, 2022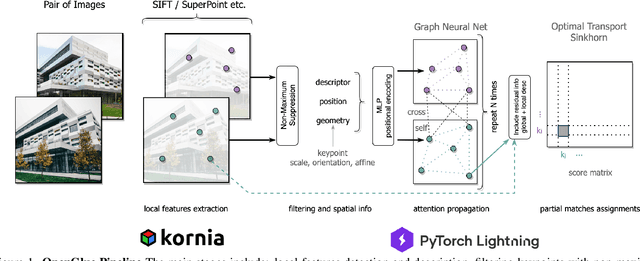
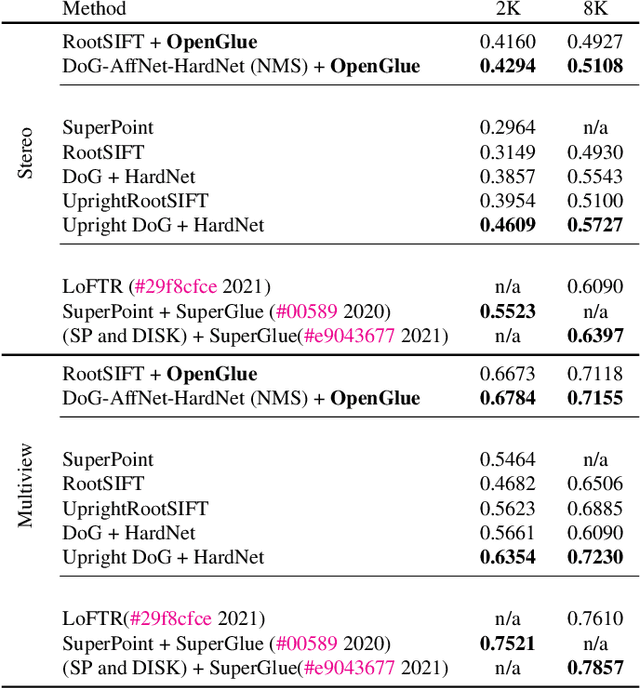
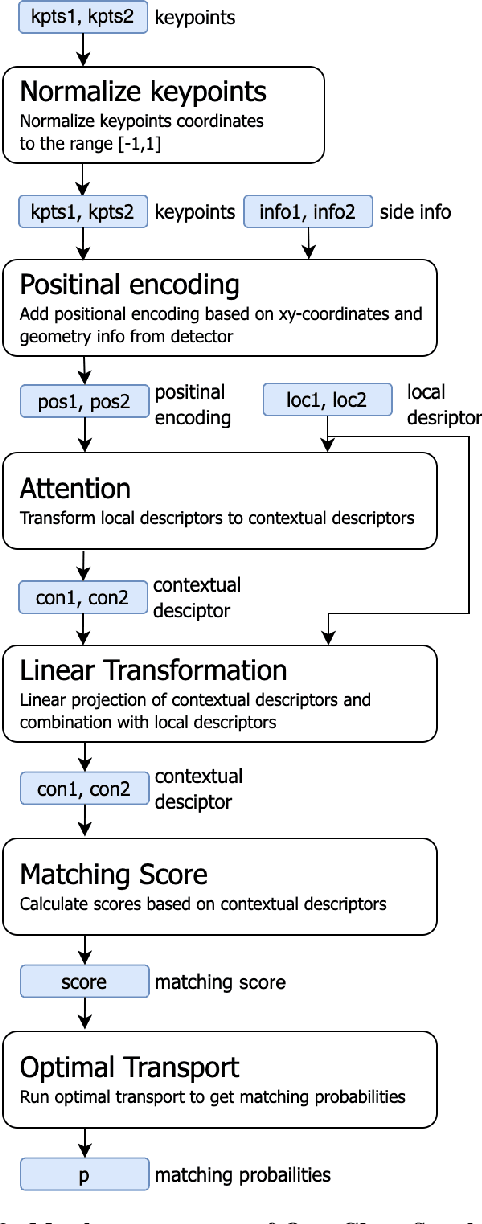
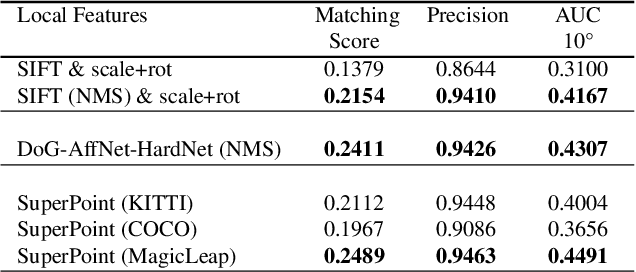
We present OpenGlue: a free open-source framework for image matching, that uses a Graph Neural Network-based matcher inspired by SuperGlue \cite{sarlin20superglue}. We show that including additional geometrical information, such as local feature scale, orientation, and affine geometry, when available (e.g. for SIFT features), significantly improves the performance of the OpenGlue matcher. We study the influence of the various attention mechanisms on accuracy and speed. We also present a simple architectural improvement by combining local descriptors with context-aware descriptors. The code and pretrained OpenGlue models for the different local features are publicly available.
Learning and Crafting for the Wide Multiple Baseline Stereo
Dec 22, 2021
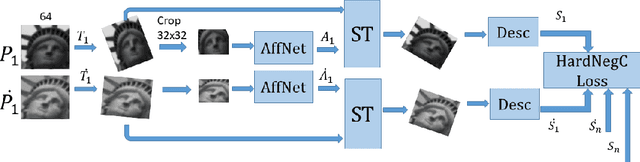
This thesis introduces the wide multiple baseline stereo (WxBS) problem. WxBS, a generalization of the standard wide baseline stereo problem, considers the matching of images that simultaneously differ in more than one image acquisition factor such as viewpoint, illumination, sensor type, or where object appearance changes significantly, e.g., over time. A new dataset with the ground truth, evaluation metric and baselines has been introduced. The thesis presents the following improvements of the WxBS pipeline. (i) A loss function, called HardNeg, for learning a local image descriptor that relies on hard negative mining within a mini-batch and on the maximization of the distance between the closest positive and the closest negative patches. (ii) The descriptor trained with the HardNeg loss, called HardNet, is compact and shows state-of-the-art performance in standard matching, patch verification and retrieval benchmarks. (iii) A method for learning the affine shape, orientation, and potentially other parameters related to geometric and appearance properties of local features. (iv) A tentative correspondences generation strategy which generalizes the standard first to second closest distance ratio is presented. The selection strategy, which shows performance superior to the standard method, is applicable to either hard-engineered descriptors like SIFT, LIOP, and MROGH or deeply learned like HardNet. (v) A feedback loop is introduced for the two-view matching problem, resulting in MODS -- matching with on-demand view synthesis -- algorithm. MODS is an algorithm that handles a viewing angle difference even larger than the previous state-of-the-art ASIFT algorithm, without a significant increase of computational cost over "standard" wide and narrow baseline approaches. Last, but not least, a comprehensive benchmark for local features and robust estimation algorithms is introduced.
HarrisZ$^+$: Harris Corner Selection for Next-Gen Image Matching Pipelines
Sep 29, 2021
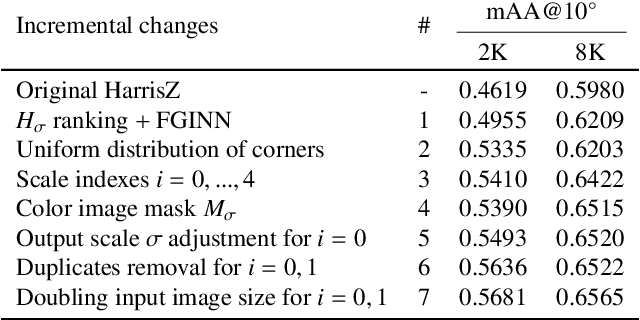


Due to its role in many computer vision tasks, image matching has been subjected to an active investigation by researchers, which has lead to better and more discriminant feature descriptors and to more robust matching strategies, also thanks to the advent of the deep learning and the increased computational power of the modern hardware. Despite of these achievements, the keypoint extraction process at the base of the image matching pipeline has not seen equivalent progresses. This paper presents Harrisz$^{+}$, an upgrade to the HarrisZ corner detector, optimized to synergically take advance of the recent improvements of the other steps of the image matching pipeline. Harrisz$^{+}$ does not only consists of a tuning of the setup parameters, but introduces further refinements to the selection criteria delineated by HarrisZ, so providing more, yet discriminative, keypoints, which are better distributed on the image and with higher localization accuracy. The image matching pipeline including Harrisz$^{+}$, together with the other modern components, obtained in different recent matching benchmarks state-of-the-art results among the classic image matching pipelines, closely following results of the more recent fully deep end-to-end trainable approaches.
Efficient Initial Pose-graph Generation for Global SfM
Nov 26, 2020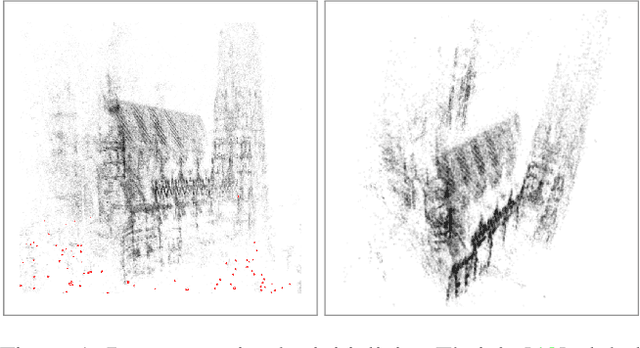

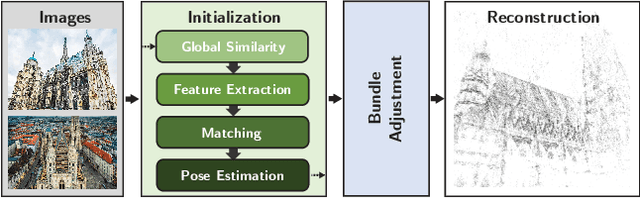
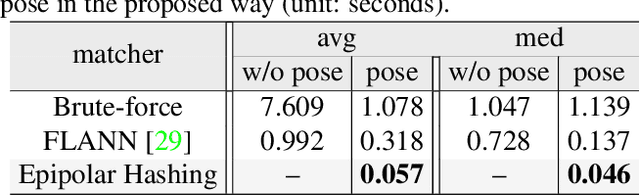
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made "light-weight" by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
Differentiable Data Augmentation with Kornia
Nov 19, 2020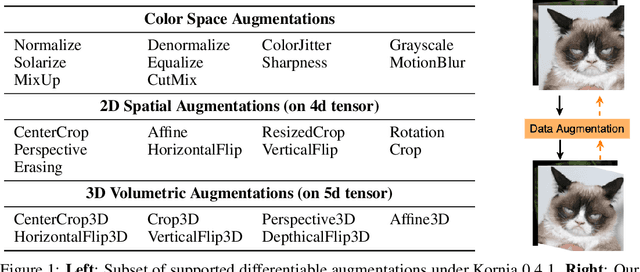
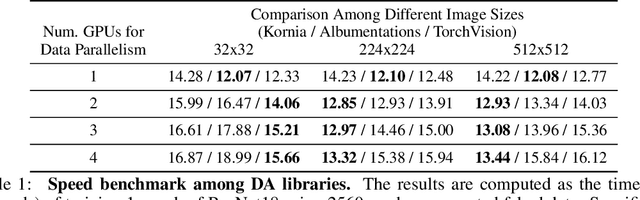
In this paper we present a review of the Kornia differentiable data augmentation (DDA) module for both for spatial (2D) and volumetric (3D) tensors. This module leverages differentiable computer vision solutions from Kornia, with an aim of integrating data augmentation (DA) pipelines and strategies to existing PyTorch components (e.g. autograd for differentiability, optim for optimization). In addition, we provide a benchmark comparing different DA frameworks and a short review for a number of approaches that make use of Kornia DDA.
ArXiving Before Submission Helps Everyone
Oct 11, 2020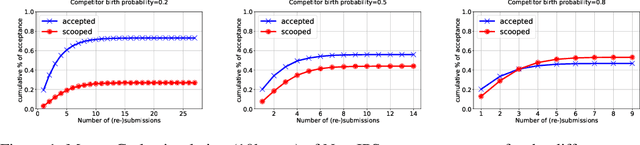
We claim, and present evidence, that allowing arXiv publication before a conference or journal submission benefits researchers, especially early career, as well as the whole scientific community. Specifically, arXiving helps professional identity building, protects against independent re-discovery, idea theft and gate-keeping; it facilitates open research result distribution and reduces inequality. The advantages dwarf the drawbacks -- mainly the relative increase in acceptance rate of papers of well-known authors -- which studies show to be marginal. Analyzing the pros and cons of arXiving papers, we conclude that requiring preprints be anonymous is nearly as detrimental as not allowing them. We see no reasons why anyone but the authors should decide whether to arXiv or not.