 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching
Apr 19, 2022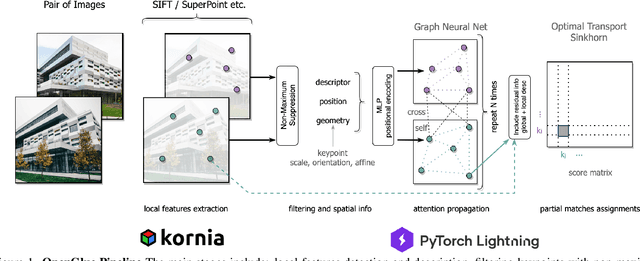
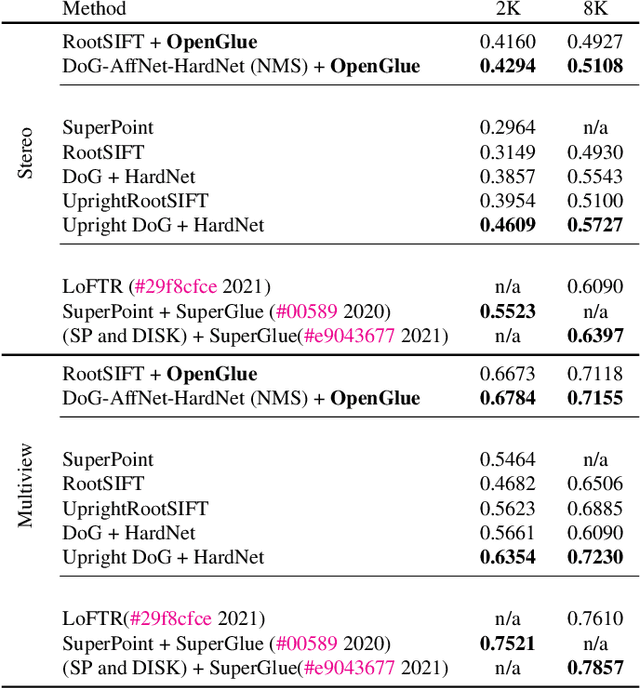
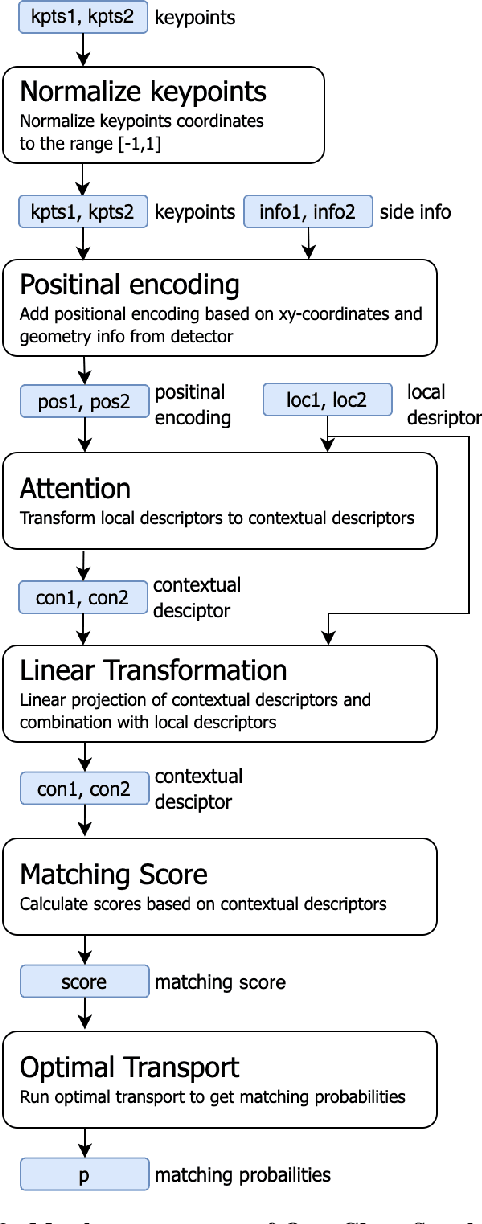
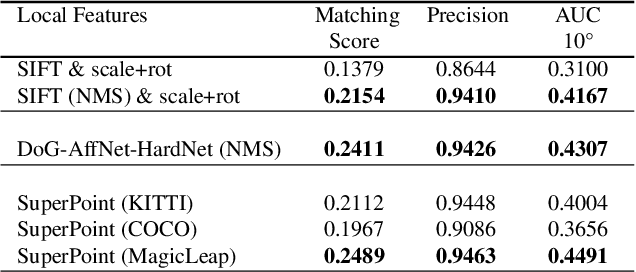
We present OpenGlue: a free open-source framework for image matching, that uses a Graph Neural Network-based matcher inspired by SuperGlue \cite{sarlin20superglue}. We show that including additional geometrical information, such as local feature scale, orientation, and affine geometry, when available (e.g. for SIFT features), significantly improves the performance of the OpenGlue matcher. We study the influence of the various attention mechanisms on accuracy and speed. We also present a simple architectural improvement by combining local descriptors with context-aware descriptors. The code and pretrained OpenGlue models for the different local features are publicly available.
Combining CNNs With Transformer for Multimodal 3D MRI Brain Tumor Segmentation With Self-Supervised Pretraining
Oct 15, 2021
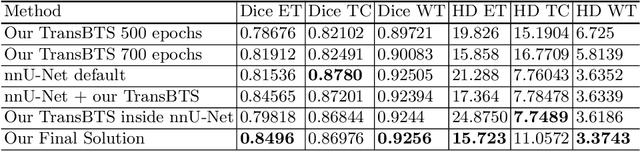
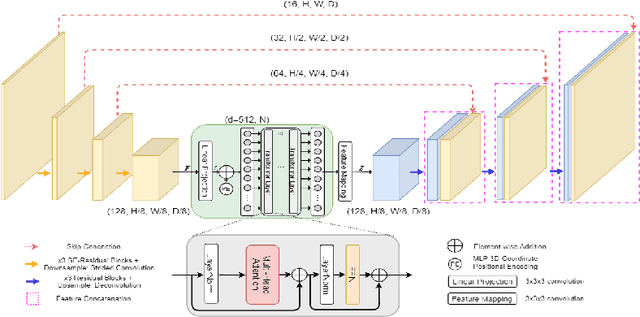
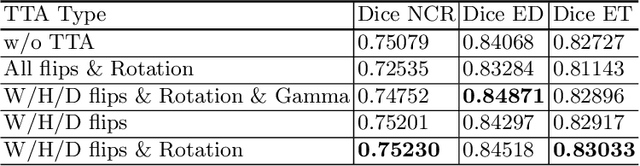
We apply an ensemble of modified TransBTS, nnU-Net, and a combination of both for the segmentation task of the BraTS 2021 challenge. In fact, we change the original architecture of the TransBTS model by adding Squeeze-and-Excitation blocks, an increasing number of CNN layers, replacing positional encoding in Transformer block with a learnable Multilayer Perceptron (MLP) embeddings, which makes Transformer adjustable to any input size during inference. With these modifications, we are able to largely improve TransBTS performance. Inspired by a nnU-Net framework we decided to combine it with our modified TransBTS by changing the architecture inside nnU-Net to our custom model. On the Validation set of BraTS 2021, the ensemble of these approaches achieves 0.8496, 0.8698, 0.9256 Dice score and 15.72, 11.057, 3.374 HD95 for enhancing tumor, tumor core, and whole tumor, correspondingly. Our code is publicly available.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020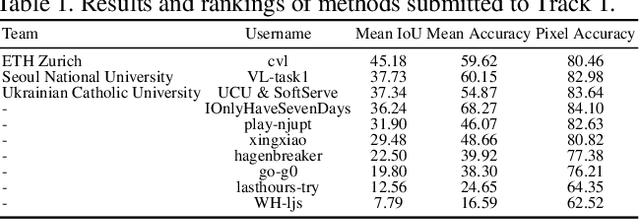
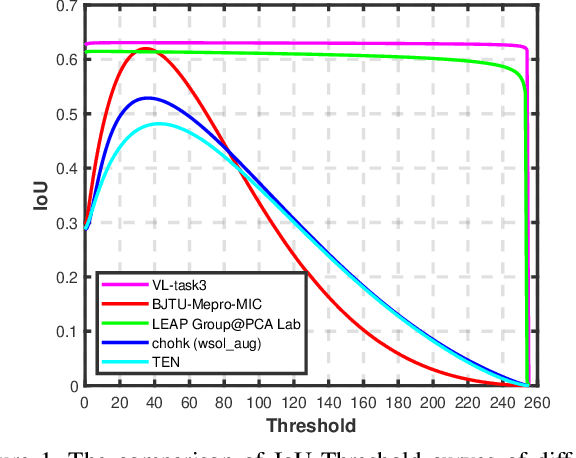

Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
Weakly-Supervised Segmentation for Disease Localization in Chest X-Ray Images
Jul 01, 2020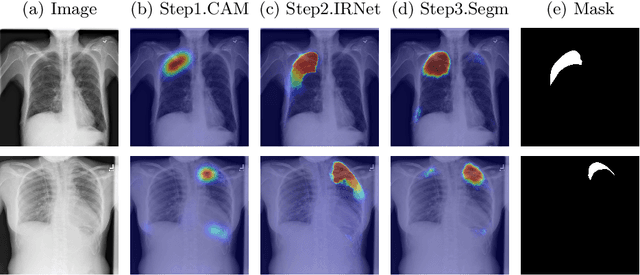

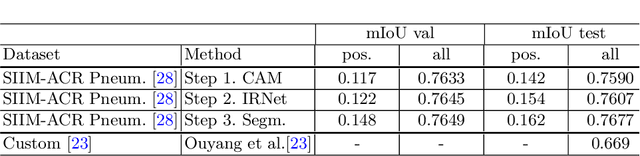
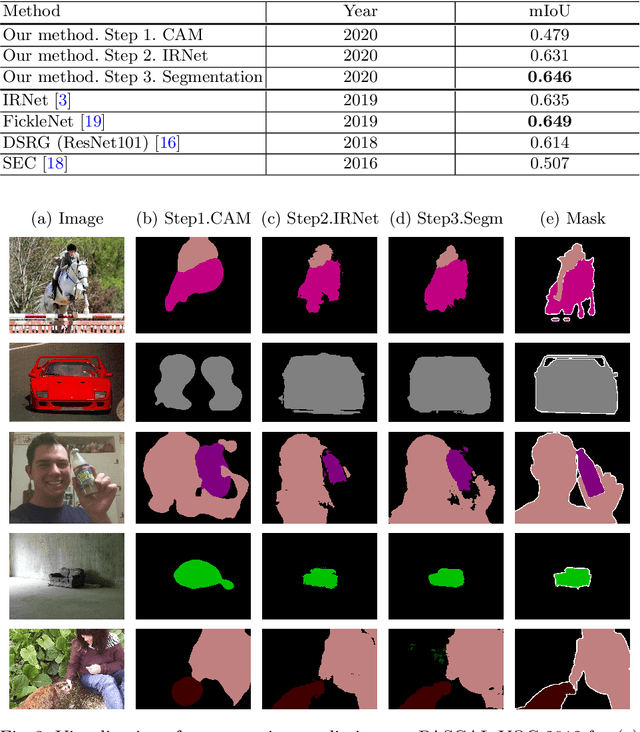
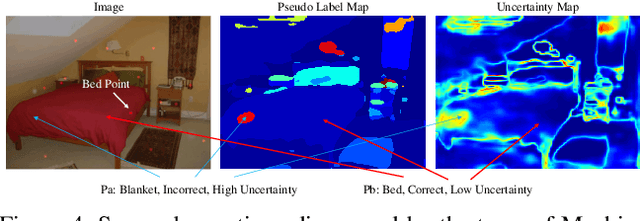
Deep Convolutional Neural Networks have proven effective in solving the task of semantic segmentation. However, their efficiency heavily relies on the pixel-level annotations that are expensive to get and often require domain expertise, especially in medical imaging. Weakly supervised semantic segmentation helps to overcome these issues and also provides explainable deep learning models. In this paper, we propose a novel approach to the semantic segmentation of medical chest X-ray images with only image-level class labels as supervision. We improve the disease localization accuracy by combining three approaches as consecutive steps. First, we generate pseudo segmentation labels of abnormal regions in the training images through a supervised classification model enhanced with a regularization procedure. The obtained activation maps are then post-processed and propagated into a second classification model-Inter-pixel Relation Network, which improves the boundaries between different object classes. Finally, the resulting pseudo-labels are used to train a proposed fully supervised segmentation model. We analyze the robustness of the presented method and test its performance on two distinct datasets: PASCAL VOC 2012 and SIIM-ACR Pneumothorax. We achieve significant results in the segmentation on both datasets using only image-level annotations. We show that this approach is applicable to chest X-rays for detecting an anomalous volume of air in the pleural space between the lung and the chest wall. Our code has been made publicly available.
NoPeopleAllowed: The Three-Step Approach to Weakly Supervised Semantic Segmentation
Jun 13, 2020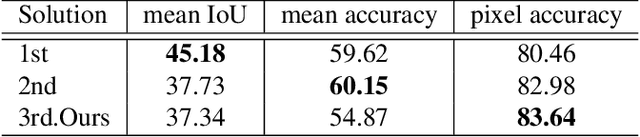


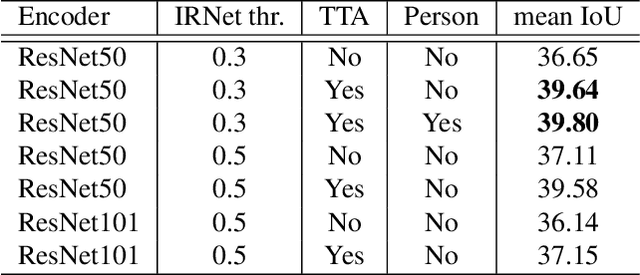
We propose a novel approach to weakly supervised semantic segmentation, which consists of three consecutive steps. The first two steps extract high-quality pseudo masks from image-level annotated data, which are then used to train a segmentation model on the third step. The presented approach also addresses two problems in the data: class imbalance and missing labels. Using only image-level annotations as supervision, our method is capable of segmenting various classes and complex objects. It achieves 37.34 mean IoU on the test set, placing 3rd at the LID Challenge in the task of weakly supervised semantic segmentation.
CNN-CASS: CNN for Classification of Coronary Artery Stenosis Score in MPR Images
Jan 23, 2020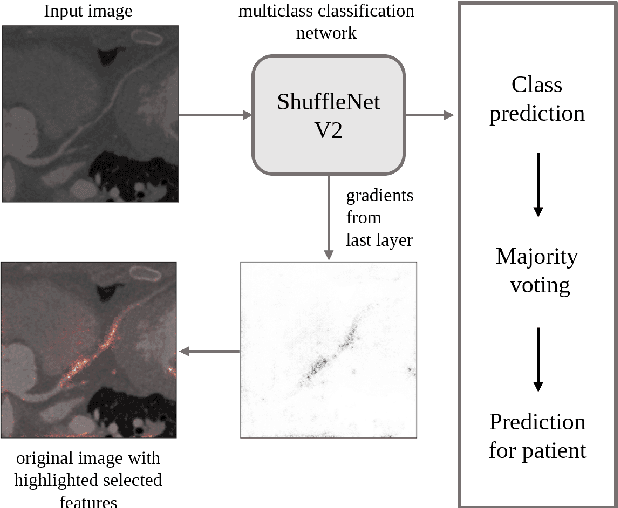
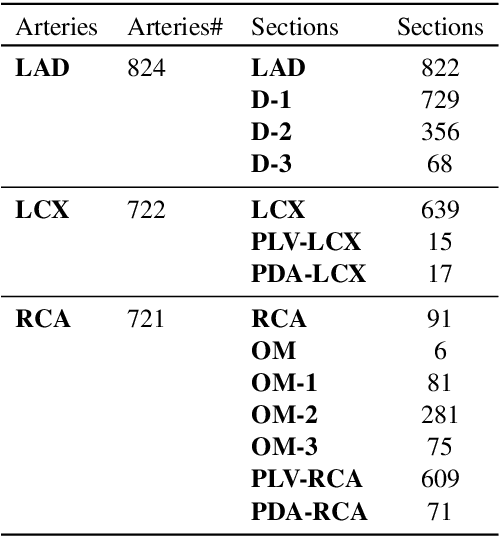


To decrease patient waiting time for diagnosis of the Coronary Artery Disease, automatic methods are applied to identify its severity using Coronary Computed Tomography Angiography scans or extracted Multiplanar Reconstruction (MPR) images, giving doctors a second-opinion on the priority of each case. The main disadvantage of previous studies is the lack of large set of data that could guarantee their reliability. Another limitation is the usage of handcrafted features requiring manual preprocessing, such as centerline extraction. We overcome both limitations by applying a different automated approach based on ShuffleNet V2 network architecture and testing it on the proposed collected dataset of MPR images, which is bigger than any other used in this field before. We also omit centerline extraction step and train and test our model using whole curved MPR images of 708 and 105 patients, respectively. The model predicts one of three classes: 'no stenosis' for normal, 'non-significant' - 1-50% of stenosis detected, 'significant' - more than 50% of stenosis. We demonstrate model's interpretability through visualization of the most important features selected by the network. For stenosis score classification, the method shows improved performance comparing to previous works, achieving 80% accuracy on the patient level. Our code is publicly available.