 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Modality Heterogeneity in Low-Bit Quantization for Large Vision-Language Models
May 19, 2026Low-bit post-training quantization (PTQ) is a pivotal technique for deploying Vision-Language Models (VLMs) on resource-constrained devices. However, existing PTQ methods often degrade VLMs' accuracy due to the heterogeneous activation distributions of text and vision modalities during quantization. We find that this cross-modal heterogeneity is distributed unevenly across channels: a small subset of channels contains most modality-specific outliers, and these outliers typically reside in different channels for each modality. Motivated by this, we propose SplitQ, a channel-Splitting-driven post-training Quantization framework. At its core, SplitQ introduces a novel Modality-specific Outlier Channel Decoupling (MOCD) module that effectively isolates salient modality-specific outlier channels with minimal overhead. To further address the remaining cross-modal distribution discrepancies, we design an Adaptive Cross-Modal Calibration (ACC) module that employs dual lightweight learnable branches to dynamically mitigate modality-induced quantization errors. Extensive experiments on popular VLMs demonstrate that SplitQ significantly outperforms existing approaches across 6 popular multi-modal datasets under all evaluated quantization settings, including W4A8, W4A4, W3A3, and W3A2. Notably, SplitQ preserves 93.5% of FP16 performance under the challenging W3A3 setting (69.5 vs. 74.3), pushing the efficiency frontier for deploying advanced VLMs. Our code is available at https://github.com/EMVision-NK/SplitQ
Video Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
EgoSound: Benchmarking Sound Understanding in Egocentric Videos
Feb 15, 2026Multimodal Large Language Models (MLLMs) have recently achieved remarkable progress in vision-language understanding. Yet, human perception is inherently multisensory, integrating sight, sound, and motion to reason about the world. Among these modalities, sound provides indispensable cues about spatial layout, off-screen events, and causal interactions, particularly in egocentric settings where auditory and visual signals are tightly coupled. To this end, we introduce EgoSound, the first benchmark designed to systematically evaluate egocentric sound understanding in MLLMs. EgoSound unifies data from Ego4D and EgoBlind, encompassing both sighted and sound-dependent experiences. It defines a seven-task taxonomy spanning intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning. Constructed through a multi-stage auto-generative pipeline, EgoSound contains 7315 validated QA pairs across 900 videos. Comprehensive experiments on nine state-of-the-art MLLMs reveal that current models exhibit emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding. EgoSound establishes a challenging foundation for advancing multisensory egocentric intelligence, bridging the gap between seeing and truly hearing the world.
DINO-Mix: Distilling Foundational Knowledge with Cross-Domain CutMix for Semi-supervised Class-imbalanced Medical Image Segmentation
Feb 08, 2026Semi-supervised learning (SSL) has emerged as a critical paradigm for medical image segmentation, mitigating the immense cost of dense annotations. However, prevailing SSL frameworks are fundamentally "inward-looking", recycling information and biases solely from within the target dataset. This design triggers a vicious cycle of confirmation bias under class imbalance, leading to the catastrophic failure to recognize minority classes. To dismantle this systemic issue, we propose a paradigm shift to a multi-level "outward-looking" framework. Our primary innovation is Foundational Knowledge Distillation (FKD), which looks outward beyond the confines of medical imaging by introducing a pre-trained visual foundation model, DINOv3, as an unbiased external semantic teacher. Instead of trusting the student's biased high confidence, our method distills knowledge from DINOv3's robust understanding of high semantic uniqueness, providing a stable, cross-domain supervisory signal that anchors the learning of minority classes. To complement this core strategy, we further look outward within the data by proposing Progressive Imbalance-aware CutMix (PIC), which creates a dynamic curriculum that adaptively forces the model to focus on minority classes in both labeled and unlabeled subsets. This layered strategy forms our framework, DINO-Mix, which breaks the vicious cycle of bias and achieves remarkable performance on challenging semi-supervised class-imbalanced medical image segmentation benchmarks Synapse and AMOS.
Revisiting Adaptive Rounding with Vectorized Reparameterization for LLM Quantization
Feb 02, 2026Adaptive Rounding has emerged as an alternative to round-to-nearest (RTN) for post-training quantization by enabling cross-element error cancellation. Yet, dense and element-wise rounding matrices are prohibitively expensive for billion-parameter large language models (LLMs). We revisit adaptive rounding from an efficiency perspective and propose VQRound, a parameter-efficient optimization framework that reparameterizes the rounding matrix into a compact codebook. Unlike low-rank alternatives, VQRound minimizes the element-wise worst-case error under $L_\infty$ norm, which is critical for handling heavy-tailed weight distributions in LLMs. Beyond reparameterization, we identify rounding initialization as a decisive factor and develop a lightweight end-to-end finetuning pipeline that optimizes codebooks across all layers using only 128 samples. Extensive experiments on OPT, LLaMA, LLaMA2, and Qwen3 models demonstrate that VQRound achieves better convergence than traditional adaptive rounding at the same number of steps while using as little as 0.2% of the trainable parameters. Our results show that adaptive rounding can be made both scalable and fast-fitting. The code is available at https://github.com/zhoustan/VQRound.
HiM2SAM: Enhancing SAM2 with Hierarchical Motion Estimation and Memory Optimization towards Long-term Tracking
Jul 10, 2025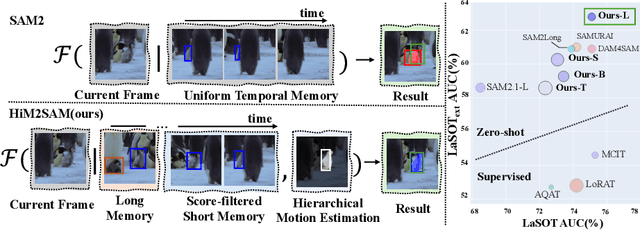
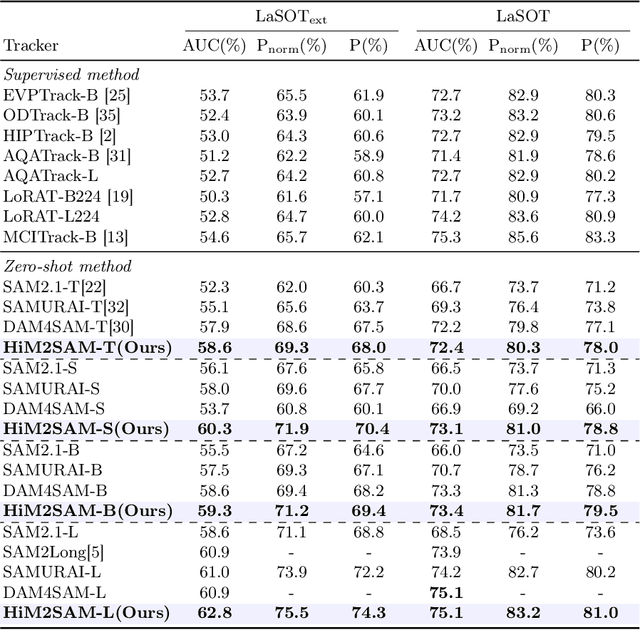
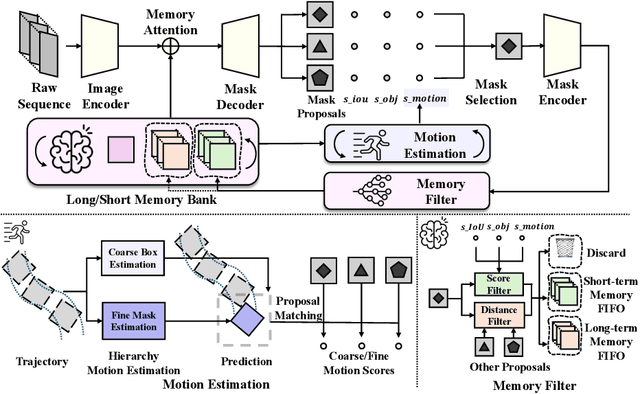
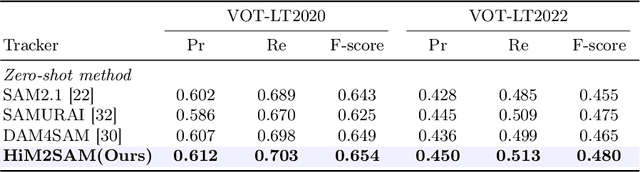
This paper presents enhancements to the SAM2 framework for video object tracking task, addressing challenges such as occlusions, background clutter, and target reappearance. We introduce a hierarchical motion estimation strategy, combining lightweight linear prediction with selective non-linear refinement to improve tracking accuracy without requiring additional training. In addition, we optimize the memory bank by distinguishing long-term and short-term memory frames, enabling more reliable tracking under long-term occlusions and appearance changes. Experimental results show consistent improvements across different model scales. Our method achieves state-of-the-art performance on LaSOT and LaSOText with the large model, achieving 9.6% and 7.2% relative improvements in AUC over the original SAM2, and demonstrates even larger relative gains on smaller models, highlighting the effectiveness of our trainless, low-overhead improvements for boosting long-term tracking performance. The code is available at https://github.com/LouisFinner/HiM2SAM.
A Comprehensive Survey on Video Scene Parsing:Advances, Challenges, and Prospects
Jun 16, 2025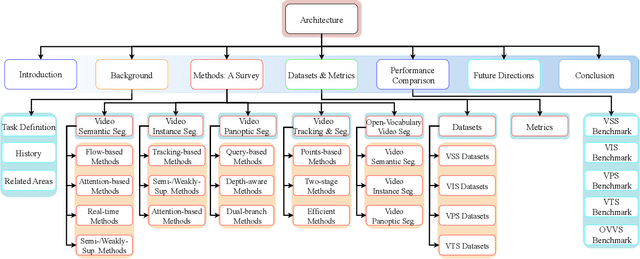



Video Scene Parsing (VSP) has emerged as a cornerstone in computer vision, facilitating the simultaneous segmentation, recognition, and tracking of diverse visual entities in dynamic scenes. In this survey, we present a holistic review of recent advances in VSP, covering a wide array of vision tasks, including Video Semantic Segmentation (VSS), Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), as well as Video Tracking and Segmentation (VTS), and Open-Vocabulary Video Segmentation (OVVS). We systematically analyze the evolution from traditional hand-crafted features to modern deep learning paradigms -- spanning from fully convolutional networks to the latest transformer-based architectures -- and assess their effectiveness in capturing both local and global temporal contexts. Furthermore, our review critically discusses the technical challenges, ranging from maintaining temporal consistency to handling complex scene dynamics, and offers a comprehensive comparative study of datasets and evaluation metrics that have shaped current benchmarking standards. By distilling the key contributions and shortcomings of state-of-the-art methodologies, this survey highlights emerging trends and prospective research directions that promise to further elevate the robustness and adaptability of VSP in real-world applications.
Exploiting Temporal State Space Sharing for Video Semantic Segmentation
Mar 26, 2025Video semantic segmentation (VSS) plays a vital role in understanding the temporal evolution of scenes. Traditional methods often segment videos frame-by-frame or in a short temporal window, leading to limited temporal context, redundant computations, and heavy memory requirements. To this end, we introduce a Temporal Video State Space Sharing (TV3S) architecture to leverage Mamba state space models for temporal feature sharing. Our model features a selective gating mechanism that efficiently propagates relevant information across video frames, eliminating the need for a memory-heavy feature pool. By processing spatial patches independently and incorporating shifted operation, TV3S supports highly parallel computation in both training and inference stages, which reduces the delay in sequential state space processing and improves the scalability for long video sequences. Moreover, TV3S incorporates information from prior frames during inference, achieving long-range temporal coherence and superior adaptability to extended sequences. Evaluations on the VSPW and Cityscapes datasets reveal that our approach outperforms current state-of-the-art methods, establishing a new standard for VSS with consistent results across long video sequences. By achieving a good balance between accuracy and efficiency, TV3S shows a significant advancement in spatiotemporal modeling, paving the way for efficient video analysis. The code is publicly available at https://github.com/Ashesham/TV3S.git.
CamSAM2: Segment Anything Accurately in Camouflaged Videos
Mar 26, 2025Video camouflaged object segmentation (VCOS), aiming at segmenting camouflaged objects that seamlessly blend into their environment, is a fundamental vision task with various real-world applications. With the release of SAM2, video segmentation has witnessed significant progress. However, SAM2's capability of segmenting camouflaged videos is suboptimal, especially when given simple prompts such as point and box. To address the problem, we propose Camouflaged SAM2 (CamSAM2), which enhances SAM2's ability to handle camouflaged scenes without modifying SAM2's parameters. Specifically, we introduce a decamouflaged token to provide the flexibility of feature adjustment for VCOS. To make full use of fine-grained and high-resolution features from the current frame and previous frames, we propose implicit object-aware fusion (IOF) and explicit object-aware fusion (EOF) modules, respectively. Object prototype generation (OPG) is introduced to abstract and memorize object prototypes with informative details using high-quality features from previous frames. Extensive experiments are conducted to validate the effectiveness of our approach. While CamSAM2 only adds negligible learnable parameters to SAM2, it substantially outperforms SAM2 on three VCOS datasets, especially achieving 12.2 mDice gains with click prompt on MoCA-Mask and 19.6 mDice gains with mask prompt on SUN-SEG-Hard, with Hiera-T as the backbone. The code will be available at https://github.com/zhoustan/CamSAM2.
Generalized Few-shot 3D Point Cloud Segmentation with Vision-Language Model
Mar 20, 2025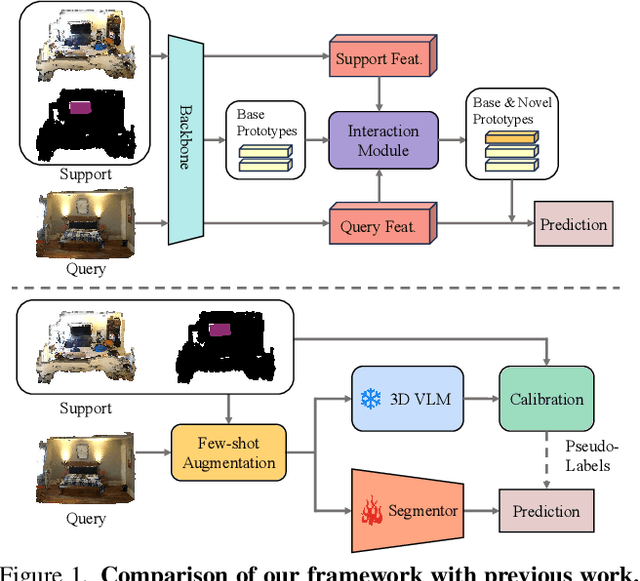
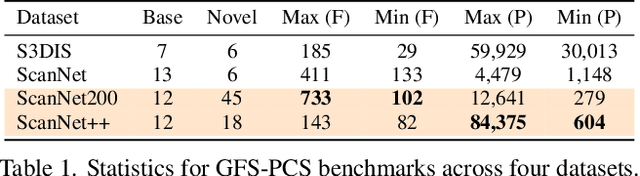
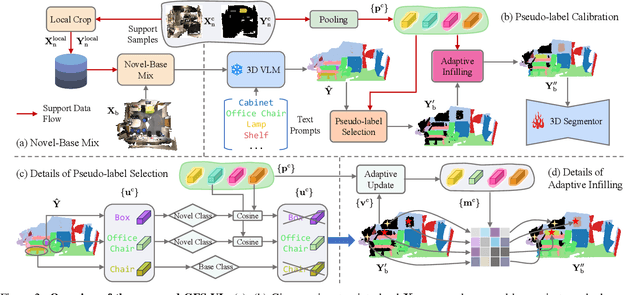
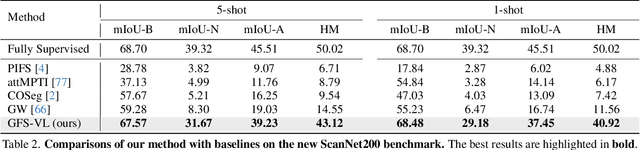
Generalized few-shot 3D point cloud segmentation (GFS-PCS) adapts models to new classes with few support samples while retaining base class segmentation. Existing GFS-PCS methods enhance prototypes via interacting with support or query features but remain limited by sparse knowledge from few-shot samples. Meanwhile, 3D vision-language models (3D VLMs), generalizing across open-world novel classes, contain rich but noisy novel class knowledge. In this work, we introduce a GFS-PCS framework that synergizes dense but noisy pseudo-labels from 3D VLMs with precise yet sparse few-shot samples to maximize the strengths of both, named GFS-VL. Specifically, we present a prototype-guided pseudo-label selection to filter low-quality regions, followed by an adaptive infilling strategy that combines knowledge from pseudo-label contexts and few-shot samples to adaptively label the filtered, unlabeled areas. Additionally, we design a novel-base mix strategy to embed few-shot samples into training scenes, preserving essential context for improved novel class learning. Moreover, recognizing the limited diversity in current GFS-PCS benchmarks, we introduce two challenging benchmarks with diverse novel classes for comprehensive generalization evaluation. Experiments validate the effectiveness of our framework across models and datasets. Our approach and benchmarks provide a solid foundation for advancing GFS-PCS in the real world. The code is at https://github.com/ZhaochongAn/GFS-VL