 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiM2SAM: Enhancing SAM2 with Hierarchical Motion Estimation and Memory Optimization towards Long-term Tracking
Jul 10, 2025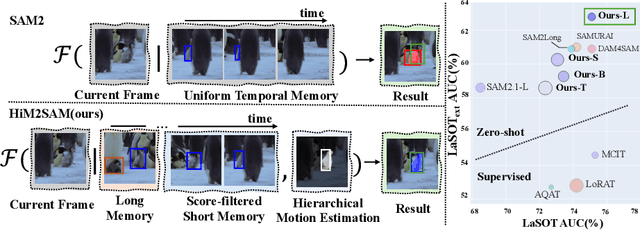
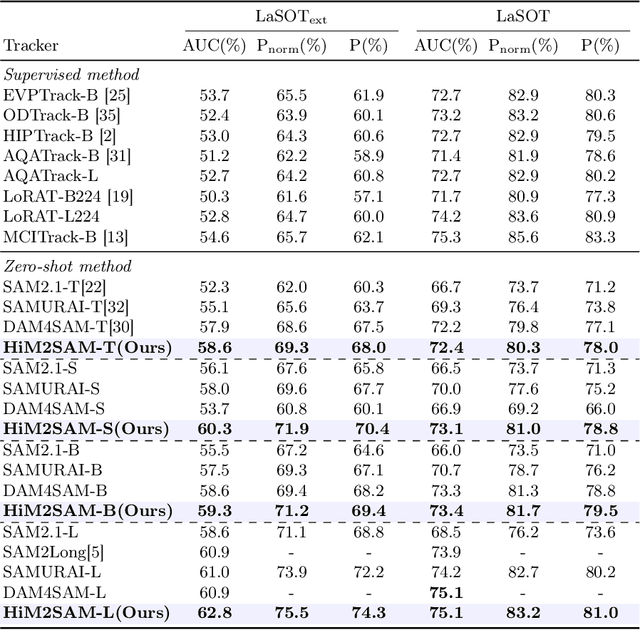
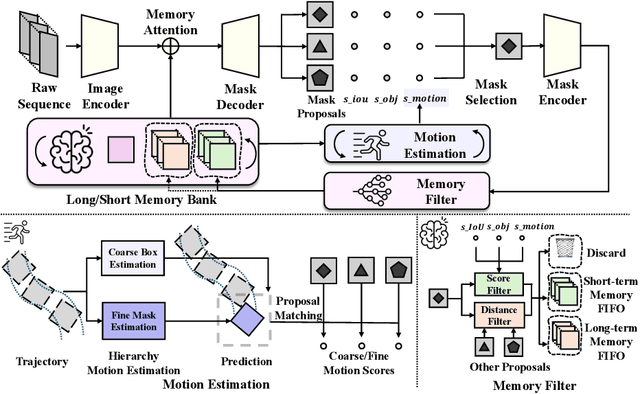
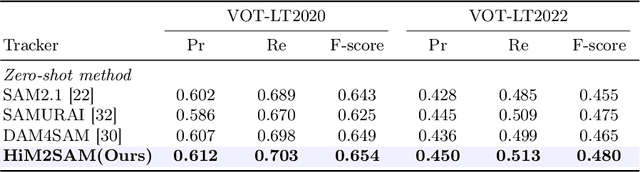
This paper presents enhancements to the SAM2 framework for video object tracking task, addressing challenges such as occlusions, background clutter, and target reappearance. We introduce a hierarchical motion estimation strategy, combining lightweight linear prediction with selective non-linear refinement to improve tracking accuracy without requiring additional training. In addition, we optimize the memory bank by distinguishing long-term and short-term memory frames, enabling more reliable tracking under long-term occlusions and appearance changes. Experimental results show consistent improvements across different model scales. Our method achieves state-of-the-art performance on LaSOT and LaSOText with the large model, achieving 9.6% and 7.2% relative improvements in AUC over the original SAM2, and demonstrates even larger relative gains on smaller models, highlighting the effectiveness of our trainless, low-overhead improvements for boosting long-term tracking performance. The code is available at https://github.com/LouisFinner/HiM2SAM.
Fast inverse lithography based on a model-driven block stacking convolutional neural network
Dec 19, 2024In the realm of lithography, Optical Proximity Correction (OPC) is a crucial resolution enhancement technique that optimizes the transmission function of photomasks on a pixel-based to effectively counter Optical Proximity Effects (OPE). However, conventional pixel-based OPC methods often generate patterns that pose manufacturing challenges, thereby leading to the increased cost in practical scenarios. This paper presents a novel inverse lithographic approach to OPC, employing a model-driven, block stacking deep learning framework that expedites the generation of masks conducive to manufacturing. This method is founded on vector lithography modelling and streamlines the training process by eliminating the requirement for extensive labeled datasets. Furthermore, diversity of mask patterns is enhanced by employing a wave function collapse algorithm, which facilitates the random generation of a multitude of target patterns, therefore significantly expanding the range of mask paradigm. Numerical experiments have substantiated the efficacy of the proposed end-to-end approach, highlighting its superior capability to manage mask complexity within the context of advanced OPC lithography. This advancement is anticipated to enhance the feasibility and economic viability of OPC technology within actual manufacturing environments.
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
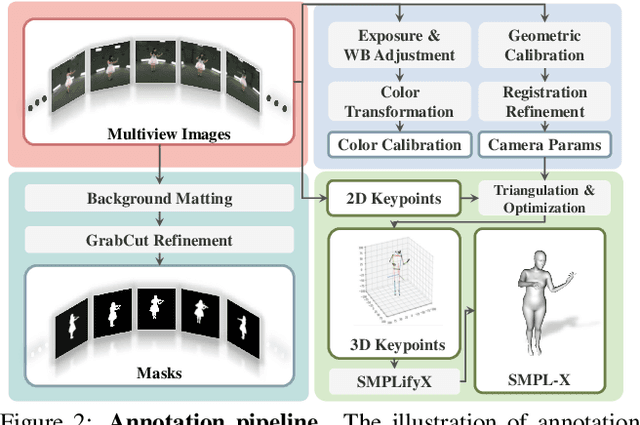
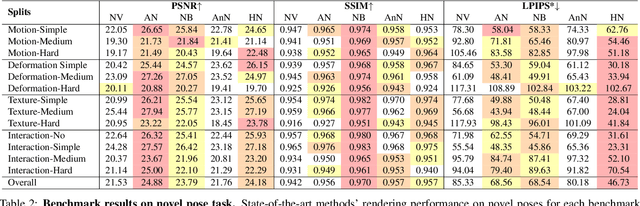

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/