 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Words -- Towards Native One-Vision Models at Scale
May 27, 2026Current vision-language models (VLMs) typically stitch together separate image encoders and language decoders via multi-stage alignment, a modular framework that inevitably fragments pixel-level signals across frames and scatters early pixel-word interactions. In parallel, native VLMs, despite impressive performance on single images, remain largely unexplored in multi-image, video understanding, and spatial intelligence. Hence, we introduce NEO-ov, a native foundation model that learns cross-frame and pixel-word correspondence end-to-end, without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, NEO-ov enables fine-grained and unified spatiotemporal modeling to emerge natively inside the model. Notably, NEO-ov largely narrows the gap to modular counterparts while excelling at fine-grained visual perception, validating that native "one-vision" architectures are not only feasible but competitive at scale. Beyond empirical performance, we unveil systematic architectural analyses and detailed training recipes to facilitate subsequent native multimodal modeling. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
Mar 19, 2026Prior motion generation largely follows two paradigms: continuous diffusion models that excel at kinematic control, and discrete token-based generators that are effective for semantic conditioning. To combine their strengths, we propose a three-stage framework comprising condition feature extraction (Perception), discrete token generation (Planning), and diffusion-based motion synthesis (Control). Central to this framework is MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from fine-grained reconstruction by delegating motion recovery to a diffusion decoder, enabling compact single-layer tokens while preserving motion fidelity. For kinematic conditions, coarse constraints guide token generation during planning, while fine-grained constraints are enforced during control through diffusion-based optimization. This design prevents kinematic details from disrupting semantic token planning. On HumanML3D, our method significantly improves controllability and fidelity over MaskControl while using only one-sixth of the tokens, reducing trajectory error from 0.72 cm to 0.08 cm and FID from 0.083 to 0.029. Unlike prior methods that degrade under stronger kinematic constraints, ours improves fidelity, reducing FID from 0.033 to 0.014.
Demystifing Video Reasoning
Mar 17, 2026Recent advances in video generation have revealed an unexpected phenomenon: diffusion-based video models exhibit non-trivial reasoning capabilities. Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames. In this work, we challenge this assumption and uncover a fundamentally different mechanism. We show that reasoning in video models instead primarily emerges along the diffusion denoising steps. Through qualitative analysis and targeted probing experiments, we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS). Beyond this core mechanism, we identify several emergent reasoning behaviors critical to model performance: (1) working memory, enabling persistent reference; (2) self-correction and enhancement, allowing recovery from incorrect intermediate solutions; and (3) perception before action, where early steps establish semantic grounding and later steps perform structured manipulation. During a diffusion step, we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations. Motivated by these insights, we present a simple training-free strategy as a proof-of-concept, demonstrating how reasoning can be improved by ensembling latent trajectories from identical models with different random seeds. Overall, our work provides a systematic understanding of how reasoning emerges in video generation models, offering a foundation to guide future research in better exploiting the inherent reasoning dynamics of video models as a new substrate for intelligence.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
VLM-Guided Group Preference Alignment for Diffusion-based Human Mesh Recovery
Feb 22, 2026Human mesh recovery (HMR) from a single RGB image is inherently ambiguous, as multiple 3D poses can correspond to the same 2D observation. Recent diffusion-based methods tackle this by generating various hypotheses, but often sacrifice accuracy. They yield predictions that are either physically implausible or drift from the input image, especially under occlusion or in cluttered, in-the-wild scenes. To address this, we introduce a dual-memory augmented HMR critique agent with self-reflection to produce context-aware quality scores for predicted meshes. These scores distill fine-grained cues about 3D human motion structure, physical feasibility, and alignment with the input image. We use these scores to build a group-wise HMR preference dataset. Leveraging this dataset, we propose a group preference alignment framework for finetuning diffusion-based HMR models. This process injects the rich preference signals into the model, guiding it to generate more physically plausible and image-consistent human meshes. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
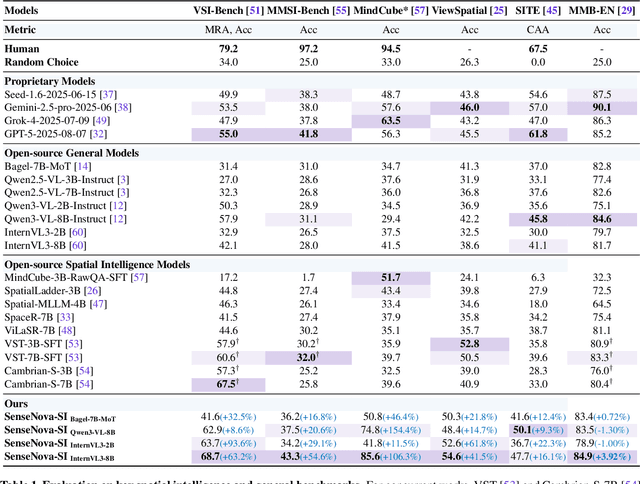


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
Oct 30, 2025Despite recent advances in 3D human motion generation (MoGen) on standard benchmarks, existing models still face a fundamental bottleneck in their generalization capability. In contrast, adjacent generative fields, most notably video generation (ViGen), have demonstrated remarkable generalization in modeling human behaviors, highlighting transferable insights that MoGen can leverage. Motivated by this observation, we present a comprehensive framework that systematically transfers knowledge from ViGen to MoGen across three key pillars: data, modeling, and evaluation. First, we introduce ViMoGen-228K, a large-scale dataset comprising 228,000 high-quality motion samples that integrates high-fidelity optical MoCap data with semantically annotated motions from web videos and synthesized samples generated by state-of-the-art ViGen models. The dataset includes both text-motion pairs and text-video-motion triplets, substantially expanding semantic diversity. Second, we propose ViMoGen, a flow-matching-based diffusion transformer that unifies priors from MoCap data and ViGen models through gated multimodal conditioning. To enhance efficiency, we further develop ViMoGen-light, a distilled variant that eliminates video generation dependencies while preserving strong generalization. Finally, we present MBench, a hierarchical benchmark designed for fine-grained evaluation across motion quality, prompt fidelity, and generalization ability. Extensive experiments show that our framework significantly outperforms existing approaches in both automatic and human evaluations. The code, data, and benchmark will be made publicly available.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025



Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
DPoser-X: Diffusion Model as Robust 3D Whole-body Human Pose Prior
Aug 01, 2025We present DPoser-X, a diffusion-based prior model for 3D whole-body human poses. Building a versatile and robust full-body human pose prior remains challenging due to the inherent complexity of articulated human poses and the scarcity of high-quality whole-body pose datasets. To address these limitations, we introduce a Diffusion model as body Pose prior (DPoser) and extend it to DPoser-X for expressive whole-body human pose modeling. Our approach unifies various pose-centric tasks as inverse problems, solving them through variational diffusion sampling. To enhance performance on downstream applications, we introduce a novel truncated timestep scheduling method specifically designed for pose data characteristics. We also propose a masked training mechanism that effectively combines whole-body and part-specific datasets, enabling our model to capture interdependencies between body parts while avoiding overfitting to specific actions. Extensive experiments demonstrate DPoser-X's robustness and versatility across multiple benchmarks for body, hand, face, and full-body pose modeling. Our model consistently outperforms state-of-the-art alternatives, establishing a new benchmark for whole-body human pose prior modeling.