 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Oct 31, 2025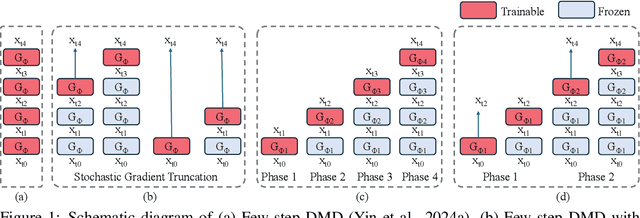

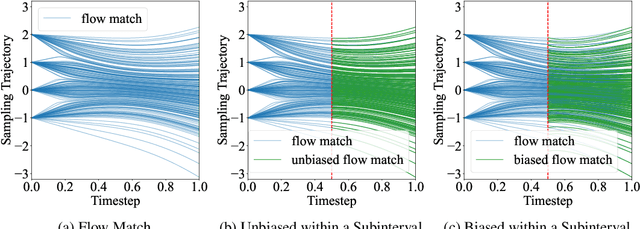
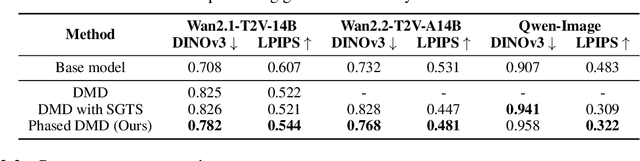
Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.
WHAC: World-grounded Humans and Cameras
Mar 19, 2024



Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.
Single-shot fringe projection profilometry based on Deep Learning and Computer Graphics
Jan 04, 2021

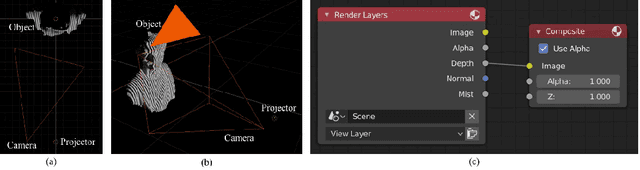
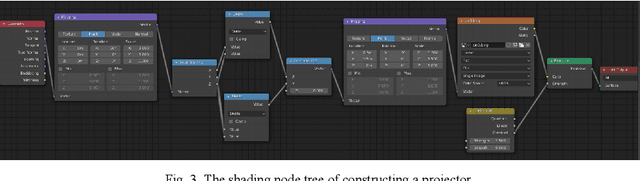
Multiple works have applied deep learning to fringe projection profilometry (FPP) in recent years. However, to obtain a large amount of data from actual systems for training is still a tricky problem, and moreover, the network design and optimization still worth exploring. In this paper, we introduce computer graphics to build virtual FPP systems in order to generate the desired datasets conveniently and simply. The way of constructing a virtual FPP system is described in detail firstly, and then some key factors to set the virtual FPP system much close to the reality are analyzed. With the aim of accurately estimating the depth image from only one fringe image, we also design a new loss function to enhance the quality of the overall and detailed information restored. And two representative networks, U-Net and pix2pix, are compared in multiple aspects. The real experiments prove the good accuracy and generalization of the network trained by the data from our virtual systems and the designed loss, implying the potential of our method for applications.