 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic-feature-guided 3D Object Detection
Apr 01, 2025



LiDAR-based 3D object detection is essential for autonomous driving systems. However, LiDAR point clouds may appear to have sparsity, uneven distribution, and incomplete structures, significantly limiting the detection performance. In road driving environments, target objects referring to vehicles, pedestrians and cyclists are well-suited for enhancing representation through the complete template guidance, considering their grid and topological structures. Therefore, this paper presents an intrinsic-feature-guided 3D object detection method based on a template-assisted feature enhancement module, which extracts intrinsic features from relatively generalized templates and provides rich structural information for foreground objects. Furthermore, a proposal-level contrastive learning mechanism is designed to enhance the feature differences between foreground and background objects. The proposed modules can act as plug-and-play components and improve the performance of multiple existing methods. Extensive experiments illustrate that the proposed method achieves the highly competitive detection results. Code will be available at https://github.com/zhangwanjingjj/IfgNet.git.
Detail-aware multi-view stereo network for depth estimation
Mar 31, 2025Multi-view stereo methods have achieved great success for depth estimation based on the coarse-to-fine depth learning frameworks, however, the existing methods perform poorly in recovering the depth of object boundaries and detail regions. To address these issues, we propose a detail-aware multi-view stereo network (DA-MVSNet) with a coarse-to-fine framework. The geometric depth clues hidden in the coarse stage are utilized to maintain the geometric structural relationships between object surfaces and enhance the expressive capability of image features. In addition, an image synthesis loss is employed to constrain the gradient flow for detailed regions and further strengthen the supervision of object boundaries and texture-rich areas. Finally, we propose an adaptive depth interval adjustment strategy to improve the accuracy of object reconstruction. Extensive experiments on the DTU and Tanks & Temples datasets demonstrate that our method achieves competitive results. The code is available at https://github.com/wsmtht520-/DAMVSNet.
Calibration of 3D Single-pixel Imaging Systems with a Calibration Field
Oct 10, 2024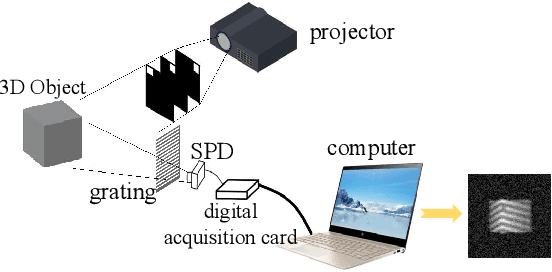
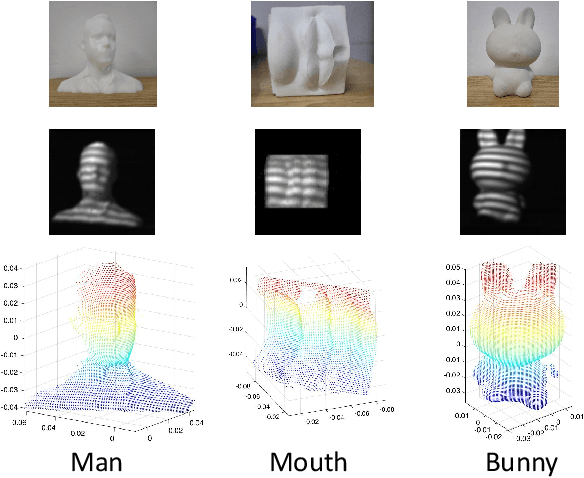

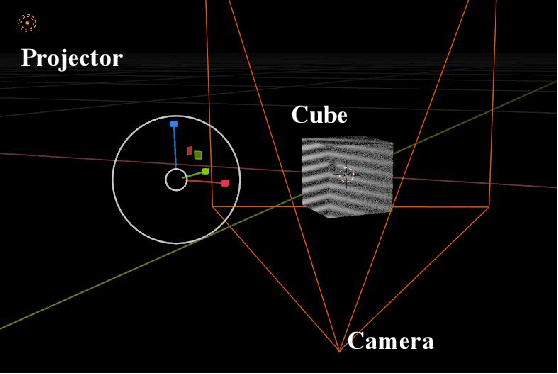
3D single-pixel imaging (SPI) is a promising imaging technique that can be ffexibly applied to various wavebands. The main challenge in 3D SPI is that the calibration usually requires a large number of standard points as references, which are tricky to capture using single-pixel detectors. Conventional solutions involve sophisticated device deployment and cumbersome operations, resulting in hundreds of images needed for calibration. In our work, we construct a Calibration Field (CaliF) to efffciently generate the standard points from one single image. A high accuracy of the CaliF is guaranteed by the technique of deep learning and digital twin. We perform experiments with our new method to verify its validity and accuracy. We believe our work holds great potential in 3D SPI systems or even general imaging systems.
Towards Effective Fusion and Forecasting of Multimodal Spatio-temporal Data for Smart Mobility
Jul 23, 2024


With the rapid development of location based services, multimodal spatio-temporal (ST) data including trajectories, transportation modes, traffic flow and social check-ins are being collected for deep learning based methods. These deep learning based methods learn ST correlations to support the downstream tasks in the fields such as smart mobility, smart city and other intelligent transportation systems. Despite their effectiveness, ST data fusion and forecasting methods face practical challenges in real-world scenarios. First, forecasting performance for ST data-insufficient area is inferior, making it necessary to transfer meta knowledge from heterogeneous area to enhance the sparse representations. Second, it is nontrivial to accurately forecast in multi-transportation-mode scenarios due to the fine-grained ST features of similar transportation modes, making it necessary to distinguish and measure the ST correlations to alleviate the influence caused by entangled ST features. At last, partial data modalities (e.g., transportation mode) are lost due to privacy or technical issues in certain scenarios, making it necessary to effectively fuse the multimodal sparse ST features and enrich the ST representations. To tackle these challenges, our research work aim to develop effective fusion and forecasting methods for multimodal ST data in smart mobility scenario. In this paper, we will introduce our recent works that investigates the challenges in terms of various real-world applications and establish the open challenges in this field for future work.
Kinematics-based 3D Human-Object Interaction Reconstruction from Single View
Jul 19, 2024



Reconstructing 3D human-object interaction (HOI) from single-view RGB images is challenging due to the absence of depth information and potential occlusions. Existing methods simply predict the body poses merely rely on network training on some indoor datasets, which cannot guarantee the rationality of the results if some body parts are invisible due to occlusions that appear easily. Inspired by the end-effector localization task in robotics, we propose a kinematics-based method that can drive the joints of human body to the human-object contact regions accurately. After an improved forward kinematics algorithm is proposed, the Multi-Layer Perceptron is introduced into the solution of inverse kinematics process to determine the poses of joints, which achieves precise results than the commonly-used numerical methods in robotics. Besides, a Contact Region Recognition Network (CRRNet) is also proposed to robustly determine the contact regions using a single-view video. Experimental results demonstrate that our method outperforms the state-of-the-art on benchmark BEHAVE. Additionally, our approach shows good portability and can be seamlessly integrated into other methods for optimizations.
3D Single-pixel imaging with active sampling patterns and learning based reconstruction
Sep 06, 2022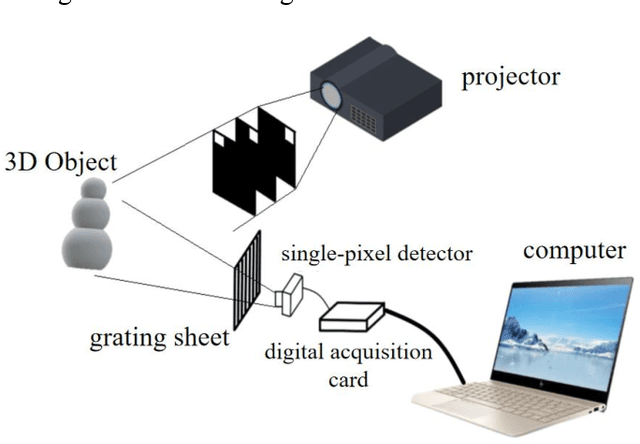
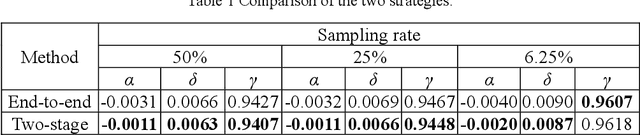

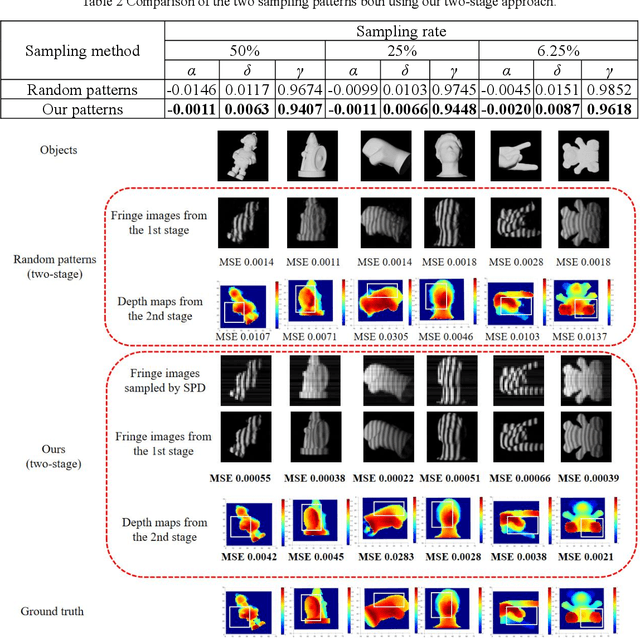
Single-pixel imaging (SPI) is significant for applications constrained by transmission bandwidth or lighting band, where 3D SPI can be further realized through capturing signals carrying depth. Sampling strategy and reconstruction algorithm are the key issues of SPI. Traditionally, random patterns are often adopted for sampling, but this blindly passive strategy requires a high sampling rate, and even so, it is difficult to develop a reconstruction algorithm that can maintain higher accuracy and robustness. In this paper, an active strategy is proposed to perform sampling with targeted scanning by designed patterns, from which the spatial information can be easily reordered well. Then, deep learning methods are introduced further to achieve 3D reconstruction, and the ability of deep learning to reconstruct desired information under low sampling rates are analyzed. Abundant experiments verify that our method improves the precision of SPI even if the sampling rate is very low, which has the potential to be extended flexibly in similar systems according to practical needs.
Fine-Grained Trajectory-based Travel Time Estimation for Multi-city Scenarios Based on Deep Meta-Learning
Jan 20, 2022

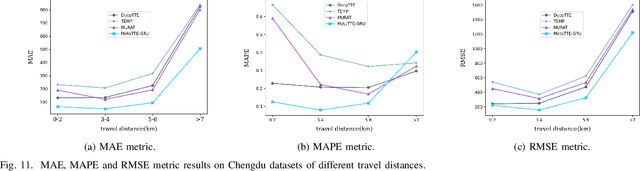

Travel Time Estimation (TTE) is indispensable in intelligent transportation system (ITS). It is significant to achieve the fine-grained Trajectory-based Travel Time Estimation (TTTE) for multi-city scenarios, namely to accurately estimate travel time of the given trajectory for multiple city scenarios. However, it faces great challenges due to complex factors including dynamic temporal dependencies and fine-grained spatial dependencies. To tackle these challenges, we propose a meta learning based framework, MetaTTE, to continuously provide accurate travel time estimation over time by leveraging well-designed deep neural network model called DED, which consists of Data preprocessing module and Encoder-Decoder network module. By introducing meta learning techniques, the generalization ability of MetaTTE is enhanced using small amount of examples, which opens up new opportunities to increase the potential of achieving consistent performance on TTTE when traffic conditions and road networks change over time in the future. The DED model adopts an encoder-decoder network to capture fine-grained spatial and temporal representations. Extensive experiments on two real-world datasets are conducted to confirm that our MetaTTE outperforms six state-of-art baselines, and improve 29.35% and 25.93% accuracy than the best baseline on Chengdu and Porto datasets, respectively.
STformer: A Noise-Aware Efficient Spatio-Temporal Transformer Architecture for Traffic Forecasting
Dec 06, 2021
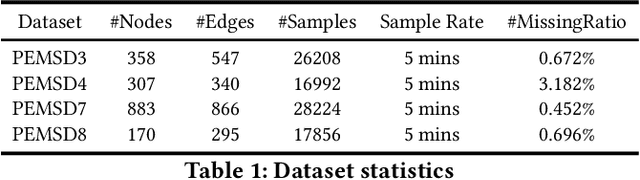

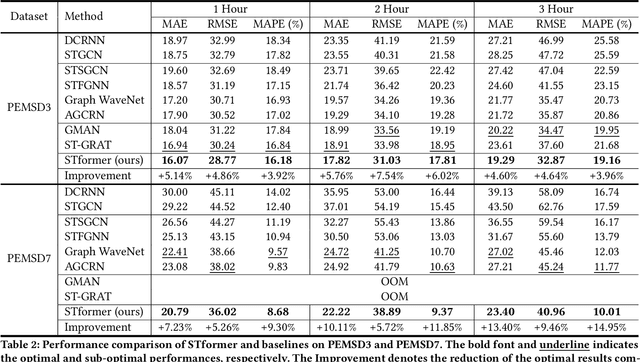
Traffic forecasting plays an indispensable role in the intelligent transportation system, which makes daily travel more convenient and safer. However, the dynamic evolution of spatio-temporal correlations makes accurate traffic forecasting very difficult. Existing work mainly employs graph neural netwroks (GNNs) and deep time series models (e.g., recurrent neural networks) to capture complex spatio-temporal patterns in the dynamic traffic system. For the spatial patterns, it is difficult for GNNs to extract the global spatial information, i.e., remote sensors information in road networks. Although we can use the self-attention to extract global spatial information as in the previous work, it is also accompanied by huge resource consumption. For the temporal patterns, traffic data have not only easy-to-recognize daily and weekly trends but also difficult-to-recognize short-term noise caused by accidents (e.g., car accidents and thunderstorms). Prior traffic models are difficult to distinguish intricate temporal patterns in time series and thus hard to get accurate temporal dependence. To address above issues, we propose a novel noise-aware efficient spatio-temporal Transformer architecture for accurate traffic forecasting, named STformer. STformer consists of two components, which are the noise-aware temporal self-attention (NATSA) and the graph-based sparse spatial self-attention (GBS3A). NATSA separates the high-frequency component and the low-frequency component from the time series to remove noise and capture stable temporal dependence by the learnable filter and the temporal self-attention, respectively. GBS3A replaces the full query in vanilla self-attention with the graph-based sparse query to decrease the time and memory usage. Experiments on four real-world traffic datasets show that STformer outperforms state-of-the-art baselines with lower computational cost.
CDGNet: A Cross-Time Dynamic Graph-based Deep Learning Model for Traffic Forecasting
Dec 06, 2021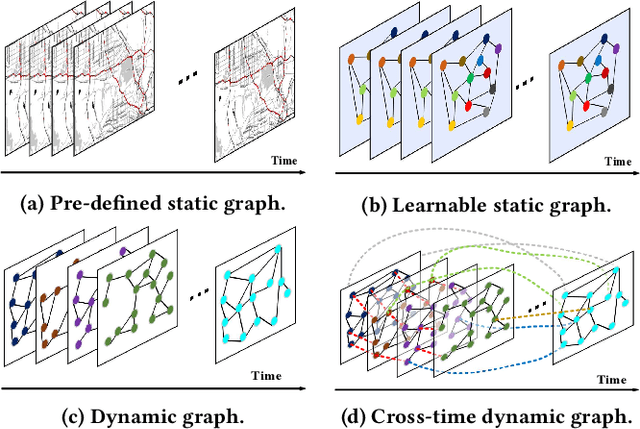
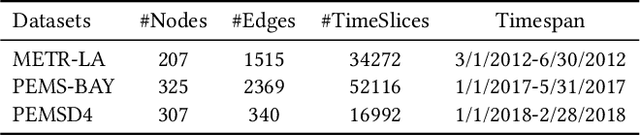
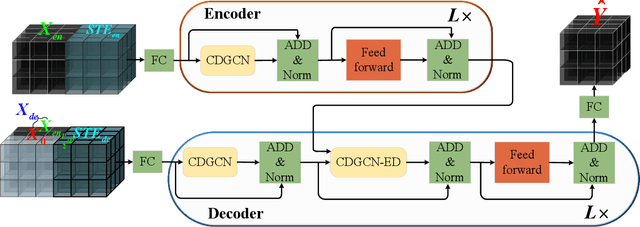
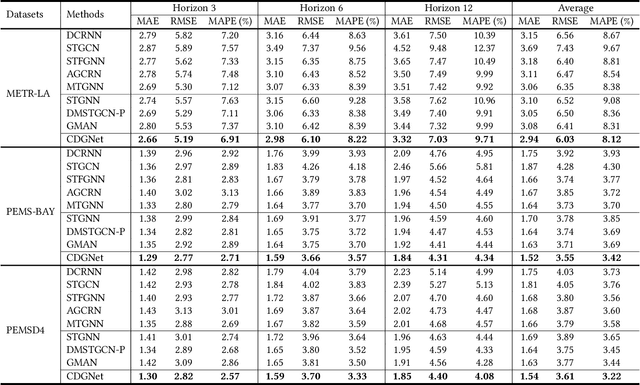
Traffic forecasting is important in intelligent transportation systems of webs and beneficial to traffic safety, yet is very challenging because of the complex and dynamic spatio-temporal dependencies in real-world traffic systems. Prior methods use the pre-defined or learnable static graph to extract spatial correlations. However, the static graph-based methods fail to mine the evolution of the traffic network. Researchers subsequently generate the dynamic graph for each time slice to reflect the changes of spatial correlations, but they follow the paradigm of independently modeling spatio-temporal dependencies, ignoring the cross-time spatial influence. In this paper, we propose a novel cross-time dynamic graph-based deep learning model, named CDGNet, for traffic forecasting. The model is able to effectively capture the cross-time spatial dependence between each time slice and its historical time slices by utilizing the cross-time dynamic graph. Meanwhile, we design a gating mechanism to sparse the cross-time dynamic graph, which conforms to the sparse spatial correlations in the real world. Besides, we propose a novel encoder-decoder architecture to incorporate the cross-time dynamic graph-based GCN for multi-step traffic forecasting. Experimental results on three real-world public traffic datasets demonstrate that CDGNet outperforms the state-of-the-art baselines. We additionally provide a qualitative study to analyze the effectiveness of our architecture.
DMGCRN: Dynamic Multi-Graph Convolution Recurrent Network for Traffic Forecasting
Dec 04, 2021



Traffic forecasting is a problem of intelligent transportation systems (ITS) and crucial for individuals and public agencies. Therefore, researches pay great attention to deal with the complex spatio-temporal dependencies of traffic system for accurate forecasting. However, there are two challenges: 1) Most traffic forecasting studies mainly focus on modeling correlations of neighboring sensors and ignore correlations of remote sensors, e.g., business districts with similar spatio-temporal patterns; 2) Prior methods which use static adjacency matrix in graph convolutional networks (GCNs) are not enough to reflect the dynamic spatial dependence in traffic system. Moreover, fine-grained methods which use self-attention to model dynamic correlations of all sensors ignore hierarchical information in road networks and have quadratic computational complexity. In this paper, we propose a novel dynamic multi-graph convolution recurrent network (DMGCRN) to tackle above issues, which can model the spatial correlations of distance, the spatial correlations of structure, and the temporal correlations simultaneously. We not only use the distance-based graph to capture spatial information from nodes are close in distance but also construct a novel latent graph which encoded the structure correlations among roads to capture spatial information from nodes are similar in structure. Furthermore, we divide the neighbors of each sensor into coarse-grained regions, and dynamically assign different weights to each region at different times. Meanwhile, we integrate the dynamic multi-graph convolution network into the gated recurrent unit (GRU) to capture temporal dependence. Extensive experiments on three real-world traffic datasets demonstrate that our proposed algorithm outperforms state-of-the-art baselines.