 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Chinese and English Passive Sentences Dataset for Machine Translation
Mar 16, 2026Machine Translation (MT) evaluation has gone beyond metrics, towards more specific linguistic phenomena. Regarding English-Chinese language pairs, passive sentences are constructed and distributed differently due to language variation, thus need special attention in MT. This paper proposes a bidirectional multi-domain dataset of passive sentences, extracted from five Chinese-English parallel corpora and annotated automatically with structure labels according to human translation, and a test set with manually verified annotation. The dataset consists of 73,965 parallel sentence pairs (2,358,731 English words, 3,498,229 Chinese characters). We evaluate two state-of-the-art open-source MT systems with our dataset, and four commercial models with the test set. The results show that, unlike humans, models are more influenced by the voice of the source text rather than the general voice usage of the source language, and therefore tend to maintain the passive voice when translating a passive in either direction. However, models demonstrate some knowledge of the low frequency and predominantly negative context of Chinese passives, leading to higher voice consistency with human translators in English-to-Chinese translation than in Chinese-to-English translation. Commercial NMT models scored higher in metric evaluations, but LLMs showed a better ability to use diverse alternative translations. Datasets and annotation script will be shared upon request.
Calibration of 3D Single-pixel Imaging Systems with a Calibration Field
Oct 10, 2024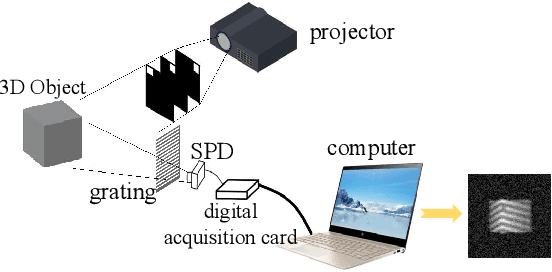
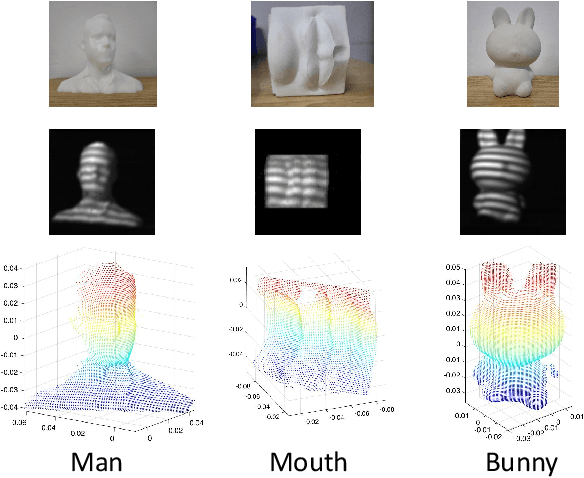

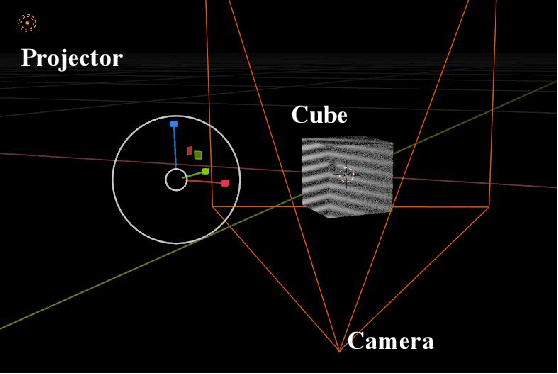
3D single-pixel imaging (SPI) is a promising imaging technique that can be ffexibly applied to various wavebands. The main challenge in 3D SPI is that the calibration usually requires a large number of standard points as references, which are tricky to capture using single-pixel detectors. Conventional solutions involve sophisticated device deployment and cumbersome operations, resulting in hundreds of images needed for calibration. In our work, we construct a Calibration Field (CaliF) to efffciently generate the standard points from one single image. A high accuracy of the CaliF is guaranteed by the technique of deep learning and digital twin. We perform experiments with our new method to verify its validity and accuracy. We believe our work holds great potential in 3D SPI systems or even general imaging systems.
REP: Resource-Efficient Prompting for On-device Continual Learning
Jun 07, 2024



On-device continual learning (CL) requires the co-optimization of model accuracy and resource efficiency to be practical. This is extremely challenging because it must preserve accuracy while learning new tasks with continuously drifting data and maintain both high energy and memory efficiency to be deployable on real-world devices. Typically, a CL method leverages one of two types of backbone networks: CNN or ViT. It is commonly believed that CNN-based CL excels in resource efficiency, whereas ViT-based CL is superior in model performance, making each option attractive only for a single aspect. In this paper, we revisit this comparison while embracing powerful pre-trained ViT models of various sizes, including ViT-Ti (5.8M parameters). Our detailed analysis reveals that many practical options exist today for making ViT-based methods more suitable for on-device CL, even when accuracy, energy, and memory are all considered. To further expand this impact, we introduce REP, which improves resource efficiency specifically targeting prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs throughout the training process. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing two novel algorithms-adaptive token merging (AToM) and adaptive layer dropping (ALD)-that optimize the prompt updating stage. In particular, AToM and ALD perform selective skipping across the data and model-layer dimensions without compromising task-specific features in vision transformer models. Extensive experiments on three image classification datasets validate REP's superior resource efficiency over current state-of-the-art methods.
Cost-effective On-device Continual Learning over Memory Hierarchy with Miro
Aug 17, 2023Continual learning (CL) trains NN models incrementally from a continuous stream of tasks. To remember previously learned knowledge, prior studies store old samples over a memory hierarchy and replay them when new tasks arrive. Edge devices that adopt CL to preserve data privacy are typically energy-sensitive and thus require high model accuracy while not compromising energy efficiency, i.e., cost-effectiveness. Our work is the first to explore the design space of hierarchical memory replay-based CL to gain insights into achieving cost-effectiveness on edge devices. We present Miro, a novel system runtime that carefully integrates our insights into the CL framework by enabling it to dynamically configure the CL system based on resource states for the best cost-effectiveness. To reach this goal, Miro also performs online profiling on parameters with clear accuracy-energy trade-offs and adapts to optimal values with low overhead. Extensive evaluations show that Miro significantly outperforms baseline systems we build for comparison, consistently achieving higher cost-effectiveness.
THUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
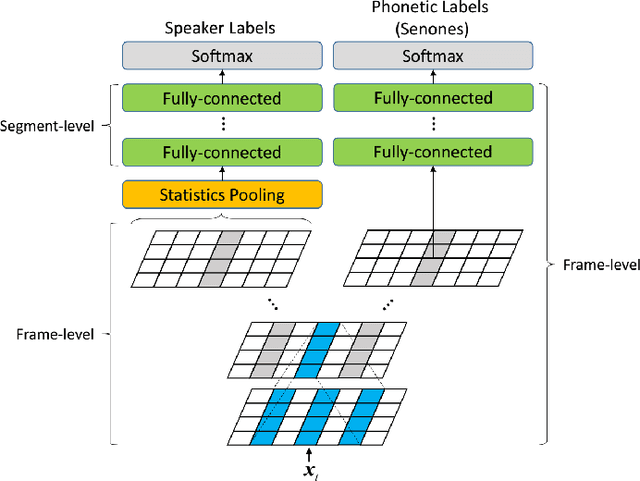
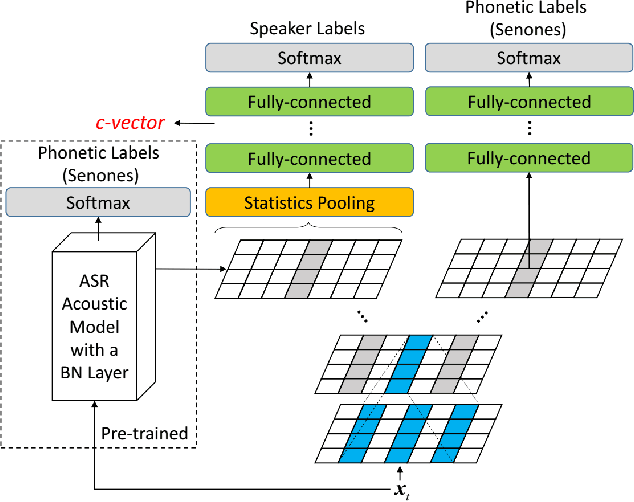

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
3D Single-pixel imaging with active sampling patterns and learning based reconstruction
Sep 06, 2022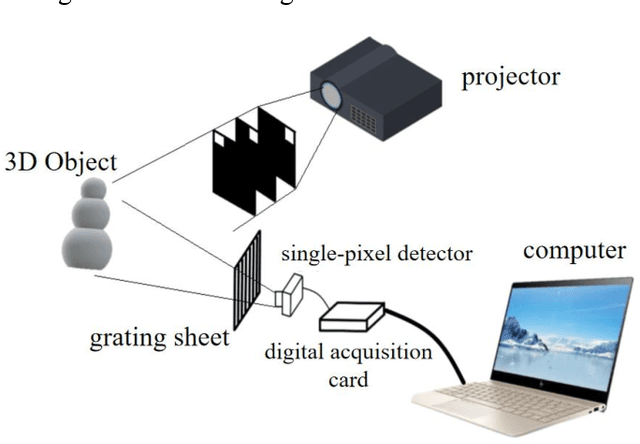
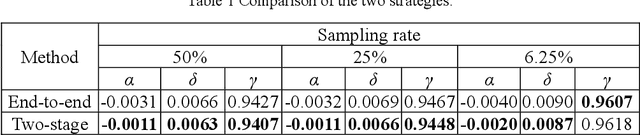

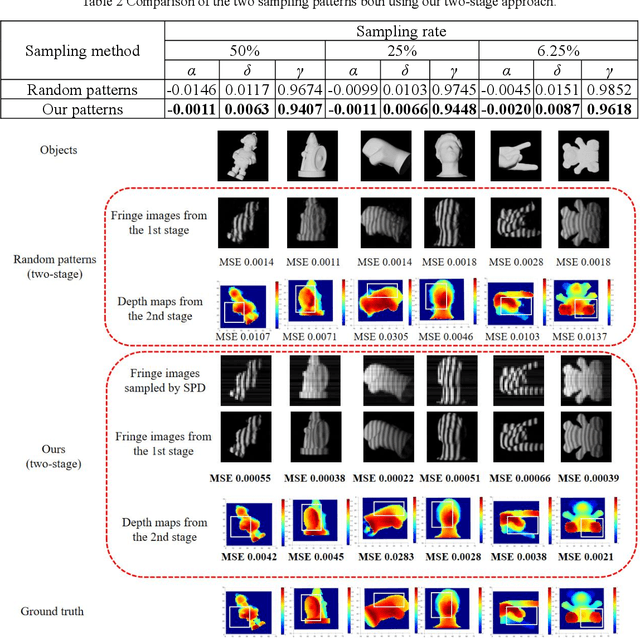
Single-pixel imaging (SPI) is significant for applications constrained by transmission bandwidth or lighting band, where 3D SPI can be further realized through capturing signals carrying depth. Sampling strategy and reconstruction algorithm are the key issues of SPI. Traditionally, random patterns are often adopted for sampling, but this blindly passive strategy requires a high sampling rate, and even so, it is difficult to develop a reconstruction algorithm that can maintain higher accuracy and robustness. In this paper, an active strategy is proposed to perform sampling with targeted scanning by designed patterns, from which the spatial information can be easily reordered well. Then, deep learning methods are introduced further to achieve 3D reconstruction, and the ability of deep learning to reconstruct desired information under low sampling rates are analyzed. Abundant experiments verify that our method improves the precision of SPI even if the sampling rate is very low, which has the potential to be extended flexibly in similar systems according to practical needs.