 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
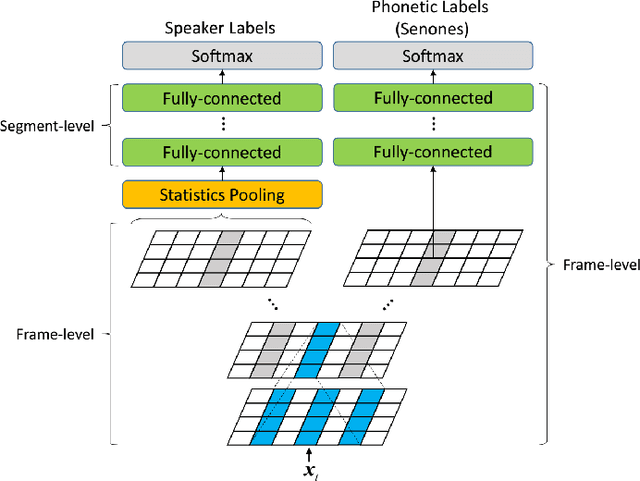
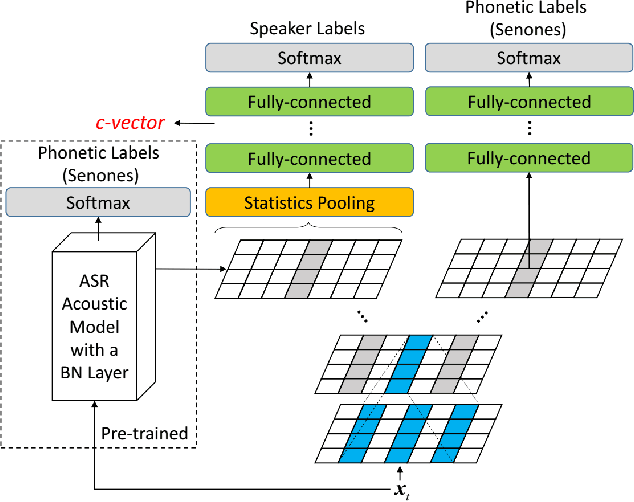

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
Rep Works in Speaker Verification
Oct 19, 2021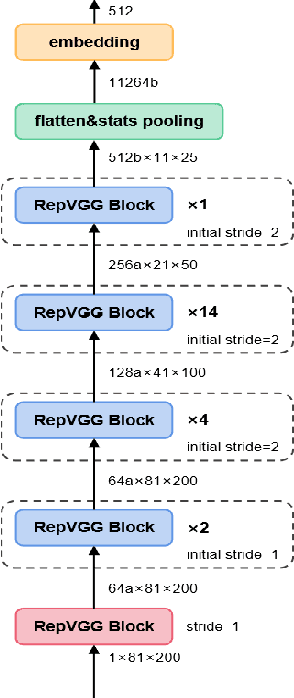
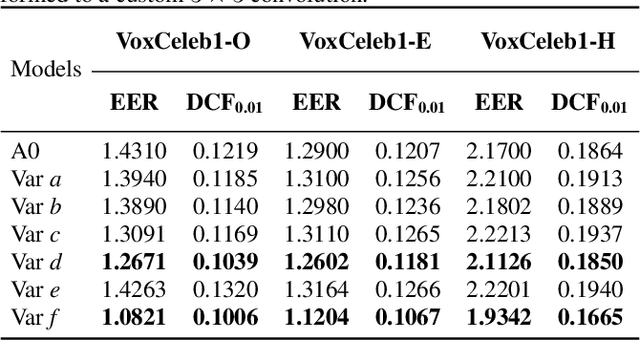
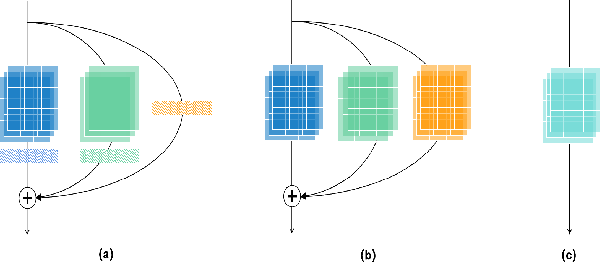
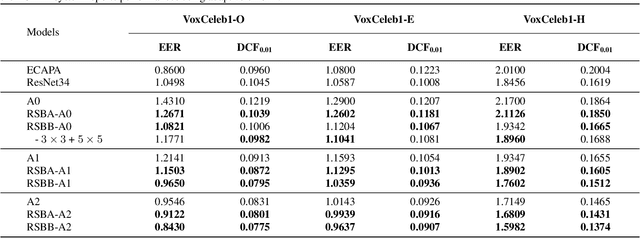
Multi-branch convolutional neural network architecture has raised lots of attention in speaker verification since the aggregation of multiple parallel branches can significantly improve performance. However, this design is not efficient enough during the inference time due to the increase of model parameters and extra operations. In this paper, we present a new multi-branch network architecture RepSPKNet that uses a re-parameterization technique. With this technique, our backbone model contains an efficient VGG-like inference state while its training state is a complicated multi-branch structure. We first introduce the specific structure of RepVGG into speaker verification and propose several variants of this structure. The performance is evaluated on VoxCeleb-based test sets. We demonstrate that both the branch diversity and the branch capacity play important roles in RepSPKNet designing. Our RepSPKNet achieves state-of-the-art performance with a 1.5982% EER and a 0.1374 minDCF on VoxCeleb1-H.
Multi-query multi-head attention pooling and Inter-topK penalty for speaker verification
Oct 12, 2021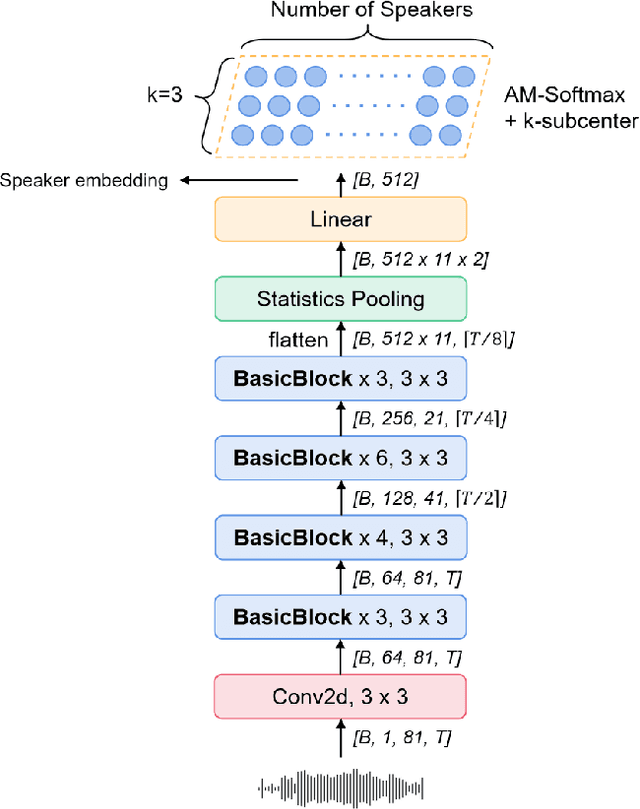
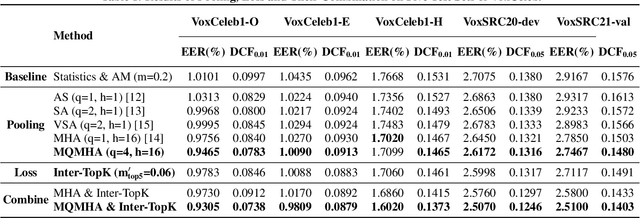
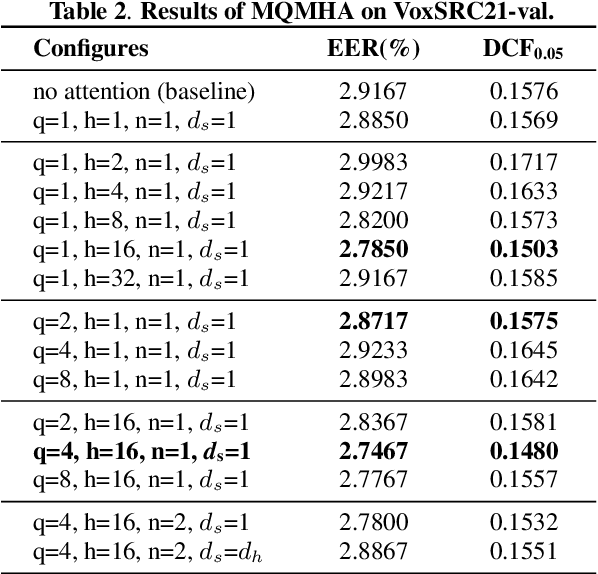
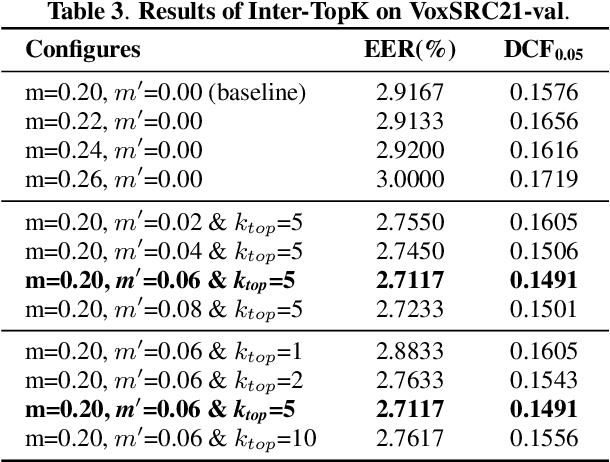
This paper describes the multi-query multi-head attention (MQMHA) pooling and inter-topK penalty methods which were first proposed in our submitted system description for VoxCeleb speaker recognition challenge (VoxSRC) 2021. Most multi-head attention pooling mechanisms either attend to the whole feature through multiple heads or attend to several split parts of the whole feature. Our proposed MQMHA combines both these two mechanisms and gain more diversified information. The margin-based softmax loss functions are commonly adopted to obtain discriminative speaker representations. To further enhance the inter-class discriminability, we propose a method that adds an extra inter-topK penalty on some confused speakers. By adopting both the MQMHA and inter-topK penalty, we achieved state-of-the-art performance in all of the public VoxCeleb test sets.
Poformer: A simple pooling transformer for speaker verification
Oct 10, 2021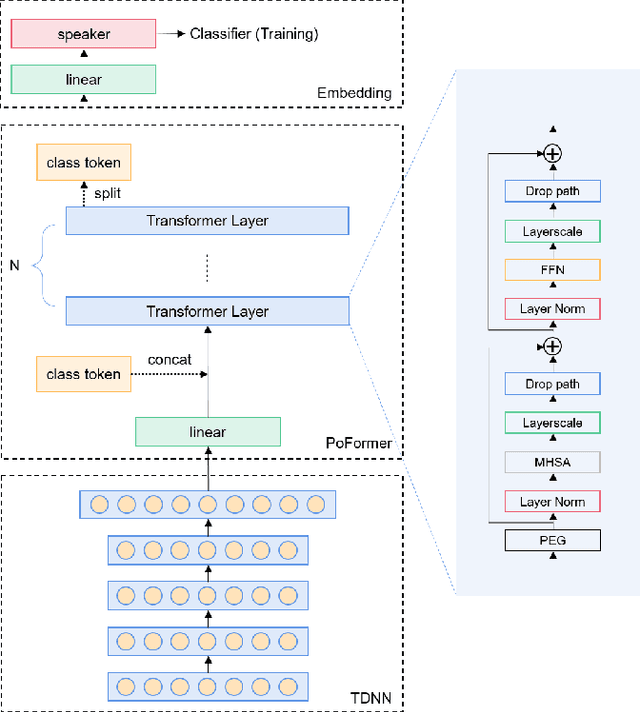
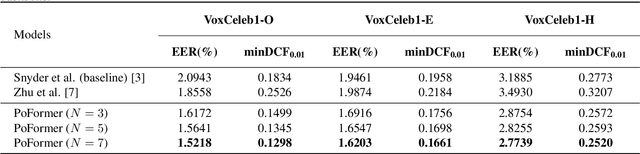
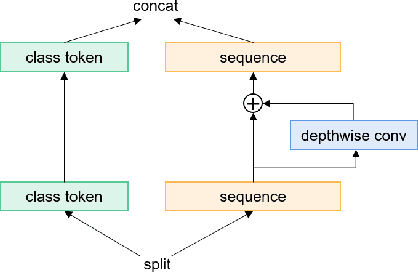
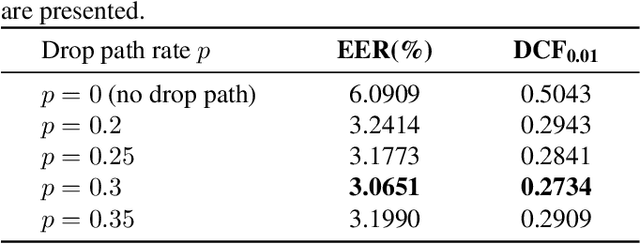
Most recent speaker verification systems are based on extracting speaker embeddings using a deep neural network. The pooling layer in the network aims to aggregate frame-level features extracted by the backbone. In this paper, we propose a new transformer based pooling structure called PoFormer to enhance the ability of the pooling layer to capture information along the whole time axis. Different from previous works that apply attention mechanism in a simple way or implement the multi-head mechanism in serial instead of in parallel, PoFormer follows the initial transformer structure with some minor modifications like a positional encoding generator, drop path and LayerScale to make the training procedure more stable and to prevent overfitting. Evaluated on various datasets, PoFormer outperforms the existing pooling system with at least a 13.00% improvement in EER and a 9.12% improvement in minDCF.
The SpeakIn System for VoxCeleb Speaker Recognition Challange 2021
Sep 05, 2021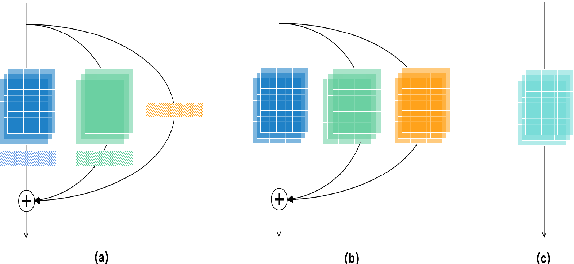
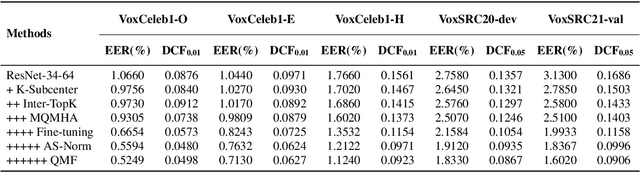
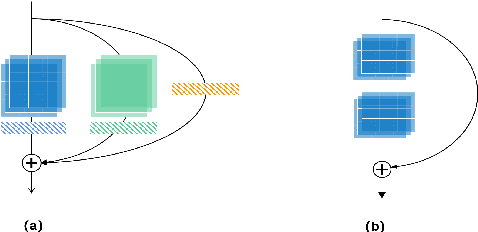

This report describes our submission to the track 1 and track 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC 2021). Both track 1 and track 2 share the same speaker verification system, which only uses VoxCeleb2-dev as our training set. This report explores several parts, including data augmentation, network structures, domain-based large margin fine-tuning, and back-end refinement. Our system is a fusion of 9 models and achieves first place in these two tracks of VoxSRC 2021. The minDCF of our submission is 0.1034, and the corresponding EER is 1.8460%.
AP20-OLR Challenge: Three Tasks and Their Baselines
Jun 04, 2020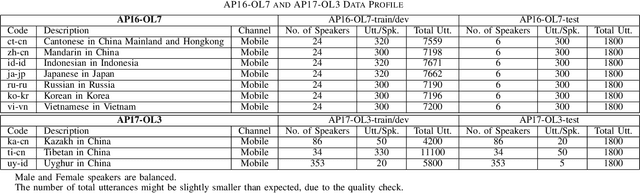
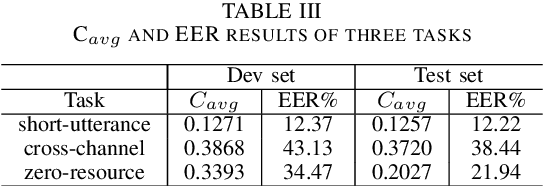
This paper introduces the fifth oriental language recognition (OLR) challenge AP20-OLR, which intends to improve the performance of language recognition systems, along with APSIPA Annual Summit and Conference (APSIPA ASC). The data profile, three tasks, the corresponding baselines, and the evaluation principles are introduced in this paper. The AP20-OLR challenge includes more languages, dialects and real-life data provided by Speechocean and the NSFC M2ASR project, and all the data is free for participants. The challenge this year still focuses on practical and challenging problems, with three tasks: (1) cross-channel LID, (2) dialect identification and (3) noisy LID. Based on Kaldi and Pytorch, recipes for i-vector and x-vector systems are also conducted as baselines for the three tasks. These recipes will be online-published, and available for participants to configure LID systems. The baseline results on the three tasks demonstrate that those tasks in this challenge are worth paying more efforts to achieve better performance.
Knowledge Graph Convolutional Networks for Recommender Systems with Label Smoothness Regularization
May 11, 2019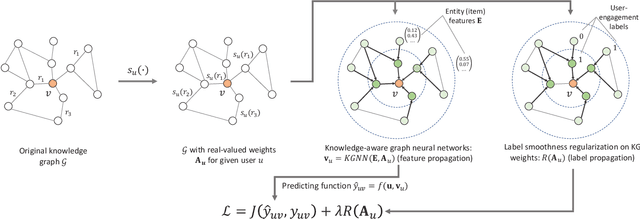
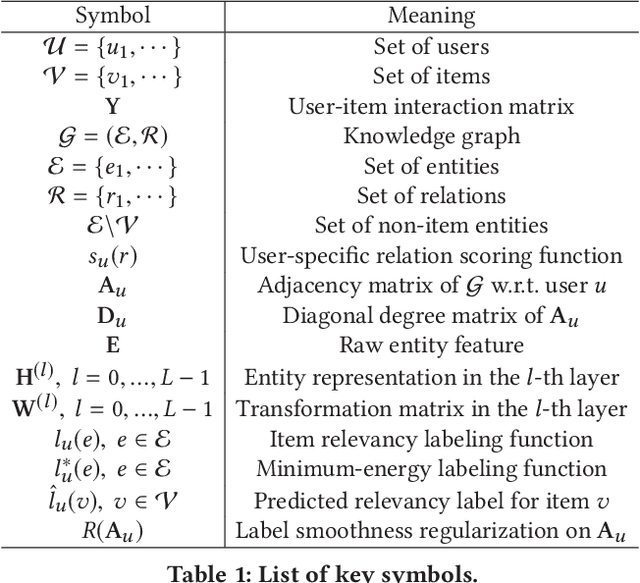
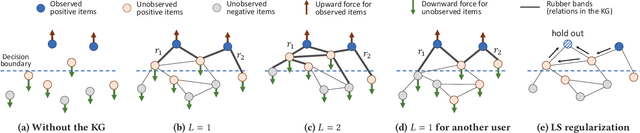
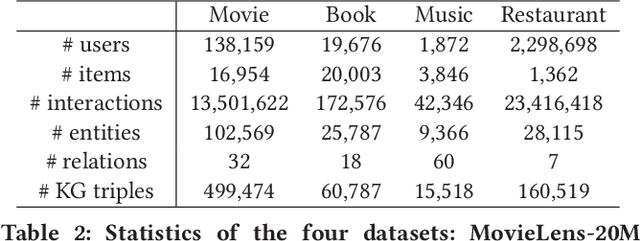
Knowledge graphs capture interlinked information between entities and they represent an attractive source of structured information that can be harnessed for recommender systems. However, existing recommender engines use knowledge graphs by manually designing features, do not allow for end-to-end training, or provide poor scalability. Here we propose Knowledge Graph Convolutional Networks (KGCN), an end-to-end trainable framework that harnesses item relationships captured by the knowledge graph to provide better recommendations. Conceptually, KGCN computes user-specific item embeddings by first applying a trainable function that identifies important knowledge graph relations for a given user and then transforming the knowledge graph into a user-specific weighted graph. Then, KGCN applies a graph convolutional neural network that computes an embedding of an item node by propagating and aggregating knowledge graph neighborhood information. Moreover, to provide better inductive bias KGCN uses label smoothness (LS), which provides regularization over edge weights and we prove that it is equivalent to label propagation scheme on a graph. Finally, We unify KGCN and LS regularization, and present a scalable minibatch implementation for KGCN-LS model. Experiments show that KGCN-LS outperforms strong baselines in four datasets. KGCN-LS also achieves great performance in sparse scenarios and is highly scalable with respect to the knowledge graph size.
Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation
Jan 23, 2019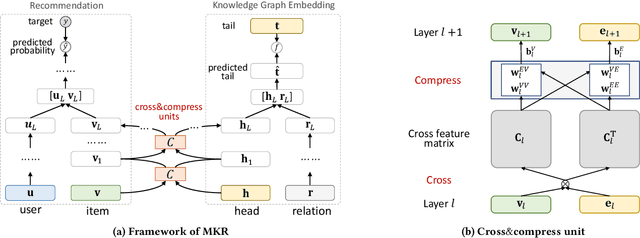

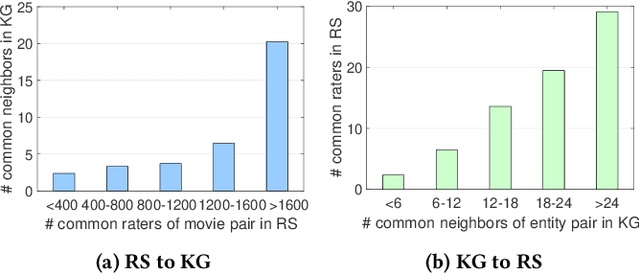

Collaborative filtering often suffers from sparsity and cold start problems in real recommendation scenarios, therefore, researchers and engineers usually use side information to address the issues and improve the performance of recommender systems. In this paper, we consider knowledge graphs as the source of side information. We propose MKR, a Multi-task feature learning approach for Knowledge graph enhanced Recommendation. MKR is a deep end-to-end framework that utilizes knowledge graph embedding task to assist recommendation task. The two tasks are associated by cross&compress units, which automatically share latent features and learn high-order interactions between items in recommender systems and entities in the knowledge graph. We prove that cross&compress units have sufficient capability of polynomial approximation, and show that MKR is a generalized framework over several representative methods of recommender systems and multi-task learning. Through extensive experiments on real-world datasets, we demonstrate that MKR achieves substantial gains in movie, book, music, and news recommendation, over state-of-the-art baselines. MKR is also shown to be able to maintain a decent performance even if user-item interactions are sparse.
Visual-Texual Emotion Analysis with Deep Coupled Video and Danmu Neural Networks
Nov 19, 2018
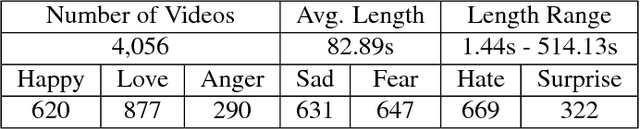
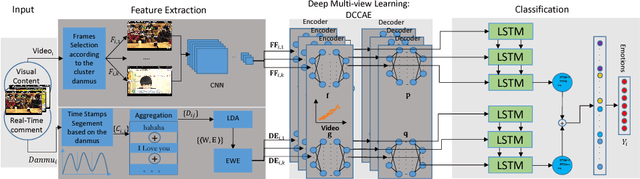
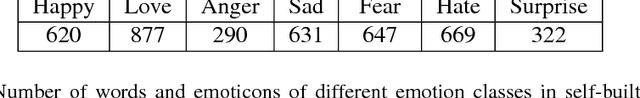
User emotion analysis toward videos is to automatically recognize the general emotional status of viewers from the multimedia content embedded in the online video stream. Existing works fall in two categories: 1) visual-based methods, which focus on visual content and extract a specific set of features of videos. However, it is generally hard to learn a mapping function from low-level video pixels to high-level emotion space due to great intra-class variance. 2) textual-based methods, which focus on the investigation of user-generated comments associated with videos. The learned word representations by traditional linguistic approaches typically lack emotion information and the global comments usually reflect viewers' high-level understandings rather than instantaneous emotions. To address these limitations, in this paper, we propose to jointly utilize video content and user-generated texts simultaneously for emotion analysis. In particular, we introduce exploiting a new type of user-generated texts, i.e., "danmu", which are real-time comments floating on the video and contain rich information to convey viewers' emotional opinions. To enhance the emotion discriminativeness of words in textual feature extraction, we propose Emotional Word Embedding (EWE) to learn text representations by jointly considering their semantics and emotions. Afterwards, we propose a novel visual-textual emotion analysis model with Deep Coupled Video and Danmu Neural networks (DCVDN), in which visual and textual features are synchronously extracted and fused to form a comprehensive representation by deep-canonically-correlated-autoencoder-based multi-view learning. Through extensive experiments on a self-crawled real-world video-danmu dataset, we prove that DCVDN significantly outperforms the state-of-the-art baselines.
RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
Aug 25, 2018



To address the sparsity and cold start problem of collaborative filtering, researchers usually make use of side information, such as social networks or item attributes, to improve recommendation performance. This paper considers the knowledge graph as the source of side information. To address the limitations of existing embedding-based and path-based methods for knowledge-graph-aware recommendation, we propose Ripple Network, an end-to-end framework that naturally incorporates the knowledge graph into recommender systems. Similar to actual ripples propagating on the surface of water, Ripple Network stimulates the propagation of user preferences over the set of knowledge entities by automatically and iteratively extending a user's potential interests along links in the knowledge graph. The multiple "ripples" activated by a user's historically clicked items are thus superposed to form the preference distribution of the user with respect to a candidate item, which could be used for predicting the final clicking probability. Through extensive experiments on real-world datasets, we demonstrate that Ripple Network achieves substantial gains in a variety of scenarios, including movie, book and news recommendation, over several state-of-the-art baselines.