 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEX: A Vision-Language Model for Land Cover Extraction on Spectral Remote Sensing Images
Aug 07, 2025Spectral information has long been recognized as a critical cue in remote sensing observations. Although numerous vision-language models have been developed for pixel-level interpretation, spectral information remains underutilized, resulting in suboptimal performance, particularly in multispectral scenarios. To address this limitation, we construct a vision-language instruction-following dataset named SPIE, which encodes spectral priors of land-cover objects into textual attributes recognizable by large language models (LLMs), based on classical spectral index computations. Leveraging this dataset, we propose SPEX, a multimodal LLM designed for instruction-driven land cover extraction. To this end, we introduce several carefully designed components and training strategies, including multiscale feature aggregation, token context condensation, and multispectral visual pre-training, to achieve precise and flexible pixel-level interpretation. To the best of our knowledge, SPEX is the first multimodal vision-language model dedicated to land cover extraction in spectral remote sensing imagery. Extensive experiments on five public multispectral datasets demonstrate that SPEX consistently outperforms existing state-of-the-art methods in extracting typical land cover categories such as vegetation, buildings, and water bodies. Moreover, SPEX is capable of generating textual explanations for its predictions, thereby enhancing interpretability and user-friendliness. Code will be released at: https://github.com/MiliLab/SPEX.
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
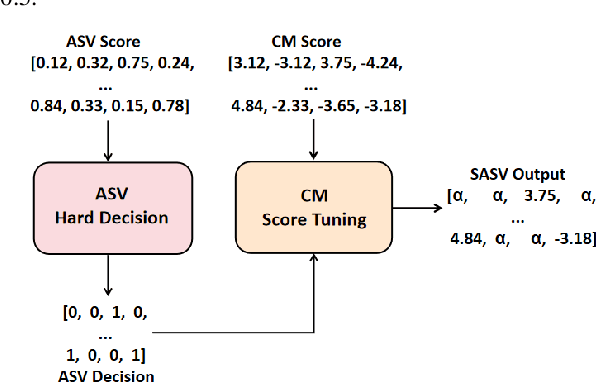
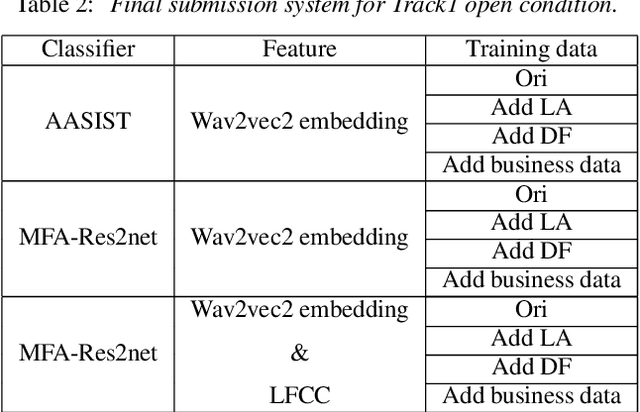
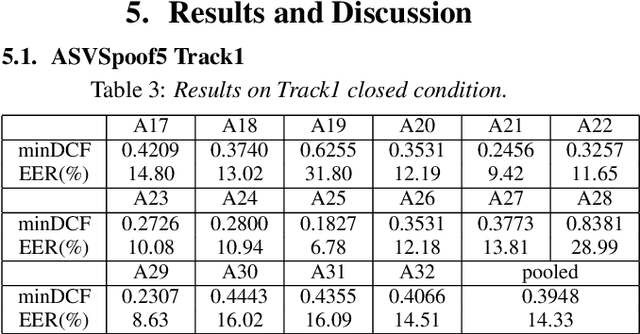
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
HyperSIGMA: Hyperspectral Intelligence Comprehension Foundation Model
Jun 17, 2024



Foundation models (FMs) are revolutionizing the analysis and understanding of remote sensing (RS) scenes, including aerial RGB, multispectral, and SAR images. However, hyperspectral images (HSIs), which are rich in spectral information, have not seen much application of FMs, with existing methods often restricted to specific tasks and lacking generality. To fill this gap, we introduce HyperSIGMA, a vision transformer-based foundation model for HSI interpretation, scalable to over a billion parameters. To tackle the spectral and spatial redundancy challenges in HSIs, we introduce a novel sparse sampling attention (SSA) mechanism, which effectively promotes the learning of diverse contextual features and serves as the basic block of HyperSIGMA. HyperSIGMA integrates spatial and spectral features using a specially designed spectral enhancement module. In addition, we construct a large-scale hyperspectral dataset, HyperGlobal-450K, for pre-training, which contains about 450K hyperspectral images, significantly surpassing existing datasets in scale. Extensive experiments on various high-level and low-level HSI tasks demonstrate HyperSIGMA's versatility and superior representational capability compared to current state-of-the-art methods. Moreover, HyperSIGMA shows significant advantages in scalability, robustness, cross-modal transferring capability, and real-world applicability.
MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pretraining
Mar 20, 2024



Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pretraining is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pretraining as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pretraining (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pretraining on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP.
THUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
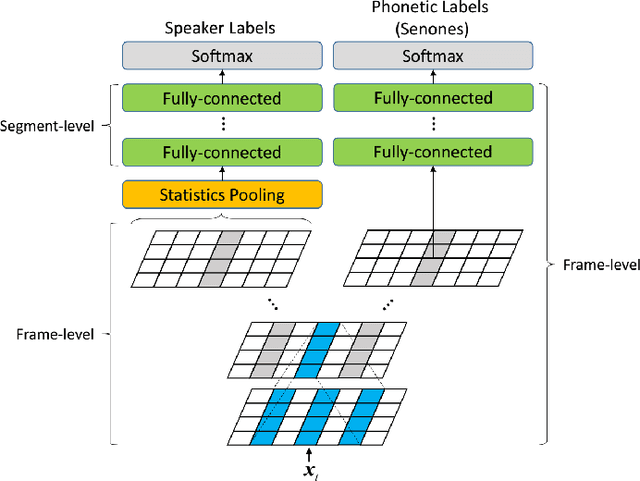
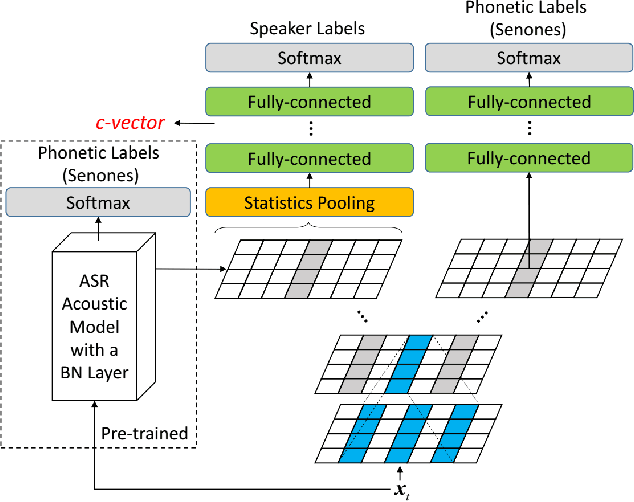

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
The SpeakIn Speaker Verification System for Far-Field Speaker Verification Challenge 2022
Sep 23, 2022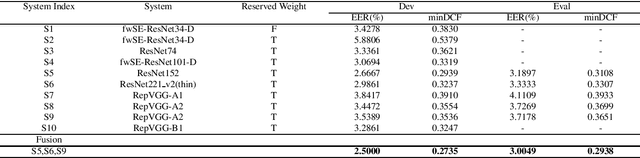
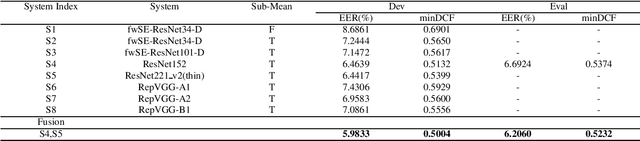
This paper describes speaker verification (SV) systems submitted by the SpeakIn team to the Task 1 and Task 2 of the Far-Field Speaker Verification Challenge 2022 (FFSVC2022). SV tasks of the challenge focus on the problem of fully supervised far-field speaker verification (Task 1) and semi-supervised far-field speaker verification (Task 2). In Task 1, we used the VoxCeleb and FFSVC2020 datasets as train datasets. And for Task 2, we only used the VoxCeleb dataset as train set. The ResNet-based and RepVGG-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax to classify the resulting embeddings. We innovatively propose a staged transfer learning method. In the pre-training stage we reserve the speaker weights, and there are no positive samples to train them in this stage. Then we fine-tune these weights with both positive and negative samples in the second stage. Compared with the traditional transfer learning strategy, this strategy can better improve the model performance. The Sub-Mean and AS-Norm backend methods were used to solve the problem of domain mismatch. In the fusion stage, three models were fused in Task1 and two models were fused in Task2. On the FFSVC2022 leaderboard, the EER of our submission is 3.0049% and the corresponding minDCF is 0.2938 in Task1. In Task2, EER and minDCF are 6.2060% and 0.5232 respectively. Our approach leads to excellent performance and ranks 1st in both challenge tasks.
The SpeakIn System Description for CNSRC2022
Sep 22, 2022


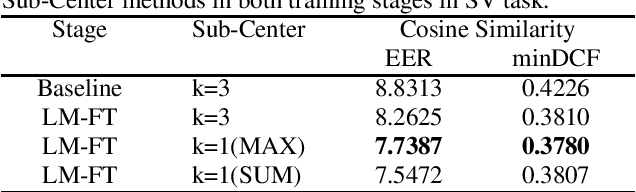
This report describes our speaker verification systems for the tasks of the CN-Celeb Speaker Recognition Challenge 2022 (CNSRC 2022). This challenge includes two tasks, namely speaker verification(SV) and speaker retrieval(SR). The SV task involves two tracks: fixed track and open track. In the fixed track, we only used CN-Celeb.T as the training set. For the open track of the SV task and SR task, we added our open-source audio data. The ResNet-based, RepVGG-based, and TDNN-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax combined with the Sub-Center method to classify the resulting embeddings. We also used the Large-Margin Fine-Tuning strategy to further improve the model performance. In the backend, Sub-Mean and AS-Norm were used. In the SV task fixed track, our system was a fusion of five models, and two models were fused in the SV task open track. And we used a single system in the SR task. Our approach leads to superior performance and comes the 1st place in the open track of the SV task, the 2nd place in the fixed track of the SV task, and the 3rd place in the SR task.
Rep Works in Speaker Verification
Oct 19, 2021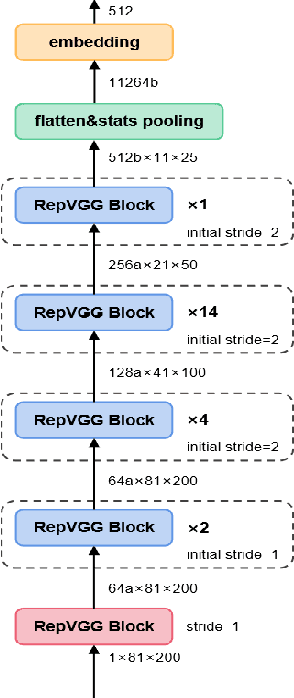
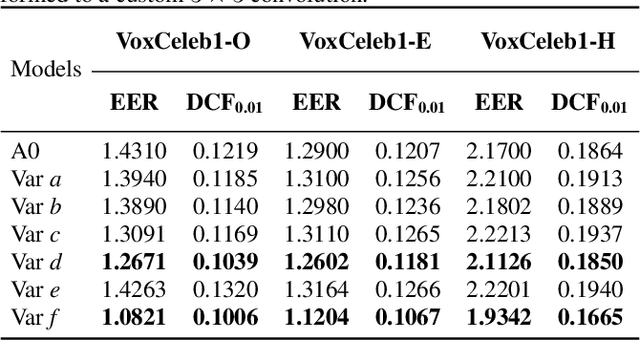
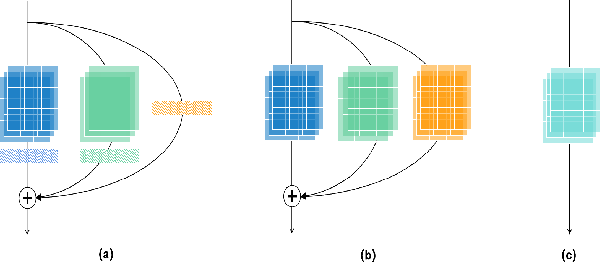
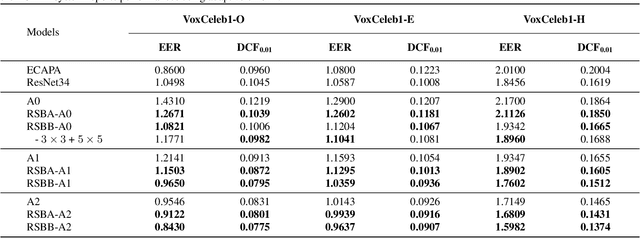
Multi-branch convolutional neural network architecture has raised lots of attention in speaker verification since the aggregation of multiple parallel branches can significantly improve performance. However, this design is not efficient enough during the inference time due to the increase of model parameters and extra operations. In this paper, we present a new multi-branch network architecture RepSPKNet that uses a re-parameterization technique. With this technique, our backbone model contains an efficient VGG-like inference state while its training state is a complicated multi-branch structure. We first introduce the specific structure of RepVGG into speaker verification and propose several variants of this structure. The performance is evaluated on VoxCeleb-based test sets. We demonstrate that both the branch diversity and the branch capacity play important roles in RepSPKNet designing. Our RepSPKNet achieves state-of-the-art performance with a 1.5982% EER and a 0.1374 minDCF on VoxCeleb1-H.
Multi-query multi-head attention pooling and Inter-topK penalty for speaker verification
Oct 12, 2021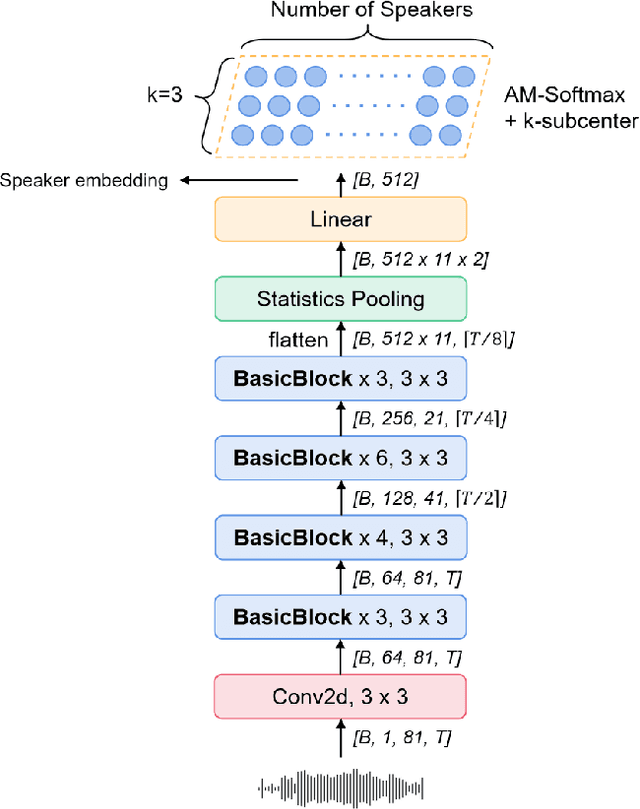
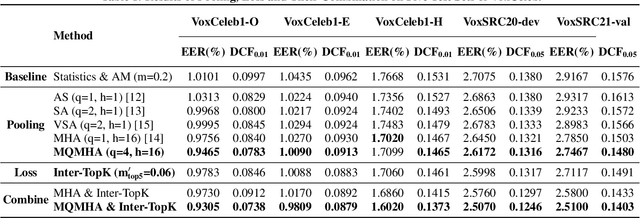
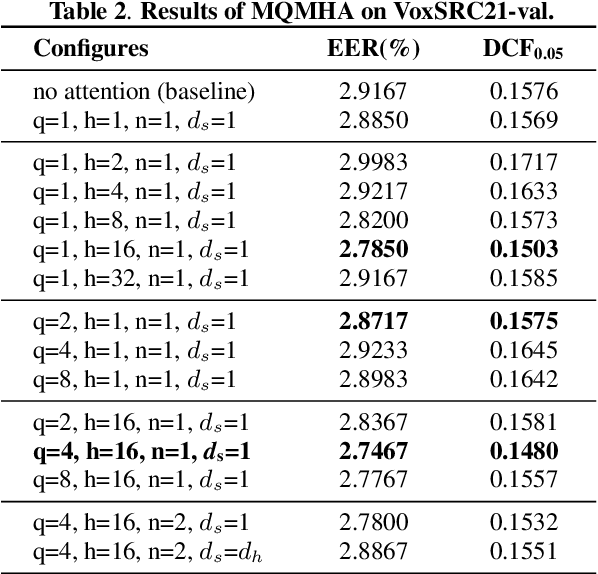
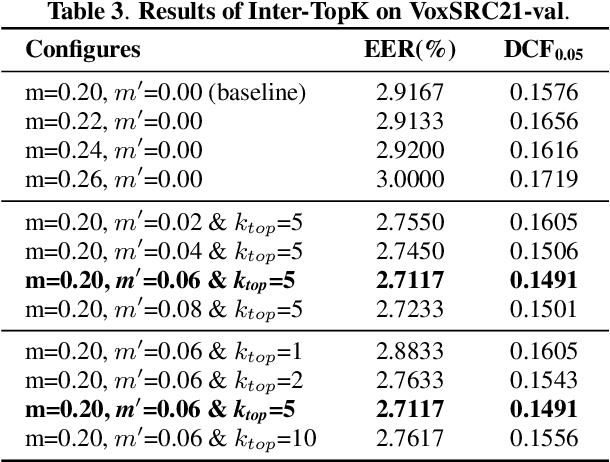
This paper describes the multi-query multi-head attention (MQMHA) pooling and inter-topK penalty methods which were first proposed in our submitted system description for VoxCeleb speaker recognition challenge (VoxSRC) 2021. Most multi-head attention pooling mechanisms either attend to the whole feature through multiple heads or attend to several split parts of the whole feature. Our proposed MQMHA combines both these two mechanisms and gain more diversified information. The margin-based softmax loss functions are commonly adopted to obtain discriminative speaker representations. To further enhance the inter-class discriminability, we propose a method that adds an extra inter-topK penalty on some confused speakers. By adopting both the MQMHA and inter-topK penalty, we achieved state-of-the-art performance in all of the public VoxCeleb test sets.
Poformer: A simple pooling transformer for speaker verification
Oct 10, 2021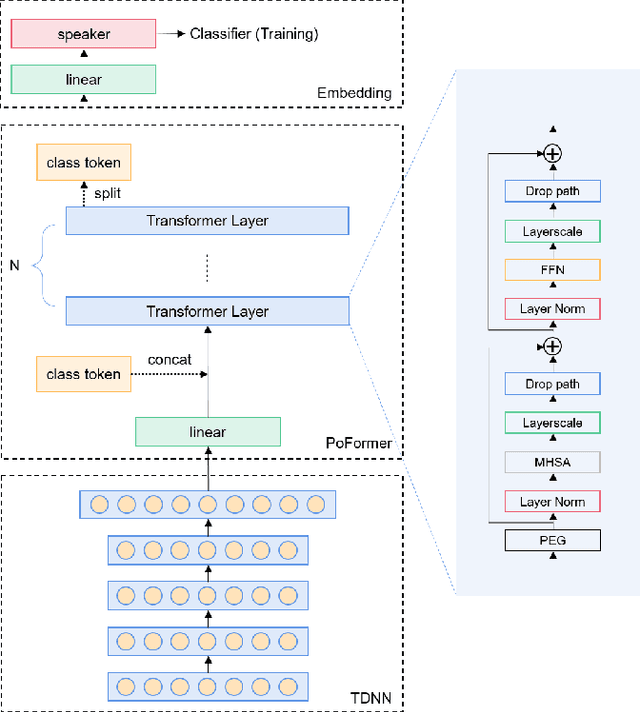
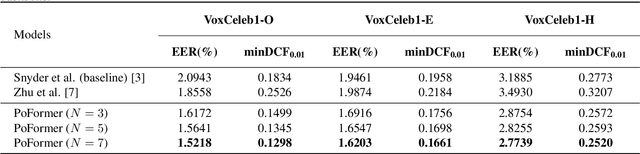
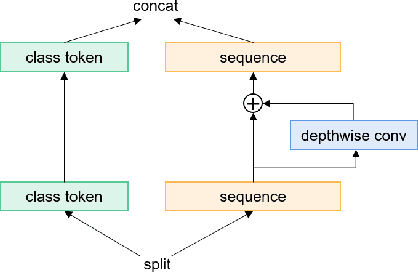
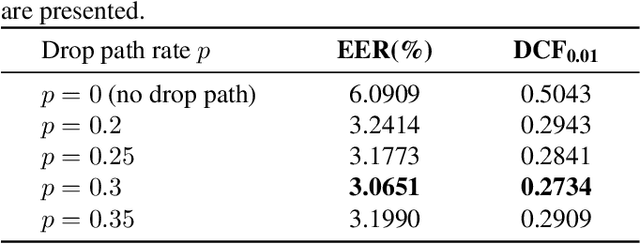
Most recent speaker verification systems are based on extracting speaker embeddings using a deep neural network. The pooling layer in the network aims to aggregate frame-level features extracted by the backbone. In this paper, we propose a new transformer based pooling structure called PoFormer to enhance the ability of the pooling layer to capture information along the whole time axis. Different from previous works that apply attention mechanism in a simple way or implement the multi-head mechanism in serial instead of in parallel, PoFormer follows the initial transformer structure with some minor modifications like a positional encoding generator, drop path and LayerScale to make the training procedure more stable and to prevent overfitting. Evaluated on various datasets, PoFormer outperforms the existing pooling system with at least a 13.00% improvement in EER and a 9.12% improvement in minDCF.