 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021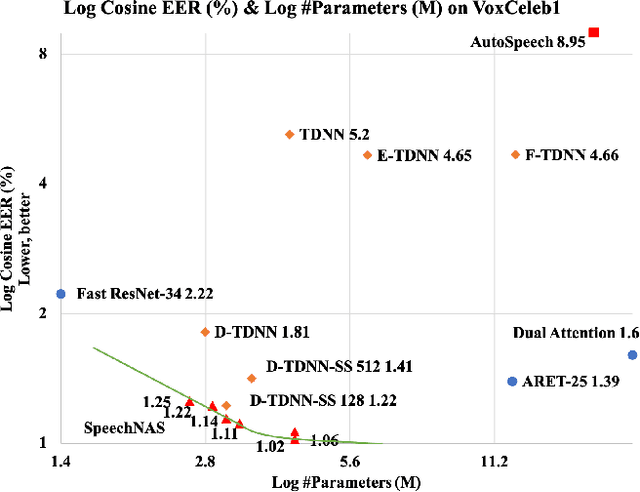
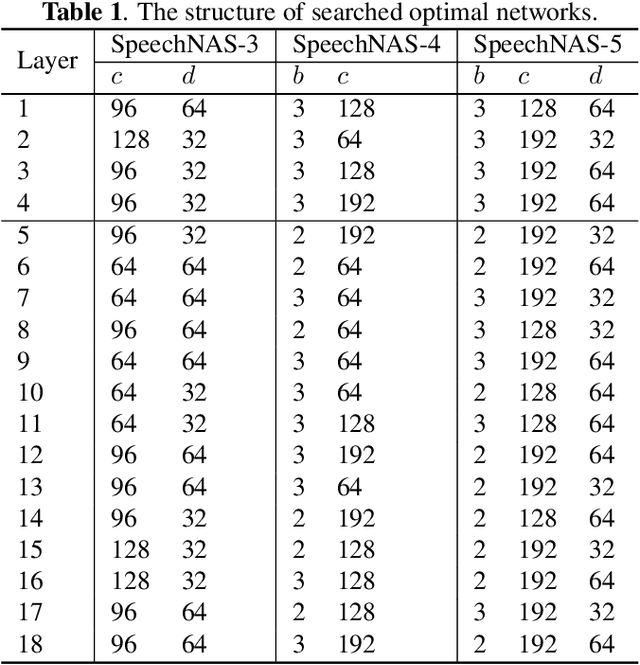
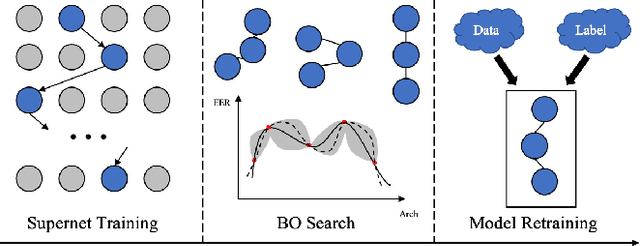
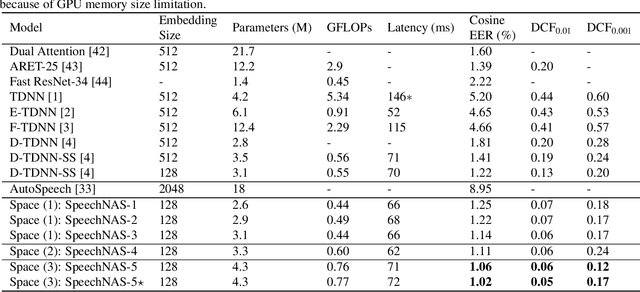
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
Dynamic Multi-scale Convolution for Dialect Identification
Aug 02, 2021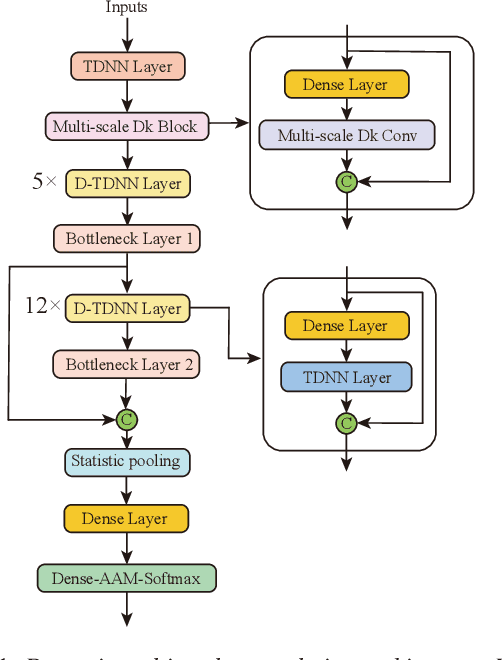

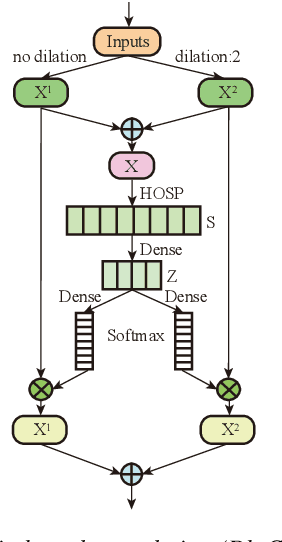

Time Delay Neural Networks (TDNN)-based methods are widely used in dialect identification. However, in previous work with TDNN application, subtle variant is being neglected in different feature scales. To address this issue, we propose a new architecture, named dynamic multi-scale convolution, which consists of dynamic kernel convolution, local multi-scale learning, and global multi-scale pooling. Dynamic kernel convolution captures features between short-term and long-term context adaptively. Local multi-scale learning, which represents multi-scale features at a granular level, is able to increase the range of receptive fields for convolution operation. Besides, global multi-scale pooling is applied to aggregate features from different bottleneck layers in order to collect information from multiple aspects. The proposed architecture significantly outperforms state-of-the-art system on the AP20-OLR-dialect-task of oriental language recognition (OLR) challenge 2020, with the best average cost performance (Cavg) of 0.067 and the best equal error rate (EER) of 6.52%. Compared with the known best results, our method achieves 9% of Cavg and 45% of EER relative improvement, respectively. Furthermore, the parameters of proposed model are 91% fewer than the best known model.