 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Surround Camera Calibration Method in Road Scene for Self-driving Car
May 26, 2023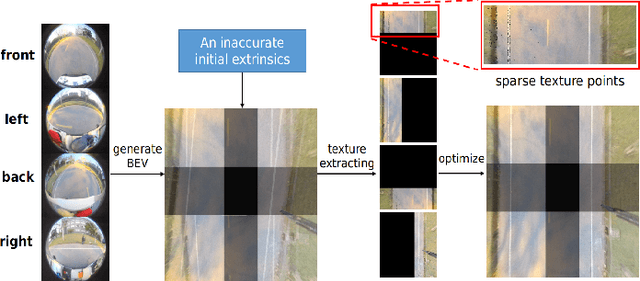

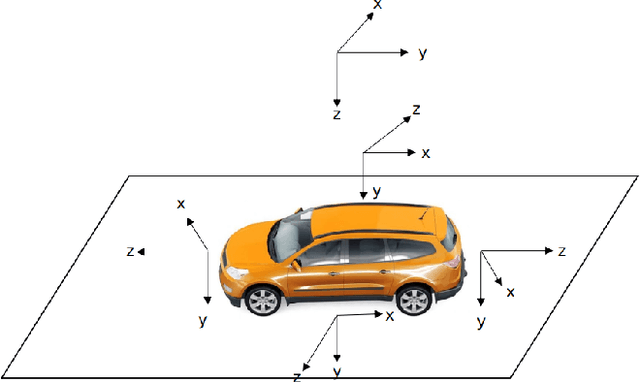

With the development of autonomous driving technology, sensor calibration has become a key technology to achieve accurate perception fusion and localization. Accurate calibration of the sensors ensures that each sensor can function properly and accurate information aggregation can be achieved. Among them, camera calibration based on surround view has received extensive attention. In autonomous driving applications, the calibration accuracy of the camera can directly affect the accuracy of perception and depth estimation. For online calibration of surround-view cameras, traditional feature extraction-based methods will suffer from strong distortion when the initial extrinsic parameters error is large, making these methods less robust and inaccurate. More existing methods use the sparse direct method to calibrate multi-cameras, which can ensure both accuracy and real-time performance and is theoretically achievable. However, this method requires a better initial value, and the initial estimate with a large error is often stuck in a local optimum. To this end, we introduce a robust automatic multi-cameras (pinhole or fisheye cameras) calibration and refinement method in the road scene. We utilize the coarse-to-fine random-search strategy, and it can solve large disturbances of initial extrinsic parameters, which can make up for falling into optimal local value in nonlinear optimization methods. In the end, quantitative and qualitative experiments are conducted in actual and simulated environments, and the result shows the proposed method can achieve accuracy and robustness performance. The open-source code is available at https://github.com/OpenCalib/SurroundCameraCalib.
Hyper-Tune: Towards Efficient Hyper-parameter Tuning at Scale
Jan 18, 2022


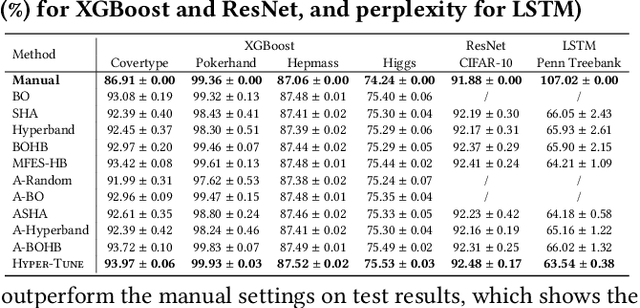
The ever-growing demand and complexity of machine learning are putting pressure on hyper-parameter tuning systems: while the evaluation cost of models continues to increase, the scalability of state-of-the-arts starts to become a crucial bottleneck. In this paper, inspired by our experience when deploying hyper-parameter tuning in a real-world application in production and the limitations of existing systems, we propose Hyper-Tune, an efficient and robust distributed hyper-parameter tuning framework. Compared with existing systems, Hyper-Tune highlights multiple system optimizations, including (1) automatic resource allocation, (2) asynchronous scheduling, and (3) multi-fidelity optimizer. We conduct extensive evaluations on benchmark datasets and a large-scale real-world dataset in production. Empirically, with the aid of these optimizations, Hyper-Tune outperforms competitive hyper-parameter tuning systems on a wide range of scenarios, including XGBoost, CNN, RNN, and some architectural hyper-parameters for neural networks. Compared with the state-of-the-art BOHB and A-BOHB, Hyper-Tune achieves up to 11.2x and 5.1x speedups, respectively.
ProxyBO: Accelerating Neural Architecture Search via Bayesian Optimization with Zero-cost Proxies
Oct 26, 2021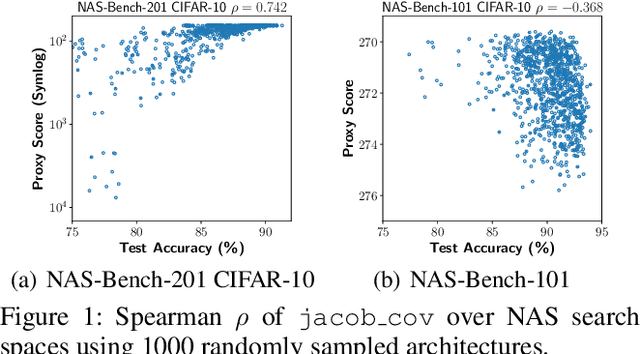
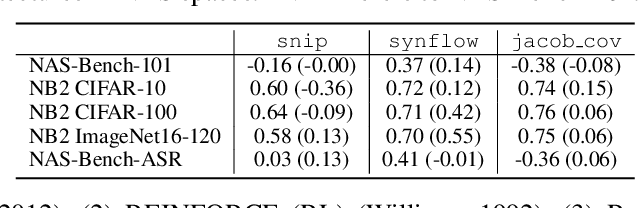
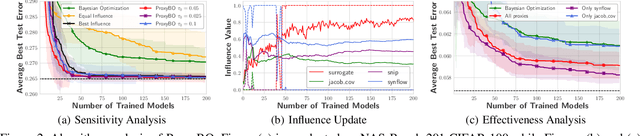
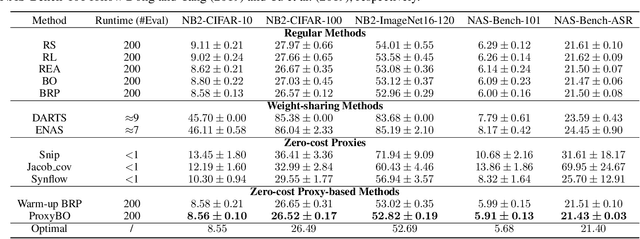
Designing neural architectures requires immense manual efforts. This has promoted the development of neural architecture search (NAS) to automate this design. While previous NAS methods achieve promising results but run slowly and zero-cost proxies run extremely fast but are less promising, recent work considers utilizing zero-cost proxies via a simple warm-up. The existing method has two limitations, which are unforeseeable reliability and one-shot usage. To address the limitations, we present ProxyBO, an efficient Bayesian optimization framework that utilizes the zero-cost proxies to accelerate neural architecture search. We propose the generalization ability measurement to estimate the fitness of proxies on the task during each iteration and then combine BO with zero-cost proxies via dynamic influence combination. Extensive empirical studies show that ProxyBO consistently outperforms competitive baselines on five tasks from three public benchmarks. Concretely, ProxyBO achieves up to 5.41x and 3.83x speedups over the state-of-the-art approach REA and BRP-NAS, respectively.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021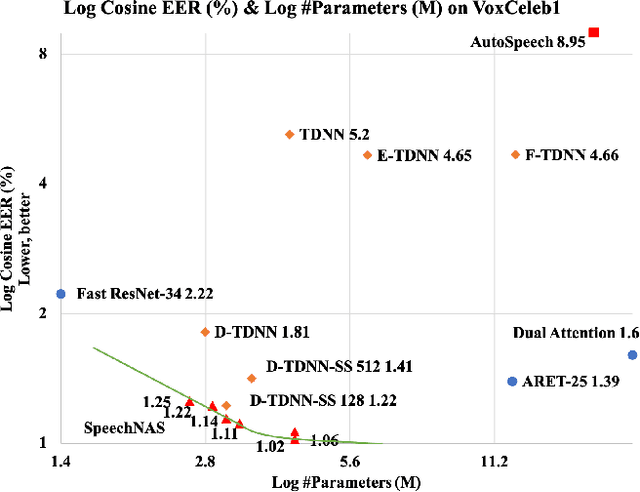
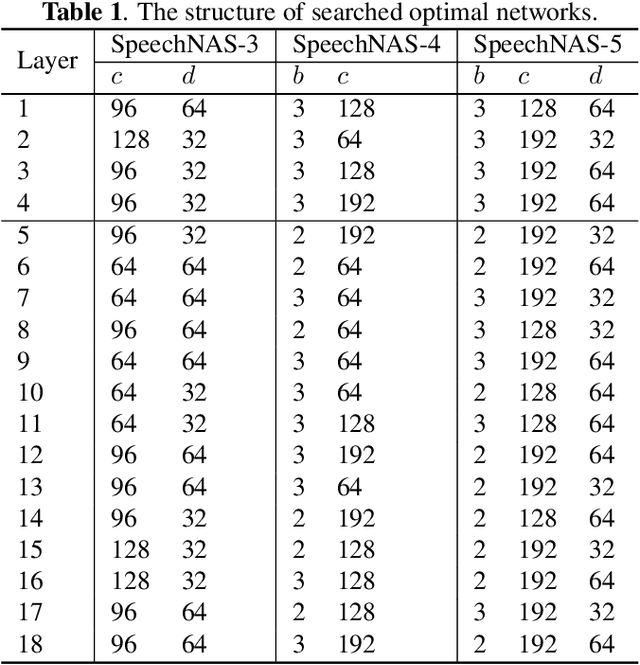
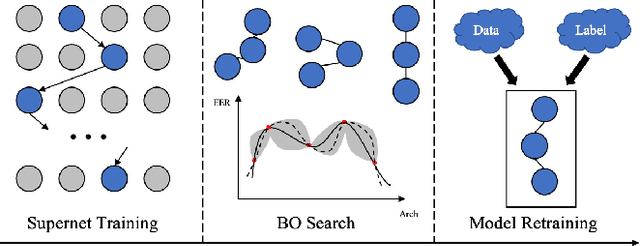
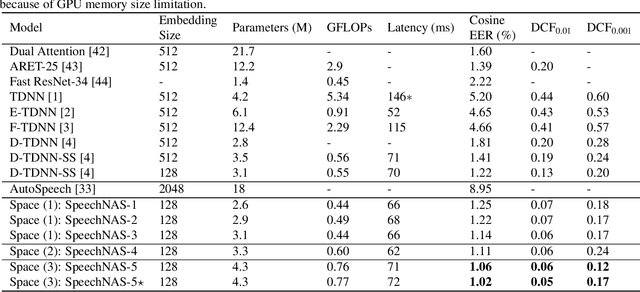
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
MixPath: A Unified Approach for One-shot Neural Architecture Search
Jan 22, 2020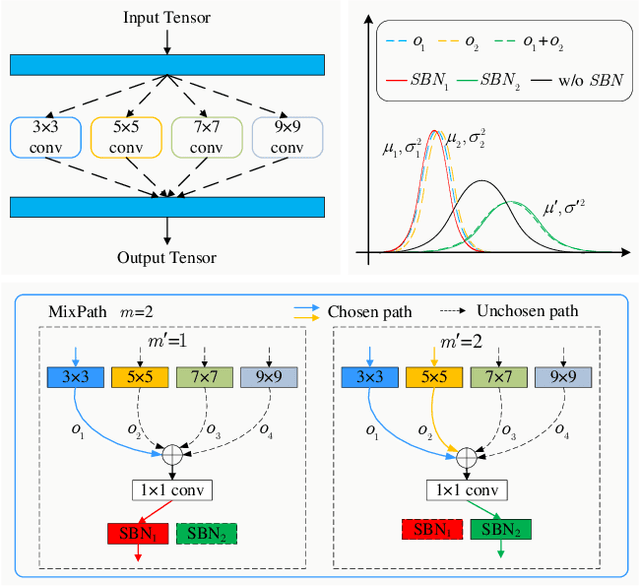
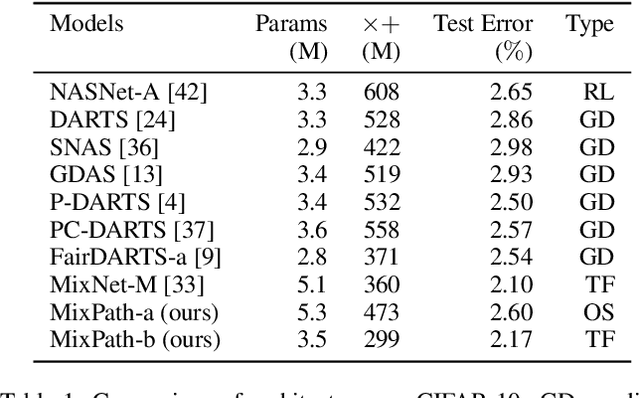
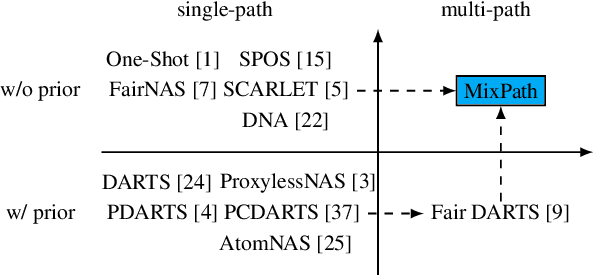
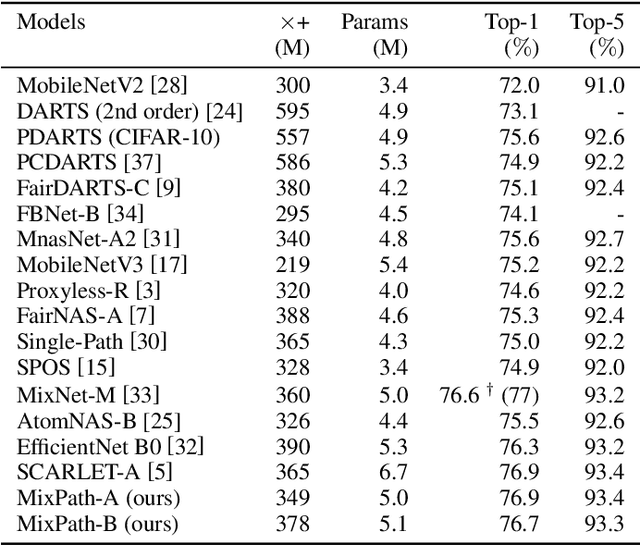
The expressiveness of search space is a key concern in neural architecture search (NAS). Previous approaches are mainly limited to searching for single-path networks. Incorporating multi-path search space with the current one-shot doctrine remains untackled. In this paper, we investigate the supernet behavior under multi-path's setting. We show that a trivial generalization from single-path to multi-path incurs severe feature inconsistency, which deteriorates both supernet training stability and model ranking ability. To remedy this degradation, we employ what we term as shadow batch normalizations (SBN) to catch changing statistics when activating different sets of paths. Extensive experiments on a common NAS benchmark, NAS-bench-101, show that SBN can boost ranking performance at neglectable cost. It breaks the Kendall Tau's record with a clear margin, reaching 0.597. Moreover, we take advantage of feature similarities on activated paths to largely reduce the number of needed SBNs. We call our method MixPath. When proxylessly searching on ImageNet, we obtain several lightweight models that outperform EfficientNet-B0 with fewer FLOPs, parameters and 300x fewer searching resources. Our code will be available https://github.com/xiaomi-automl/MixPath.git .
Neural Architecture Search on Acoustic Scene Classification
Dec 30, 2019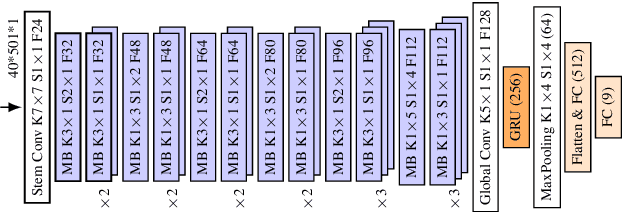
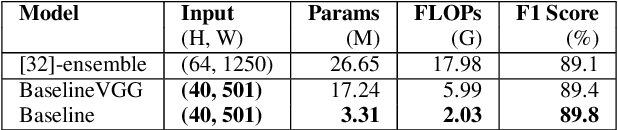
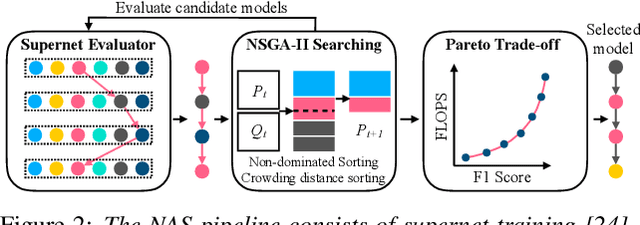
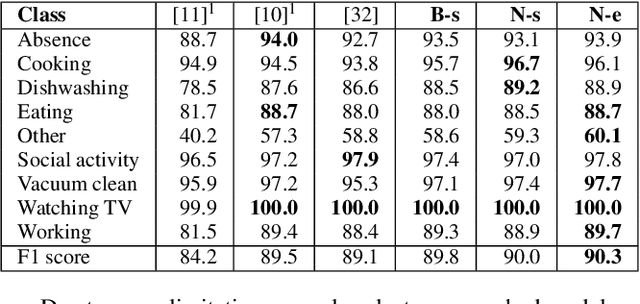
Convolutional neural networks are widely adopted in Acoustic Scene Classification (ASC) tasks, but they generally carry a heavy computational burden. In this work, we propose a lightweight yet high-performing baseline network inspired by MobileNetV2, which replaces square convolutional kernels with unidirectional ones to extract features alternately in temporal and frequency dimensions. Furthermore, we explore a dynamic architecture space built on the basis of the proposed baseline with the recent Neural Architecture Search (NAS) paradigm, which first trains a supernet that incorporates all candidate networks and then applies a well-known evolutionary algorithm NSGA-II to discover more efficient networks with higher accuracy and lower computational cost. Experimental results demonstrate that our searched network is competent in ASC tasks, which achieves 90.3% F1-score on the DCASE2018 task 5 evaluation set, marking a new state-of-the-art performance while saving 25% of FLOPs compared to our baseline network.
Fair DARTS: Eliminating Unfair Advantages in Differentiable Architecture Search
Nov 27, 2019



Differential Architecture Search (DARTS) is now a widely disseminated weight-sharing neural architecture search method. However, there are two fundamental weaknesses remain untackled. First, we observe that the well-known aggregation of skip connections during optimization is caused by an unfair advantage in an exclusive competition. Second, there is a non-negligible incongruence when discretizing continuous architectural weights to a one-hot representation. Because of these two reasons, DARTS delivers a biased solution that might not even be suboptimal. In this paper, we present a novel approach to curing both frailties. Specifically, as unfair advantages in a pure exclusive competition easily induce a monopoly, we relax the choice of operations to be collaborative, where we let each operation have an equal opportunity to develop its strength. We thus call our method Fair DARTS. Moreover, we propose a zero-one loss to directly reduce the discretization gap. Experiments are performed on two mainstream search spaces, in which we achieve new state-of-the-art networks on ImageNet. Our code is available on https://github.com/xiaomi-automl/fairdarts.
ScarletNAS: Bridging the Gap Between Scalability and Fairness in Neural Architecture Search
Sep 13, 2019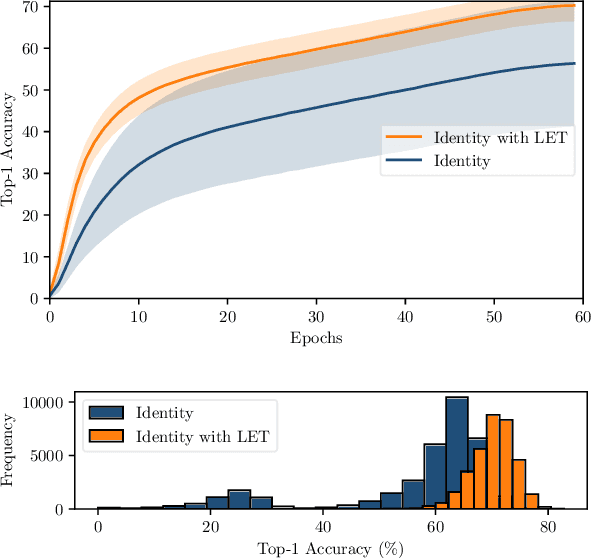

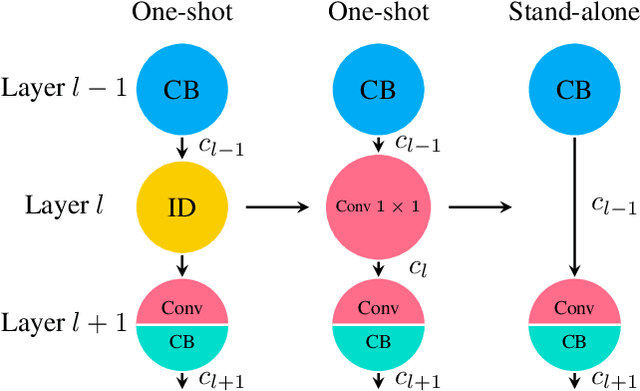

One-shot neural architecture search features fast training of a supernet in a single run. A pivotal issue for this weight-sharing approach is the lacking of scalability. A simple adjustment with identity block renders a scalable supernet but it arouses unstable training, which makes the subsequent model ranking unreliable. In this paper, we introduce linearly equivalent transformation on identity blocks to soothe training perturbation, providing with the proof that such a transformed model is identical with the original one as per representational power. Our overall method is hereby named as SCARLET (SCAlable supeRnet with Linearly Equivalent Transformation). We show through experiments that linearly equivalent transformations can indeed harmonize the supernet training. With an EfficientNet-like search space and a multi-objective reinforced evolutionary backend, it generates a series of competitive models: SCARLET-A achieves 76.9% top-1 accuracy on ImageNet which outperforms EfficientNet-B0 by a large margin; the shallower SCARLET-B exemplifies the proposed scalability which attains the same accuracy 76.3% as EfficientNet-B0 with much fewer FLOPs. Moreover, our manually scaled SCARLET-A2 hits 79.5%, SCARLET-A4 82.3%, which are on par with EfficientNet-B2 and EfficientNet-B4 respectively. The models and evaluation code are released online https://github.com/xiaomi-automl/ScarletNAS .
FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search
Aug 14, 2019


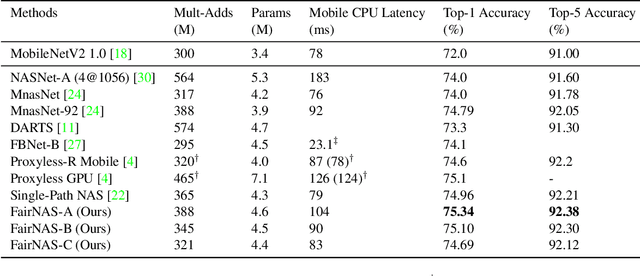
The ability to rank models by its real strength is the key to Neural Architecture Search. Traditional approaches adopt an incomplete training for such purpose which is still very costly. One-shot methods are thus devised to cut the expense by reusing the same set of weights. However, it is uncertain whether shared weights are truly effective. It is also unclear if a picked model is better because of its vigorous representational power or simply because it is overtrained. In order to remove the suspicion, we propose a novel idea called Fair Neural Architecture Search (FairNAS), in which a strict fairness constraint is enforced for fair inheritance and training. In this way, our supernet exhibits nice convergence and very high training accuracy. The performance of any sampled model loaded with shared weights from the supernet strongly correlates with that of stand-alone counterpart when trained fully. This result dramatically improves the searching efficiency, with a multi-objective reinforced evolutionary search backend, our pipeline generated a new set of state-of-the-art architectures on ImageNet: FairNAS-A attains 75.34% top-1 validation accuracy on ImageNet, FairNAS-B 75.10%, FairNAS-C 74.69%, even with lower multi-adds and/or fewer number of parameters compared with others. The models and their evaluation code are made publicly available online http://github.com/fairnas/FairNAS.
Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
Jan 24, 2019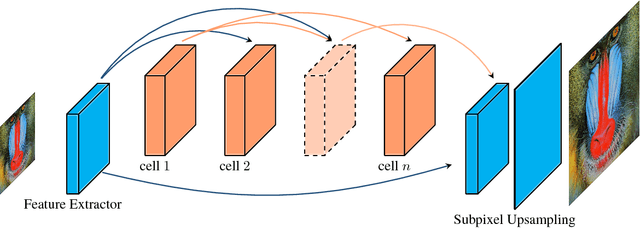
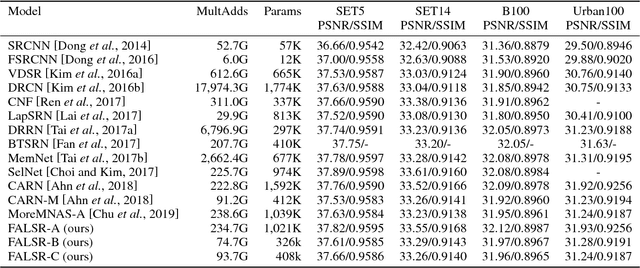

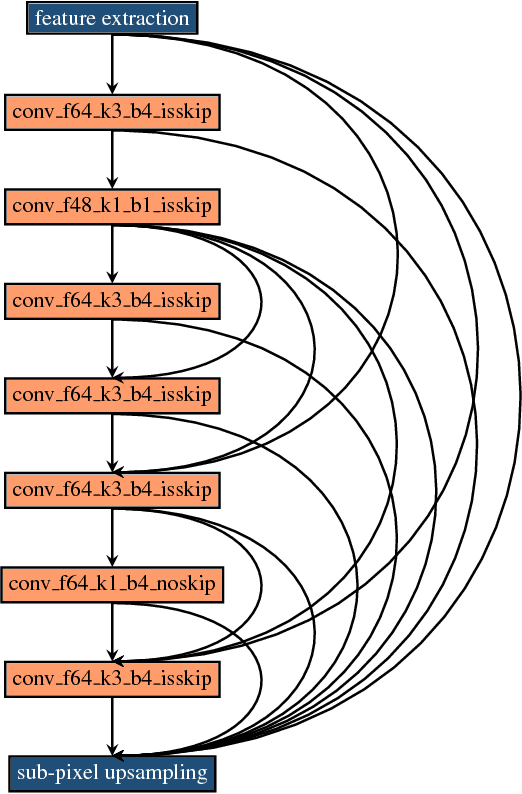
Deep convolution neural networks demonstrate impressive results in the super-resolution domain. A series of studies concentrate on improving peak signal noise ratio (PSNR) by using much deeper layers, which are not friendly to constrained resources. Pursuing a trade-off between the restoration capacity and the simplicity of models is still non-trivial. Recent contributions are struggling to manually maximize this balance, while our work achieves the same goal automatically with neural architecture search. Specifically, we handle super-resolution with a multi-objective approach. We also propose an elastic search tactic at both micro and macro level, based on a hybrid controller that profits from evolutionary computation and reinforcement learning. Quantitative experiments help us to draw a conclusion that our generated models dominate most of the state-of-the-art methods with respect to the individual FLOPS.