 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
Mar 09, 2026The integration of Large Language Models (LLMs) into the financial domain is driving a paradigm shift from passive information retrieval to dynamic, agentic interaction. While general-purpose tool learning has witnessed a surge in benchmarks, the financial sector, characterized by high stakes, strict compliance, and rapid data volatility, remains critically underserved. Existing financial evaluations predominantly focus on static textual analysis or document-based QA, ignoring the complex reality of tool execution. Conversely, general tool benchmarks lack the domain-specific rigor required for finance, often relying on toy environments or a negligible number of financial APIs. To bridge this gap, we introduce FinToolBench, the first real-world, runnable benchmark dedicated to evaluating financial tool learning agents. Unlike prior works limited to a handful of mock tools, FinToolBench establishes a realistic ecosystem coupling 760 executable financial tools with 295 rigorous, tool-required queries. We propose a novel evaluation framework that goes beyond binary execution success, assessing agents on finance-critical dimensions: timeliness, intent type, and regulatory domain alignment. Furthermore, we present FATR, a finance-aware tool retrieval and reasoning baseline that enhances stability and compliance. By providing the first testbed for auditable, agentic financial execution, FinToolBench sets a new standard for trustworthy AI in finance. The tool manifest, execution environment, and evaluation code will be open-sourced to facilitate future research.
DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models
Jun 17, 2024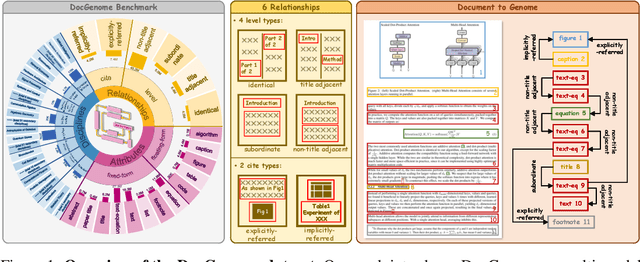
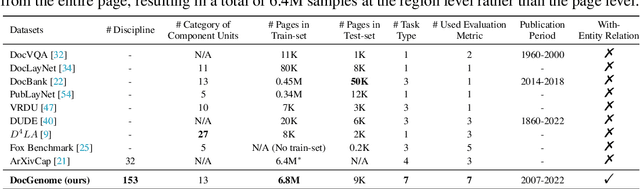
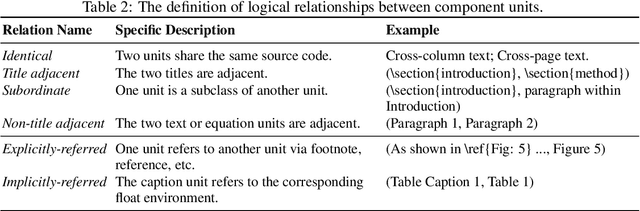
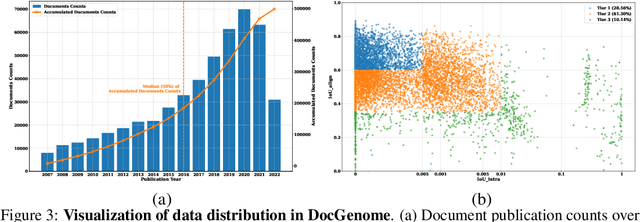
Scientific documents record research findings and valuable human knowledge, comprising a vast corpus of high-quality data. Leveraging multi-modality data extracted from these documents and assessing large models' abilities to handle scientific document-oriented tasks is therefore meaningful. Despite promising advancements, large models still perform poorly on multi-page scientific document extraction and understanding tasks, and their capacity to process within-document data formats such as charts and equations remains under-explored. To address these issues, we present DocGenome, a structured document benchmark constructed by annotating 500K scientific documents from 153 disciplines in the arXiv open-access community, using our custom auto-labeling pipeline. DocGenome features four key characteristics: 1) Completeness: It is the first dataset to structure data from all modalities including 13 layout attributes along with their LaTeX source codes. 2) Logicality: It provides 6 logical relationships between different entities within each scientific document. 3) Diversity: It covers various document-oriented tasks, including document classification, visual grounding, document layout detection, document transformation, open-ended single-page QA and multi-page QA. 4) Correctness: It undergoes rigorous quality control checks conducted by a specialized team. We conduct extensive experiments to demonstrate the advantages of DocGenome and objectively evaluate the performance of large models on our benchmark.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
Automatic Surround Camera Calibration Method in Road Scene for Self-driving Car
May 26, 2023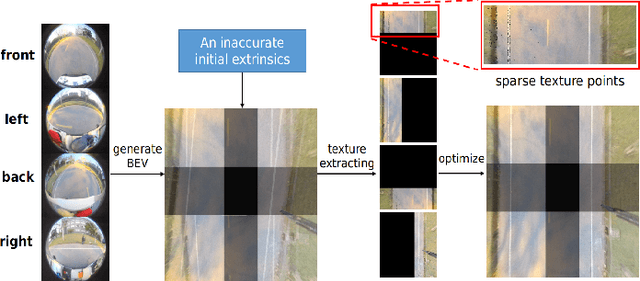


With the development of autonomous driving technology, sensor calibration has become a key technology to achieve accurate perception fusion and localization. Accurate calibration of the sensors ensures that each sensor can function properly and accurate information aggregation can be achieved. Among them, camera calibration based on surround view has received extensive attention. In autonomous driving applications, the calibration accuracy of the camera can directly affect the accuracy of perception and depth estimation. For online calibration of surround-view cameras, traditional feature extraction-based methods will suffer from strong distortion when the initial extrinsic parameters error is large, making these methods less robust and inaccurate. More existing methods use the sparse direct method to calibrate multi-cameras, which can ensure both accuracy and real-time performance and is theoretically achievable. However, this method requires a better initial value, and the initial estimate with a large error is often stuck in a local optimum. To this end, we introduce a robust automatic multi-cameras (pinhole or fisheye cameras) calibration and refinement method in the road scene. We utilize the coarse-to-fine random-search strategy, and it can solve large disturbances of initial extrinsic parameters, which can make up for falling into optimal local value in nonlinear optimization methods. In the end, quantitative and qualitative experiments are conducted in actual and simulated environments, and the result shows the proposed method can achieve accuracy and robustness performance. The open-source code is available at https://github.com/OpenCalib/SurroundCameraCalib.
An Extrinsic Calibration Method of a 3D-LiDAR and a Pose Sensor for Autonomous Driving
Sep 16, 2022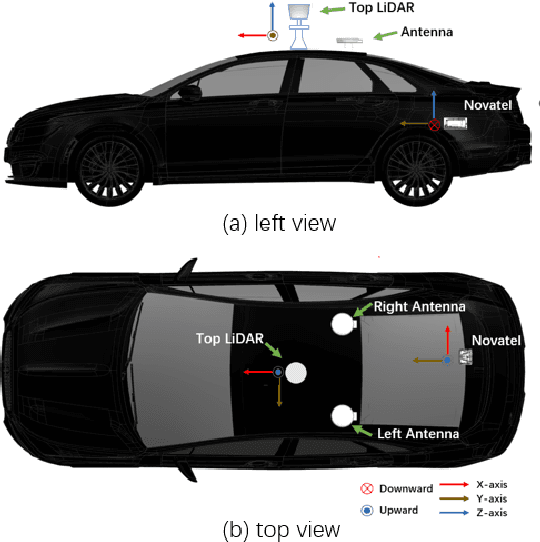
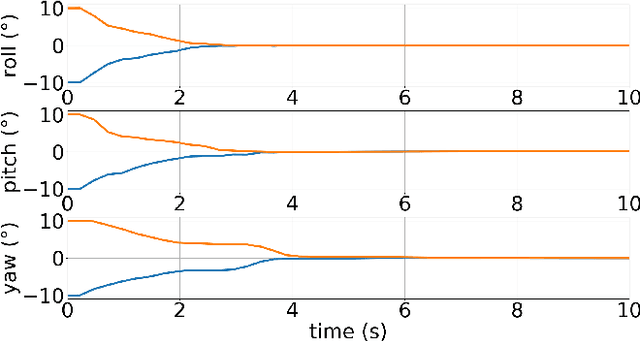
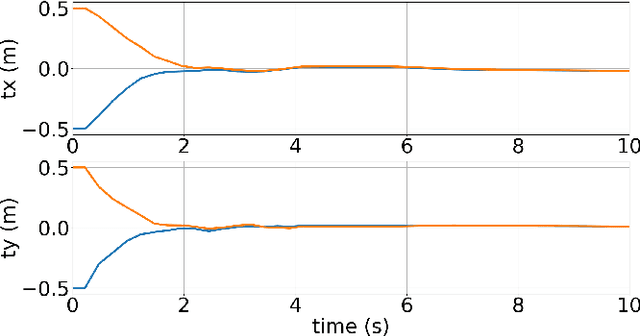
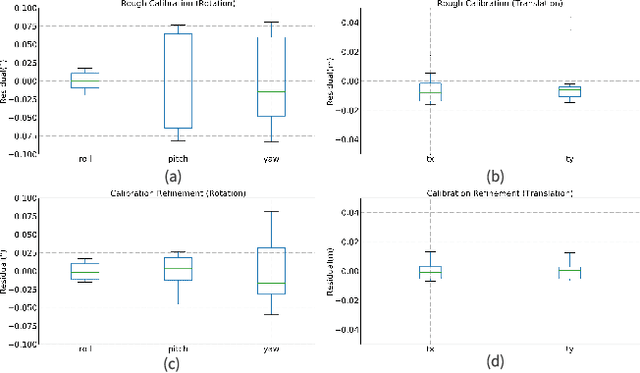
Accurate and reliable sensor calibration is critical for fusing LiDAR and inertial measurements in autonomous driving. This paper proposes a novel three-stage extrinsic calibration method of a 3D-LiDAR and a pose sensor for autonomous driving. The first stage can quickly calibrate the extrinsic parameters between the sensors through point cloud surface features so that the extrinsic can be narrowed from a large initial error to a small error range in little time. The second stage can further calibrate the extrinsic parameters based on LiDAR-mapping space occupancy while removing motion distortion. In the final stage, the z-axis errors caused by the plane motion of the autonomous vehicle are corrected, and an accurate extrinsic parameter is finally obtained. Specifically, This method utilizes the natural characteristics of road scenes, making it independent and easy to apply in large-scale conditions. Experimental results on real-world data sets demonstrate the reliability and accuracy of our method. The codes are open-sourced on the Github website. To the best of our knowledge, this is the first open-source code specifically designed for autonomous driving to calibrate LiDAR and pose-sensor extrinsic parameters. The code link is https://github.com/OpenCalib/LiDAR2INS.